 网站地图
网站地图





-
机载激光雷达(light detection and ranging, LiDAR)点云技术可以快速、准确地获取到高密度且高精度的真实3维城市模型,广泛应用于数字城市建设、地质勘测及灾害评估、3维导航等领域[1-5]。建筑物是地理环境中最主要、最基本的组成元素之一,基于机载LiDAR点云数据的建筑物3维模型重建也是当前研究的热点。屋顶作为建筑物模型中的重要组成元素,快速、准确的屋顶平面提取是进行屋顶建模的必要环节和关键步骤[6-8],屋顶平面的提取精度将直接影响最终的建模精度。由于不同类型建筑物屋顶形状各异且空间结构复杂,从建筑物屋顶LiDAR点云数据中进行准确有效的屋顶平面提取仍面临挑战。
传统的平面提取方法主要包括区域增长算法、模型拟合和聚类等方法。区域增长算法[5, 9]主要通过选取种子点、近邻点搜索以及生长条件进行平面提取。一般选择曲率较小的即较为平稳的区域中的点作为种子点进行区域增长。在近邻关系中,往往使用构建k-D树的方式来获取点之间的邻接关系。对于生长条件的选取,通常采用欧氏距离、法向量等具有几何性质的条件进行判定[10]。区域生长方法受生长规则的限制较大,容易出现过分割或欠分割的现象。为了提高分割的准确性,部分方法在基础的区域生长方法上进行了改进。WANG等人[11]在生长条件中加入了3-D点云的彩色信息使点云分割更加稳定。ZHU等人[12]提出一种以三角面为基元的基于区域生长算法对同一建筑物面片上各三角面进行初步划分,然后结合随机抽样一致(random sample consensus,RANSAC)完成建筑物屋顶的点云分割。
模型拟合的方法主要是基于3-D Hough变换算法[13]和RANSAC算法[14]。Hough变换是图像处理领域中常见的特征检测技术。在处理3维点云时,3-D Hough变换对于非平面噪声点具有一定的鲁棒性。但3-D Hough变换在将原始空间中的特征转化至参数空间时,随着参数量的增加,算法的复杂度也呈指数级的增长,从而耗费大量的时间和空间资源。为此,部分方法[15-17]通过降低投票成本的方式来降低计算成本。除此以外,针对3-D Hough变换面对复杂建筑物屋顶形状时可能伪平面的情况,KANG等人[18]提出了一种将尺度不变特征转换(scale invariant feature transform,SIFT)和3-D Hough变换相结合的方法,引入曲率以提高SIFT对复杂结构和离散点的识别,并拟合三角面将获取的法向量投入3-D Hough空间用于判断平面可靠性,降低伪平面的出现几率。RANSAC算法通过迭代估算出概率最大、点数最多的平面方程[19],这种方法对于噪声点的鲁棒性较高,非常适用于处理噪声点较多的大规模数据集。XU等人[20]提出了一种用于点云分割的加权RANSAC方法,将点平面距离和法向量一致性的硬阈值投票函数转换为基于两个权重函数的软阈值投票函数,并为正确和不正确的平面假设之间的误差分布设计了一个权重函数和异常值抑制,该加权方法可以显著地提高分割精度。LI等人[21]提出了一种多原重建方法,首先通过RANSAC将建筑分为平面面片,然后使用一组设计的指标从预定义的原始建筑类型中选择初始建筑分割的可能类型,最后使用3-D布尔运算从其组成基元中重建拓扑一致的3-D建筑模型。目前,基于RANSAC的方法被广泛应用于各类建筑物平面提取。但当平面结构较为复杂时,RANSAC算法的计算效率显著降低,且易产生伪平面。因此,RANSAC算法在面对较为复杂的场景时表现不佳。
基于聚类的方法通常是根据点云的特征(例如距离、法向量、颜色等),利用k均值、均值漂移等聚类方法从点云中提取平面[22]。显然这种方法依赖于固定的阈值和预定义的参数,对噪声和非平面内容非常敏感。除此以外,基于密度的聚类算法[23]也是一种非常常见的聚类算法。CHEN等人[24]提出了一种新的基于密度聚类算法(density-based spatial clustering of applications with noise, DBSCAN)的3维点云边界检测和平面分割方法,在DBSCAN的基础上引入了共面约束对3维空间中的候选样本和平面有效性进行选择和检测。由于建筑物屋顶类型多样且结构复杂,单一的聚类方法往往很难提取出准确且完整的屋顶平面。因此,传统的建筑物平面提取方法均存在一定的限制。
近年来,随着深度学习和3维点云在语义分割[25-28]、实例分割[29-30]等方面的广泛应用,尤其是部分点云分割方法的提出[31-32],使得深度学习在屋顶平面分割任务中的应用成为可能。目前,部分深度学习方法[33]多用于从单幅图像或多视角图像中重建3维建筑模型。ZHANG等人[34]提出了一个多任务网络,同时实现对3维屋顶平面提取的语义和实例预测,最后使用均值漂移算法生成最终的实例结果。在此基础上,受到点云实例分割方法的启发,本文中设计了一个简洁且有效的建筑物平面提取网络,首先使用PointNet + + 为每个点提取面实例级的深度特征,然后应用简单的距离约束对深度特征进行聚类以获得初始平面,最后对于未分配的点,通过简单的空间距离和深度特征距离进行综合度量和分配。
-
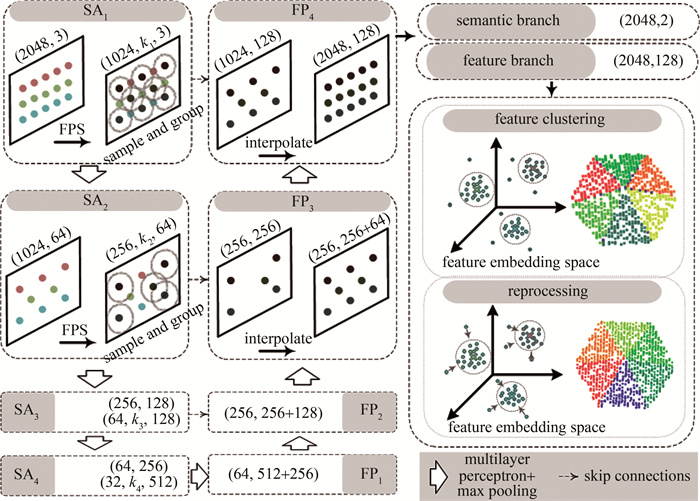
本文作者所提出的网络结构主要包括主干网络、特征聚类以及后处理3个部分,主干网络部分选择PointNet + +中的编码-解码部分为每个点生成高维的实例特征[26]。在输出层,增加一个语义分支用于区分平面内容和非平面内容。对于平面内容中不同面实例的点,通过一个简单的阈值在特征空间中进行聚类以获得初步的屋顶粗平面。通过简单的后处理将未分割的点逐步分配至初始平面,得到最终完整的单个屋顶平面。
-
PointNet + +是经典的3维点云分割网络,它在PointNet[25]的基础上提出了抽象集合(set abstraction, SA)模块和特征传播(feature propagation, FP)模块来聚合点的特征。为了获取不同屋顶面中点的高维深度特征,本文中使用了与PointNet + +中编码-解码网络相同层数的网络结构。如图 1左侧部分所示,该结构首先通过4个的SA模块对点云进行下采样和压缩,然后通过4个相同倍数的FP模块进行上采样以获得每个点的全局高维深度特征。其中,每个SA模块主要由采样层、分组层和PointNet特征提取层3个关键层组成。采样层使用最远点采样算法(farthest point sampling,FPS)从给定的点集中寻找距离其它点距离最远的子集。对于SA层大小为N′×(h+H)的输入点云,经过s倍最远点采样可以获得大小为N″×(h+H)的点云,其中N″=N′/s,h为3维坐标,H为特征维度。分组层则为采样后的子集N″在原始点集N′中寻找与之最近的ki个点进行组合。由此,经过分组层后,输出点集的大小为N″×ki×(h+H)。PointNet特征提取层则用于将每个采样点的局部领域特征进行融合,使其局部特征包含质心及质心邻域的特征。经过PointNet特征提取层后,每个SA模块的输、N″×H′,H′为该SA模块层所需提取的特征维度。FP模块则以局部高维特征和上一层之间的全局特征作为输入,通过最大池化或平均池化将局部信息与全局信息相结合形成全局的特征表示。
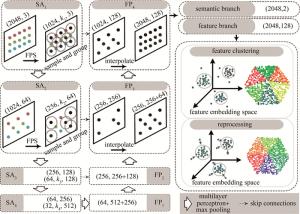
图 1 建筑物屋顶平面提取网络结构
Figure 1. Building roof plane extraction network structure
图 1中所用到的4个SA模块所设置的下采样倍数分别为2倍、8倍、32倍和64倍,对于每一层中的每一个采样点,所设置的近邻点数k1、k2、k3和k4均为16。每一层的输出特征维度分别为64、128、256和512。随后采用4个FP模块对所提取的局部特征与全局特征相融合。网络输出包含两个分支:一个分支为语义分支,该分支用于生成二分类分数,用于区分建筑物屋顶中的平面点和非平面点;另一个分支为特征分支,用于获取每个点的高维深度特征以便进行进一步的聚类和平面提取。
-
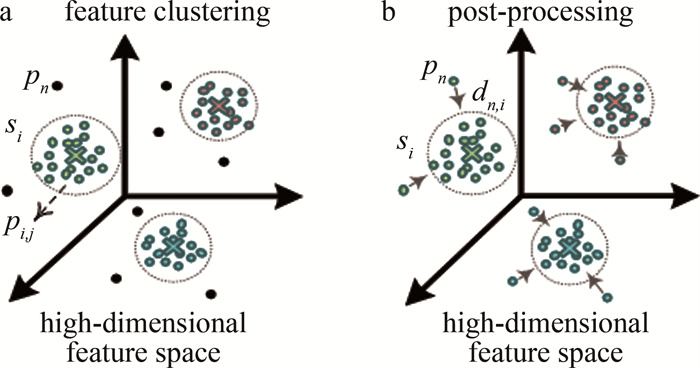
由于屋顶不同平面上点的深度特征区别较大,基于此,采用了PointGroup[32]中简单且有效的聚类方式,在深度特征上进行初步的聚类。该聚类方式的核心是:对于给定点q,将距离点q半径范围r内的平面点聚合到同一簇中,其中r为特征空间中的距离约束。即对于输入点云深度特征X={x1, x2, …, xN}∈RN×F,N为点数量,F为深度特征维数,通过聚类半径r和最小簇数量Nθ可以得到初步的聚类结果S={s1, s2, …, sM},M为特征聚类的簇数,sM表示聚类的第M个簇。该聚类算法的具体步骤如下:(a)初始化一个空的点集合s0;(b)随机选择一个未聚类的点pn1(n1∈[1, N]),将其加入集合s0;(c)逐个计算其它未聚类点pn2 (n1∈[1, N])与pn1之间的深度特征距离‖xn1-xn2‖2,其中n1≠n2;(d)若‖xn1-xn2‖2 < r, 则将点pn2加入集合S0;(e)重复步骤(a)~(d),直到所有点均被聚类进某一簇中;(f)判断每个集合si中点的数量是否大于Nθ,将点数量大于Nθ的集合保留,得到初步聚类结果S,其余簇中的点标记为未被聚类点。
通过该聚类算法可以得到初步的粗平面。由于存在Nθ的限制,使得小的聚类簇可以被删除并在后续后处理中进行重新分配,极大地降低了伪平面产生的可能。
-
如图 2a所示,经过特征聚类,可以得到初步的聚类结果S={s1, s2, …, sM}以及未被聚类至任一簇的点集P={p1, p2, …, pn},其中M为经过初步特征聚类的簇数,pn表示未被聚类的点,n为点数量。为了将这些未被聚类的点P={p1, p2, …, pn}逐渐分配至各个平面。对于簇si(i=1, …, M),对该簇中的点集Pi={pi, 1, pi, 2, …, pi, j}(j为簇si中点的个数)进行平面拟合,以获取初步的平面。然后计算未分配点pn至每个拟合平面的距离D={dn, 1, dn, 2, …, dn, i}(i=1, …, M),dn, i为第n个点到第i个簇的拟合平面的距离。选取距离最小的簇作为点pn最终所在的簇(或平面),如图 2b所示。
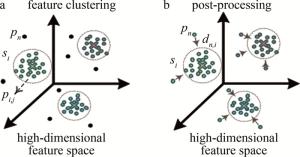
图 2 特征聚类及后处理
Figure 2. Feature clustering and post-processing
在平面拟合时,最常见的方法是最小二乘法和主成分分析法(principal components analysis, PCA)。最小二乘法通过最小化误差的平方来寻找数据的最佳函数匹配,但这种方法对数据中的异常值较为敏感。PCA通常用于降维,但也可以用于平面拟合。PCA通过计算协方差矩阵的特征向量来实现的。这种方法有助于过滤掉数据中的噪声,因为噪声通常表现为方差较小的成分。这对于平面拟合是有益的,因为它可以提高模型对真实数据结构的拟合程度。由于机载点云屋顶数据通常噪声多且分布不均匀,为了避免在上一步特征聚类中可能存在的错误的累计,本文中采用主成分分析法对每一簇中的点集Pi进行平面拟合。
对于XYZ坐标系下待拟合的点云,利用PCA可以得到特征值λ1、λ2、λ3(λ1>λ2>λ3)以及对应的向量ξ1,其中ξ1和ξ2为拟合平面的一组基,ξ3为拟合平面的法向量,且ξ3与ξ1和ξ2正交。利用PCA进行平面拟合的过程如下所示。
(a) 特征中心化。特征中心化需要将每一维的数据减去该维数据的均值,使每一维数据均值变为零。对于待拟合点集Pi,将特征中心化后的点集记为Pi ′,其中xn、yn、zn均为簇中点中心化后的坐标。
$ \boldsymbol{P}_i^{\prime}=\left[\begin{array}{ccc} x_1 & y_1 & z_1 \\ x_1 & y_2 & z_2 \\ \vdots & \vdots & \vdots \\ x_n & y_n & z_n \end{array}\right] $
(1) (b) 计算协方差矩阵C。
$ \boldsymbol{C}=\left[\begin{array}{lll} \operatorname{cov}(x, x) & \operatorname{cov}(x, y) & \operatorname{cov}(x, z) \\ \operatorname{cov}(y, x) & \operatorname{cov}(y, y) & \operatorname{cov}(y, z) \\ \operatorname{cov}(z, x) & \operatorname{cov}(z, y) & \operatorname{cov}(z, z) \end{array}\right] $
(2) 式中:cov(x, x)为x的方差;cov(x, y)为x和y的协方差。
(c) 计算协方差矩阵C的特征值λ1、λ2、λ3(λ1>λ2>λ3)和特征向量ξ1、ξ2、ξ3。显然,ξ1、ξ2为拟合平面的一组基,ξ3为拟合平面的法向量。假设ξ3的3个分量分别为a、b、c,则经过某一点p(xo, yo, zo)的拟合平面方程为:
$ a\left(x-x_0\right)+b\left(y-y_0\right)+c\left(z-z_0\right)=0 $
(3) 对于每一个簇si进行平面拟合可以得到多个平面及其对应平面方程,将每个平面方程的形式转化为Ax+By+Cz+D′=0,其中A=a,B=b,C=c,D′=-(axo+byo+czo)。未分配点集P={p1, …, pn}中每个点pn(xn, yn, zn)到每个平面的欧氏空间距离d′为:
$ d^{\prime}=\frac{\left|A x_n+B y_n+C z_n+D^{\prime}\right|}{\sqrt{A^2+B^2+C^2}} $
(4) 与此同时,还计算了待分配点pn的深度特征与每个簇的特征中心的距离d″:
$ d^{\prime \prime}=\left\|\mu_M-e_{p_n}\right\|_1 $
(5) 式中:μM为第M个簇的特征中心;epn为点pn的深度特征;‖·‖1表示L1距离。
最终,综合欧氏空间距离和特征距离,将点分配至综合距离最小的簇中。
$ d=\alpha \cdot d^{\prime}+\beta \cdot d^{\prime \prime} $
(6) 式中:α=1;β=1。
图 3显示了初步聚类以及后处理后的结果。图中黑色点为未被聚类至任一簇的点。经过后处理前,部分点未被分配至初始平面中,这些未被聚类的点通常为位于平面边缘的点。经过后处理后,这些边缘点被分配至最近的平面。

图 3 后处理前后效果对比
Figure 3. Comparison of the results before and after post-processing
-
本实验均基于Pytorch框架搭建的,实验硬件为:CPU为Intel Core i9-10900、Nvidia Geforce RTX3090。训练模型使所用的参数配置如表 1所示。
表 1 模型参数设置
Table 1. Model parameter settings
parameters value batch size 16 learning rate 10-3 iterate 150 input size 2048×3 目前开源的机载激光扫描(airborne laser scanning, ALS)点云数据集有瓦赫宁恩小镇(Vaihhingen 3D)、都柏林城市(DublinCity)、德国城市黑西格海姆(Hessigheim 3D)和屋顶数据集(RoofN3D)[35]等等。这些数据集来自于不同地区,且屋顶结构类型差异很大。但当前公开的数据集中,只有RoofN3D提供了不同的屋顶类型标注。除此以外,武汉大学发布了一个包含多种建筑物屋顶类型的合成数据集[36]用于深度学习平面提取任务。为此,本文作者在由武汉大学所发布的建筑物屋顶合成数据集和机载点云RoofN3D数据集上进行了训练和测试。
建筑物屋顶合成数据集共包含16种屋顶类型,如图 4所示。每种类型包含1000个训练样本和100个测试样本,共计17600个样本模型。由于棚和平层类型的屋顶仅包含一个平面,剔除了这两种类型的屋顶,对剩余的14种类型的屋顶进行了实验。

图 4 16种屋顶类型
Figure 4. 16 types of building roofs
RoofN3D是一个用于深度学习技术的建筑物3维重建数据集,该数据集为每个屋顶提供不同建筑类别(金字塔型屋顶、山墙屋顶和山坡型(屋脊形)屋顶),但不包含每种建筑物详细的平面标签。为了获取不同屋顶类型各个平面的标签,对该数据集中的不同屋顶类型按照约为1 ∶1 ∶1的比例,共计1000栋屋顶进行了人工标注用于训练,并采用了100栋屋顶进行测试。
由于建筑物屋顶合成数据集对于每种类型的屋顶数据较为全面,包含每种类型屋顶不同的倾斜度、不同平面大小的数据。因此,使用该数据集进行训练时没有进行额外的数据增强操作。对于每一个屋顶样本,仅需对数据进行归一化操作。RoofN3D数据集的屋顶类型较少,但该数据集包含较多噪声。因此使用该数据集进行训练时未进行额外的添加噪声、抖动等数据增强处理。同时,由于所提出的方法可以有效地区分建筑物屋顶平面内容和非平面内容(噪声点),训练前无需对带噪声数据进行去噪预处理,可以直接用于网络训练及平面提取。
-
为了验证所提出的方法的准确性,对于平面提取任务,本文作者在实例级和点级分别使用了不同的指标进行评价。在每个实例面水平上,本文中采用覆盖率和加权覆盖率[37-39]两个指标进行评价。其中,覆盖率是预测实例面与真实实例面相匹配的平均实例级交并比(intersection over union,IoU)。加权覆盖率则是覆盖率分数进一步根据真实实例面的大小进行加权所得。对于真实平面区域U和预测出来的平面区域V,其覆盖率和加权覆盖率计算方式如下:
$ C(U, V)=\sum\limits_{o=1}^{|U|} \frac{1}{|U|} \max _m I\left(U_o, V_m\right) $
(7) $ W(U, V)=\sum\limits_{o=1}^{|U|} w_o \max _m I\left(U_o, V_m\right) $
(8) $ w_o=\frac{\left|U_o\right|}{\sum\limits_g\left|U_g\right|} $
(9) 式中:|Uo|是真实平面o中点的个数;|Vm|是预测平面m中点的个数;$\max _m I(\cdot) $是真实平面与预测平面相匹配的最大IoU值;g为屋顶样本中的真实平面数;wo计算了每个平面点数占总屋顶点数的比例,反映了每个平面相对于屋顶的区域大小。
在点水平上,本文中采用准确率P′、召回率R和F1分数进行评价,计算公式如下:
$ P^{\prime}=\frac{T}{T+F_{\mathrm{n}}} $
(10) $ R=\frac{T}{T+F_{\mathrm{p}}} $
(11) $ F_1=2 \frac{P^{\prime} R}{P^{\prime}+R} $
(12) 式中:T为预测正确的点数;Fp为存在于某个平面中但被预测为其它平面的点数;Fn为预测出来的真实标签不存在的平面点数。
在以上实例级和点级水平的指标中,覆盖率和平均覆盖率采用了点云实例分割中的思想,将每一个平面考虑为单独的实例,从单个实例平面的角度考虑了预测平面与真实实例平面间的覆盖程度(即IoU)。而在点集水平指标中,将每一个屋顶视为一个单独的样本,计算了整个屋顶中的预测正确(true positive,TP)或预测错误(false negative,FN;false positive,FP)的点数量。从单个屋顶数据中衡量了所提出方法平面提取的准确性。
-
为了获取能够区分不同平面的每个点的高维深度特征,借助点云实例分割中的思想,使用歧视性损失[40]ld对主干网络进行训练。ld主要包括lc、la和lr 3个部分,具体计算方式如下:
$ l_{\mathrm{d}}=\varepsilon \cdot l_{\mathrm{c}}+\delta \cdot l_{\mathrm{a}}+\gamma \cdot l_{\mathrm{r}} $
(13) $ l_c=\frac{1}{K} \sum\limits_{\kappa=1}^K \frac{1}{N_\kappa} \sum\limits_t^{N_\kappa}\left[\left\|e_\kappa-o_t\right\|_1-\sigma_1\right]_{+}^2 $
(14) $ \begin{gathered} l_{\mathrm{a}}=\frac{1}{K(K-1)} \sum\limits_{\kappa_A=1}^K \sum\limits_{\kappa_B=1}^K\left[2 \sigma_2-\left\|e_{\kappa_A}-e_{\kappa_B}\right\|_1\right]_{+}^2, \\ \left(\kappa_A \neq \kappa_B\right) \end{gathered} $
(15) $ l_{\mathrm{r}}=\frac{1}{K} \sum\limits_{\kappa=1}^K\left\|e_\kappa\right\|_1 $
(16) 式中:lc是一种引力损失,旨在使同一实例的特征聚往特征中心,即使得相同实例的特征更加接近;la是一种推力损失,旨在使不同实例的特征中心分离;lr是一个正则项,旨在为所有实例特征值形成一个约束;Κ代表面实例个数;Nκ为第κ个实例面的点的数量;eκ为第κ个面实例的特征中心;ot表示第t个点的特征;σ1和σ2则分别是引力和推力的特征阈值;κA、κB分别表示1~Κ中任意两个不同的面实例;eκA、eκB则分别为这两个面实例的特征中心;[x]+=max(0, x)。根据参考文献[39],通常选取常数ε=δ=1, γ=0.001。
利用该损失函数进行训练,将每个屋顶面视为一个单独的面实例得到点级的深度学习特征,该特征表现为同一屋顶平面上的点在高维特征中非常相近,而不同屋顶平面上的点特征距离较远。除此以外,对于存在噪声或非建筑物平面的屋顶数据,可以加入额外的语义标签(通常设定平面点为1,非平面点或噪声点为0)对网络进行训练,使网络可以在提取高维度深度特征的同时,利用语义分支对非建筑物平面内容进行区分。
在对整个网络进行训练时,仅对主干网络部分进行训练用于获取高维特征。特征聚类及后处理部分仅用于对高维特征进行聚类和分配,不参与网络的训练过程。
-
本文作者在合成数据集上进行了消融研究来验证在聚类部分的参数选择。在聚类算法中使用了不同的聚类半径r值,其性能的变化如表 2所示。当聚类半径较小时,聚类效果对点特征密度较为敏感。当聚类半径较大时容易使不同的实例聚为一个。为此,根据经验将r值设为0.6。
表 2 不同聚类半径对分割精度的影响
Table 2. Effect of different clustering radius on segmentation accuracy
clustering radius r coverage weighted coverage precision recall F1-score 0.4 0.9597 0.9775 0.9897 0.9965 0.9930 0.5 0.9618 0.9786 0.9901 0.9972 0.9836 0.6 0.9626 0.9791 0.9900 0.9982 0.9940 0.7 0.9620 0.9785 0.9895 0.9982 0.9938 -
图 5显示了本文中提出的方法在合成数据集上的可视化平面提取结果。实验结果表明,对于不同类型的建筑物屋顶,该方法可以有效地提取出各个实例平面,其提取出的平面不受平面本身大小、形状和位置的限制。当某个屋顶平面上存在较小的平面时,所提出的方法仍可以将每个小平面准确地提取出来。在面对较为弯曲、边缘变化不明显的多个平面时,所提出的方法也可以进行准确的分割。除此以外,所提出的方法在平面边缘表现良好,不易存在过分割或欠分割的现象。

图 5 合成数据集各屋顶平面提取结果
Figure 5. Extraction results for each roof plane of the synthetic dataset
表 3为本文中提出的方法在合成数据集上的各指标精度。从表 3可以看出,本文中提出的分割模型在实例水平各指标均高于0.9626,说明所提出的方法对不同类型的屋顶平面均可以进行有效的提取。除此以外,在点水平上,各指标均高于0.9900,证明本方法所提取出的平面精度较高。
表 3 不同方法在合成数据集上的分割结果
Table 3. Segmentation results of different methods on synthetic datasets
除此以外,还实验对比了传统的方法RANSAC[41]、区域增长[42]以及深度学习实例分割方法PointGroup[31]。与这些方法相比,在实例级别上,所提出的方法在覆盖率上分别提高了0.2003、0.1599、0.1412,在加权覆盖率上分别提高了0.1886、0.1496、0.1083。在点水平上,所提出的方法在准确率、召回率和F1分数上分别提高了0.1155、0.0171、0.0627以上。由此可见,本文中的方法不仅可以在不同类型屋顶上提取出各个平面,不易产生伪平面,而且提取出的单个平面非常准确,在平面边缘也表现良好。
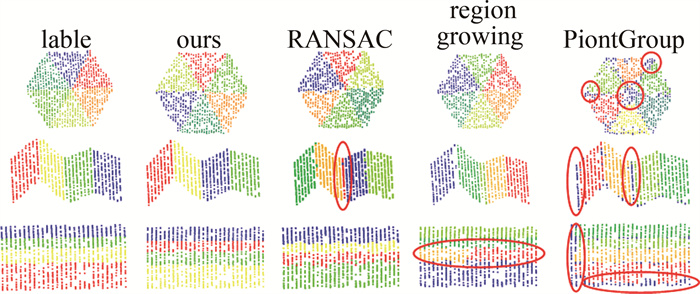
图 6分别展示了本文中方法、RANSAC、区域增长和PointGroup在合成数据集上部分类型屋顶上的平面提取效果。从分割结果来看,RANSAC方法提取平面时受法向量的影响,在平面边缘处表现不佳。区域增长方法可以准确提取多个平面,但当两个平面间的连接处较为平滑时,受法向量和曲率的影响,会导致伪平面的产生。同时,区域增长可能会将不平整的单个平面分割为多个小平面。PointGroup可以准确地预测各个平面,但在聚类时主要通过空间中的偏移进行约束,对于边缘处的点无法很好地聚类至单个平面中。相比较上述3种方法,本文中提出的方法在特征空间中进行聚类,在平面曲率变化明显、平面点密度不均匀的情况时也不易产生伪平面的现象。同时,经过后处理步骤,未被聚类的点被逐步分配至最近平面,极大地降低了边缘被错误分割或被单独分割成小平面的概率,使得平面边缘提取较为准确。
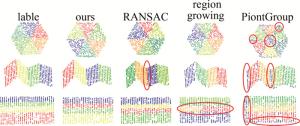
图 6 不同方法在合成数据集上的平面提取结果
Figure 6. Plane extraction results of different methods on synthetic datasets
-
图 7为本文中提出的平面提取方法在RoofN3D数据集上对3种不同屋顶类型的可视化平面提取结果。其中蓝色点为非平面点(噪声点),其它颜色分别代表不同的平面。由实验结果可见,所提出的方法在该数据集上表现良好,不仅可以有效提取出屋顶平面,还可以准确区分出非建筑物平面内容。因此,使用本文中提出的方法进行建筑物平面提取时,不需要对数据进行额外的预处理步骤就可以准确提取出建筑物屋顶部分和各个平面。

图 7 本文中的方法在RoofN3D数据集上的平面提取结果
Figure 7. Plane extraction results of the proposed method on RoofN3D dataset
表 4分别展示了本文中方法、RANSAC、区域增长和PointGroup在RoofN3D数据集上的平面提取效果。与另外3种方法性相比,本文中提出的方法在实例级上有明显的提升,说明该方法对平面提取更为准确,不易有伪平面的产生。
表 4 不同方法在RoofN3D数据集上的分割结果
Table 4. Segmentation results of different methods on RoofN3D datasets
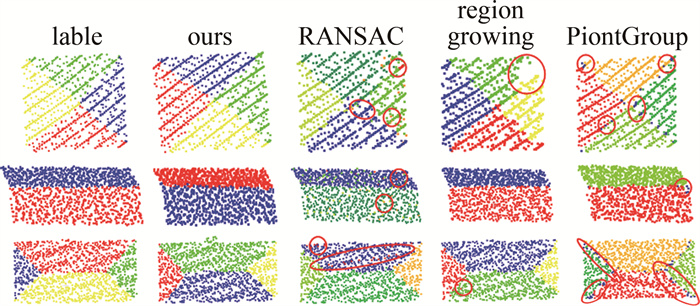
methods instance-level point-level coverage weighted coverage precision recall F1-score RANSAC 0.6331 0.7555 0.8230 0.9715 0.8883 region growing 0.6212 0.7345 0.7952 0.9510 0.8633 PointGroup 0.8082 0.8156 0.8486 0.9989 0.9090 our work 0.8757 0.8801 0.9453 0.9708 0.9573 图 8分别展示了本文中方法、RANSAC、区域增长和PointGroup在RoofN3D数据集上平面提取效果。从实验结果可以看出,RANSAC方法在面对不平整的平面时,对部分凸出平面的点较为敏感,所提取的平面不够完整,且边缘不够准确。区域增长方法由于边缘点对曲率较为敏感,在平面边缘表现较差,部分点未被分配至任意平面中,导致了不完整的平面提取结果。PointGroup可以准确地提取各个平面,但在平面边缘表现较差,部分边缘点未被聚类至任一平面中。本文中提出的方法在不同屋顶类型上分割效果良好,边缘较为准确,基本无过分割或欠分割的现象。

图 8 不同方法在RoofN3D数据集上的平面提取结果
Figure 8. Plane extraction results of different methods on RoofN3D dataset
综上所述,本文中提出的方法无论在合成数据集还是机载点云屋顶数据集RoofN3D上,对各种类型屋顶平面的平面提取效果良好;相比于其它传统的平面提取方法和深度学习实例分割方法,该方法各个指标更高且分割效果更好。由此说明,本文中提出的方法不仅可以自动区分非建筑物平面内容,还可以准确提取建筑物屋顶各个平面,可为建筑物3维重建提供重要帮助。
-
针对传统建筑物平面分割任务中效果不佳的问题,本文作者提出了一种基于深度学习的点云平面提取方法用于机载LiDAR点云数据的建筑物屋顶平面提取。首先通过深度学习的方式,为建筑物屋顶的每个平面点提取不同的深度特征,然后利用所提取的深度特征在特征空间上进行聚类,最后通过后处理将未聚类点分配至各个初始平面得到最终的平面提取结果。实验结果表明,面对不同类型的建筑物屋顶,所提出的方法不仅可以区分非屋顶平面内容,还可准确有效地提取出各个平面,并且经过后处理步骤,可以准确分割各个平面边缘。与传统的建筑物平面分割方法相比,所提出的方法在分割结果的完整性和准确性方面都有明显的提高。后续工作将结合建筑物屋顶机载LiDAR点云数据的语义信息和平面边缘信息实现更加精确的分割,为进一步实现建筑物的3维重建做准备。
基于深度学习的机载点云屋顶平面提取算法
An airborne point cloud roof plane extraction algorithm based on deep learning
-
摘要: 为了准确提取不同类型建筑物屋顶点云的各个平面,采用度量学习的方式,将每个平面视为单独的实例,为每个平面上的点学习单独的高维深度特征。利用所提取的高维深度特征对平面点进行初步的聚类,通过简单的欧氏距离和特征空间距离进行综合度量将未聚类的点分配至各个平面;所提出的方法分别在合成数据集和公开的机载点云建筑物屋顶数据集RoofN3D上进行了训练和测试。结果表明,在合成数据集上,所提取的建筑物平面的准确率、召回率和F1分数分别为0.990、0.998和0.994;在机载点云数据集RoofN3D上,所提取的建筑物平面的准确率、召回率和F1分数分别为0.945、0.971和0.957。该方法不仅可以准确有效地提取出不同建筑物屋顶平面,且平面边缘非常准确,还可以准确区分建筑物屋顶平面内容和非平面内容,为建筑物3维建模提供重要帮助。Abstract: In order to accurately extract the individual planes from various types of building roof point clouds, metric learning was used to learn separate high-dimensional depth features for the points on each plane, and each plane was considered as a separate instance. Then the extracted high-dimensional depth features were used to perform preliminary clustering of the plane points. The unclustered points were assigned to each plane by a combined metric of simple Euclidean distance and feature space distance. The proposed method was trained and tested on a synthetic dataset and the publicly available airborne point cloud building roof dataset RoofN3D, respectively. The results show that on the synthetic dataset, the accuracy, recall, and F1 scores of the extracted building planes are 0.990, 0.998, and 0.994, respectively. On the airborne point cloud dataset RoofN3D, the accuracy, recall, and F1 scores of the extracted building planes are 0.945, 0.971, and 0.957, respectively. The proposed method not only can accurately and effectively extract different building roof planes, but also the extracted plane edges are very accurate. In addition, the method can also accurately distinguish between the planar and non-planar contents of building roofs, which provides important help for further 3-D modeling of buildings.
-
图 5 合成数据集各屋顶平面提取结果
Figure 5. Extraction results for each roof plane of the synthetic dataset
图 6 不同方法在合成数据集上的平面提取结果
Figure 6. Plane extraction results of different methods on synthetic datasets
图 7 本文中的方法在RoofN3D数据集上的平面提取结果
Figure 7. Plane extraction results of the proposed method on RoofN3D dataset
图 8 不同方法在RoofN3D数据集上的平面提取结果
Figure 8. Plane extraction results of different methods on RoofN3D dataset
表 1 模型参数设置
Table 1. Model parameter settings
parameters value batch size 16 learning rate 10-3 iterate 150 input size 2048×3  下载: 导出CSV
下载: 导出CSV
表 2 不同聚类半径对分割精度的影响
Table 2. Effect of different clustering radius on segmentation accuracy
clustering radius r coverage weighted coverage precision recall F1-score 0.4 0.9597 0.9775 0.9897 0.9965 0.9930 0.5 0.9618 0.9786 0.9901 0.9972 0.9836 0.6 0.9626 0.9791 0.9900 0.9982 0.9940 0.7 0.9620 0.9785 0.9895 0.9982 0.9938
下载: 导出CSV
表 3 不同方法在合成数据集上的分割结果
Table 3. Segmentation results of different methods on synthetic datasets
下载: 导出CSV
表 4 不同方法在RoofN3D数据集上的分割结果
Table 4. Segmentation results of different methods on RoofN3D datasets
methods instance-level point-level coverage weighted coverage precision recall F1-score RANSAC 0.6331 0.7555 0.8230 0.9715 0.8883 region growing 0.6212 0.7345 0.7952 0.9510 0.8633 PointGroup 0.8082 0.8156 0.8486 0.9989 0.9090 our work 0.8757 0.8801 0.9453 0.9708 0.9573
下载: 导出CSV
-
-
 点击查看大图
点击查看大图
计量
- 文章访问数: 1434
- HTML全文浏览量: 67
- PDF下载量: 1
- 被引次数: 0
