 网站地图
网站地图



-
每年我国在水果采摘方面消耗大量的人力物力,人工智能的迅速发展使得机器人采摘水果成为可能[1-4],其中水果图像识别在水果机器人采摘技术中占据重要地位,识别精度的高低代表着能否实现对水果的精准采摘。因此,研究水果图像识别对水果自动化采摘具有重大意义。
传统水果图像识别技术多数利用一些水果的颜色、纹理、形状特征去定位水果区域。例如SUN等人[5]利用信息最大化(attention-based information maximization,AIM)算法粗略定位绿苹果区域, 随后通过融合光照不变图像和被裁剪图像的R分量, 精确定位绿苹果区域,准确率达到86.91%。YU等人[6]利用彩色深度(red-green-blue depth,RGB-D)相机采集荔枝图像,在随机森林二元分类模型中引入多尺度检测和非极大值抑制算法,识别荔枝准确率为89.92%。WU等人[7]提出了一种结合颜色和几何特征的水果分割方法, 利用水果像素特征粗分割,然后利用点云簇的视点特征直方图(viewpoint feature histogram,VFH)精分割水果区域,该方法精准度为80.09%。
以上传统技术受环境复杂性影响,只能考虑某一种水果的特点,没有设计出适用性广泛的特征提取模型,同时也无法满足水果识别实时性。近年,具有非线性表达能力强、泛化性能好等优点的深度学习开始进入研究者们的视野[8]。DONG等人[9]利用带有卷积神经网络特征的区域模型(regions with convolutional neural network features,RCNN)设计出一种水果抓取机器人。ZHAI等人[10]改进经典卷积模型将全连接替换为归一化指数函数softmax,从而实现对水果的分类,但这两个模型只有少量的特征提取层,很大程度上限制其水果图像特征提取的能力,仅在简单的背景下识别率高。HUANG等人[11]提出一种改进的残差网络用于水果检测,在此基础上添加多尺度采样层进行特征提取,缺点在于数据集图像背景简单,没有进一步检测复杂背景下的水果。PENG等人[12]提出一种改进单发多盒探测器模型(single shot multibox detector,SSD)模型用于水果识别,将视觉几何组结构(visual geometry group,VGG)VGG-16替换为残差网络(residual network,ResNet)ResNet-101结构,并运用随机梯度下降法(stochastic gradient descent,SGD)方法优化模型,检测速度快,平均精度提升至88.6%,但SSD模型缺少特征融合,水果特征提取较少,识别率较差。WANG等人[13]提出一种改进的你只用看一遍(you only look once,YOLO)统一框架的实时目标检测YOLOv3水果识别模型, 用组归一化层(group normalization,GN)替换批归一化层(batch normalization,BN)方法,优化运算参数,但是YOLOv3中特征金字塔网络(feature pyramid networks,FPNet)特征融合效果较差,不能充分提取到水果特征,平均识别率仅为85.91%。
经分析可知,以上的水果检测方法都存在一定的缺陷,识别率低或检测速度不满足实时性,因此本文作者针对识别率低和实时性问题提出一种改进的YOLOv4模型,通过对主干网络结构修改以及加入内卷算子, 以此提高水果识别的精度及其鲁棒性,为水果识别技术提供一定的思路。
-
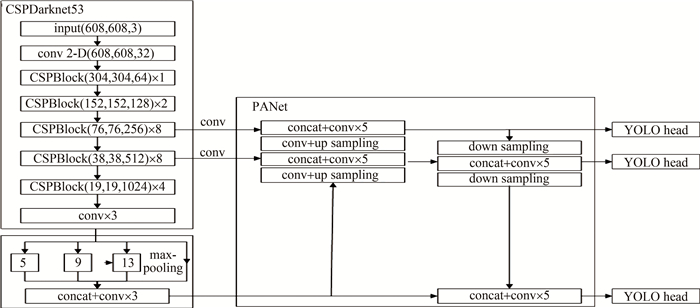
YOLOv4参考跨级局部网络(cross stage partial network,CSPNet)的思想,在YOLOv3的基础上使用特征学习效果更强的交叉跨级局部网络(cross stage partial darknet,CSPDarknet) CSPDarknet53作为主干网络。CSPDarknet53主干网络输出3个特征图,以此保证提取图像信息完备。空间金字塔池化(spatial pyramid pooling,SPP)对特征图进行堆叠、卷积,目的是扩大视觉感受野有利于全局检测。路径聚合网络(path aggregation network,PANet)将特征图进行上下采样,以此来融合提取到的图像信息。最后YOLOv4生成3个检测头head去检测目标。YOLOv4结构如图 1所示[14],图中conv代表卷积层,concat代表拼接,conv 2-D代表 2维卷积层。
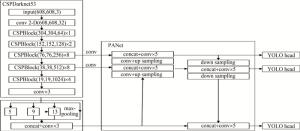
图 1 YOLOv4网络框架
Figure 1. YOLOv4 network framework
-
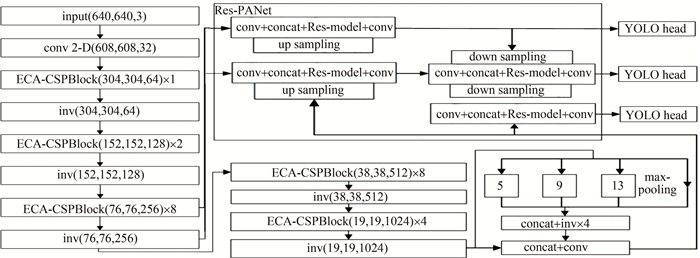
本文中基于YOLOv4算法进行改进,提出如图 2的网络架构模型,图中, Res-model表示借助ResNet结构设计的网络,inv代表内卷算子。主要改进工作由以下三部分组成:(1)主干特征网络。在CSPDarknet53中添加高效通道注意力(efficient channel attention,ECA),增强网络特征提取能力; (2)内卷算子。将主干网络中跨级局部模块(cross stage partial block,CSPBlock)连接处卷积层用内卷算子替换,可以减少参数量,使得模型更快地学习图像特征; (3)特征融合网络。在PANet基础上加入残差模块,组成基于残差的路径聚合网络(residual path aggregation network,Res-PANet),防止网络退化,提升网络性能。
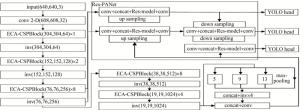
图 2 改进YOLOv4网络框架
Figure 2. Improved YOLOv4 network framework
-
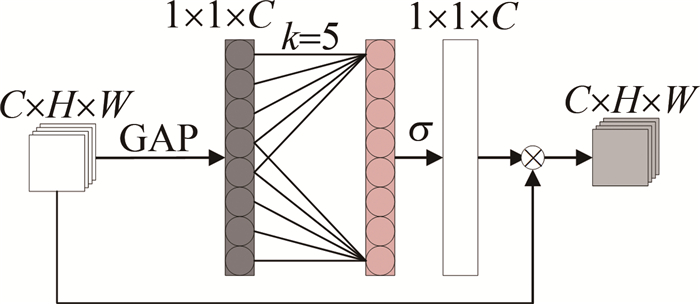
研究者们发现, 添加注意力机制能够使网络专注提取图像结构信息和语义信息。高效通道注意网络(efficient channel attention networks,ECANet)通过使用不降低通道维度的跨通道交互策略以及自适应选择1维卷积核大小的方法,极大提高了模型学习注意力的性能。图 3为ECA模块示意图。图中, C、H和W分别为输入通道数、输入图片高度和输入图片宽度,GAP(global average pooling)为平均全局池化。
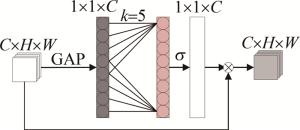
图 3 ECA模块
Figure 3. ECA module
不降维的局部跨信道交互策略可以通过非线性自适应1维卷积有效地实现,如下式所示:
$ w=\sigma\left(C_k(y)\right) $
(1) 式中,w为权重; σ(·)表示非线性映射关系; Ck(y)为通道数的1维卷积,它只涉及k个参数信息; y为输入。
下式给出了ECA注意力机制自适应确定k的方法:
$ k={\mathit{\Psi}}(C)=|\operatorname{lb}(C) / \gamma+b / \gamma|_{\text {odd }} $
(2) 式中,Ψ(C)表示对通道数C进行线性映射关系;k为内核大小,表示跨通道交互的区域,即有多少个相近邻参与一个通道的注意力预测[15];|·|odd表示最近邻奇数;γ为线性映射的斜率,取值为2;b为线性映射的截距,取值为1。
-
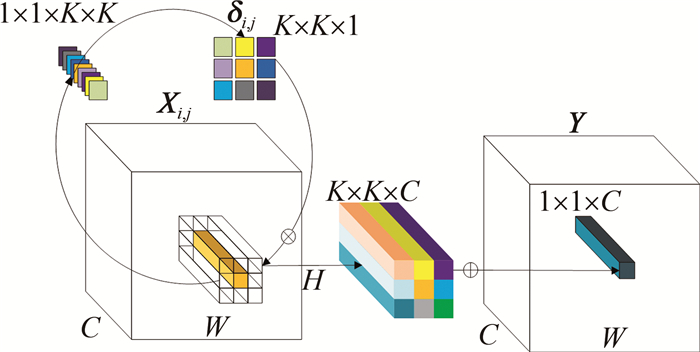
卷积在神经网络中产生便利的同时也存在缺点。首先,卷积核的共用会导致在不同空间位置上卷积核无法灵活建模。其次,由于通道数数百甚至上千,为减少参数量,卷积核一般使用3×3大小,但这限制了卷积在空间上获得长距离特征信息的性能。再者,卷积内部存在通道间冗余问题。研究者们基于卷积的缺点提出来的一种新型神经网络算子——内卷算子[16]。内卷算子在通道上共享同一内核,在空间维度采用不同的内核。在进行网络运算时内卷算子的输出特征映射为:
$ \boldsymbol{Y}_{i, j, p}=\sum\limits_{(u, v) \in \Delta \mathit{\Omega }} \boldsymbol{\delta}_{i, j, u+\lfloor K / 2\rfloor, v+\lfloor K / 2\rfloor, \lceil p G / C\urcorner} \boldsymbol{X}_{i+u, j+v, p} $
(3) 式中,1≤i≤H,1≤j≤W为空间位置索引; p为比例系数,取为1, 2, …, G; G表示所有通道共享组数; Xi+u, j+v, p为输入特征映射; Yi, j, p为输出特征映射; $\boldsymbol{\delta}_{i, j, u+\lfloor K / 2\rfloor, v+\lfloor K / 2\rfloor, \lceil p G / C\rceil} \in {\bf{R}}^{H \times W \times K \times K \times G}$是维度大小为H×W×K×K×G的内卷算子内核向量; R是实数集; (u, v)为滑动窗口中心点坐标; $u+\lfloor K / 2\rfloor, v+\lfloor K / 2\rfloor$表示内核滑动窗口大小; $\lceil p G / C\rceil$表示在一个通道上共享组数; K为内卷算子内核大小; ΔΩ表示考虑对位置(i, j)卷积的邻域偏移集,ΔΩ记为:
$ \begin{aligned} \Delta {\mathit{\Omega}} & =[-\lfloor K / 2\rfloor, -\lfloor K / 2\rfloor+1, \cdots, \lfloor K / 2\rfloor] * \\ & {[-\lfloor K / 2\rfloor, -\lfloor K / 2\rfloor+1, \cdots, \lfloor K / 2\rfloor] } \end{aligned} $
(4) 式中,$\lceil\rceil$表示取大于等于符号内数的最小整数,$\lfloor\rfloor$表示取小于等于符号内数的最大整数。
内卷算子内核的通用形式如下式所示:
$ \boldsymbol{\delta}_{i, j}=\phi\left(\boldsymbol{X}_{{\mathit{\Psi}}_{i, j}}\right) $
(5) 式中,Ψi, j是坐标邻域的集合,XΨi, j为光谱特征向量, ϕ(·)是核生成函数,当取其为{(i, j)}集合时,可以得到内核的一种简单形式,如下式所示:
$ \boldsymbol{\delta}_{i, j}=\phi\left(\boldsymbol{X}_{i, j}\right)=\boldsymbol{W}_1 \theta\left(\boldsymbol{W}_0 \boldsymbol{X}_{i, j}\right) $
(6) 式中,Xi, j代表像素点位置(i, j)的输入特征图,W0∈${\bf{R}}^{\frac{C}{r} \times C}$和$\boldsymbol{W}_1 \in {\bf{R}}^{(K \times K \times G) \times \frac{C}{r}}$,是一种线性的变换矩阵,r是通道缩减比率,θ(·)是批处理归一化后的非线性激活函数。
完整的内卷算子示意图如图 4所示,其中Y为输出特征图。
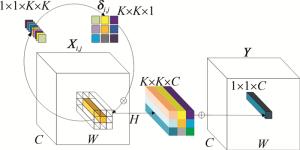
图 4 内卷算子示意图
Figure 4. Schematic diagram of involution
-
通常情况下,图像的结构信息和语义信息在不同的特征图中,两者在网络的传输过程中很难得到平衡[17]。PANet先进行上采样,接着进行下采样,目的是将深层的语义信息向浅层网络传输,将其结构信息与特征结合起来。尽管这样操作有很好的融合效果,但由于深层网络在更新过程中可能会累积误差梯度,并最终累积成非常大的梯度,进而会产生梯度爆炸等现象,所以会导致网络不稳定,影响网络的学习以及权重的更新。
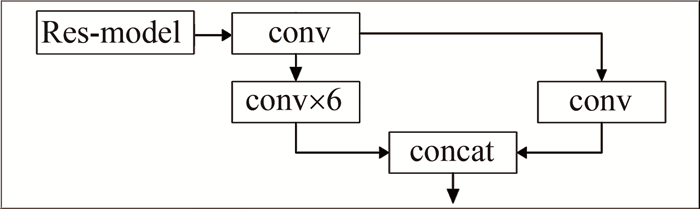
本文作者在YOLOv4主干网络中加入ECA注意力机制,能够在特征提取运算时保留更多的语义信息,进而提升网络性能,又将跨级局部模块(cross stage partial block,CSPBlock)过渡处的卷积层替换成内卷算子层,在保持性能不变的情况下减少了因卷积产生的冗余参数量,最后在PANet中融合残差模块,在内部残差块使用卷积跳跃连接,1层卷积作为残差边,6层卷积作为直接映射边,两者进行拼接作为输出,在提升网络稳定的同时也消除了由于加大网络深度而会带来的梯度消失问题。Res-model模块如图 5所示。

图 5 Res-model模块
Figure 5. Res-model module
-
本实验训练中所用的实验平台设备配置为Tesla V100 CPU,内存为32 GB,测试实验平台设备配置为Intel(R) Core(TM) i7-11700K。
-
本实验的数据集是在室内拍摄的10类水果, 包括火龙果、杏、荔枝、菠萝、猕猴桃、橙子、葡萄、樱桃、草莓、青芒等。每类600张,共6670张。将6670张数据集随机分6000张训练集和670张测试集, 数据集如图 6所示。

图 6 水果数据集
Figure 6. Fruit dataset
-
模型性能评价标准采用精确率Pr、召回率Re以及平均精度[18],Pr和Re的计算公式如下所示:
$ \begin{aligned} P_{\mathrm{r}}=T_{\mathrm{p}} /\left(T_{\mathrm{p}}+F_{\mathrm{p}}\right) \end{aligned} $
(7) $ R_{\mathrm{e}}=T_{\mathrm{p}} /\left(T_{\mathrm{p}}+F_{\mathrm{n}}\right) $
(8) 式中,Tp为真正例,Fp为假正例,Fn为假负例。
平均精度(average precision, AP)是训练出来的模型在每个类别上的识别精度,MAP(mean average precision)表示AP值求平均,MAP越接近于1代表网络性能越好[19]。
-
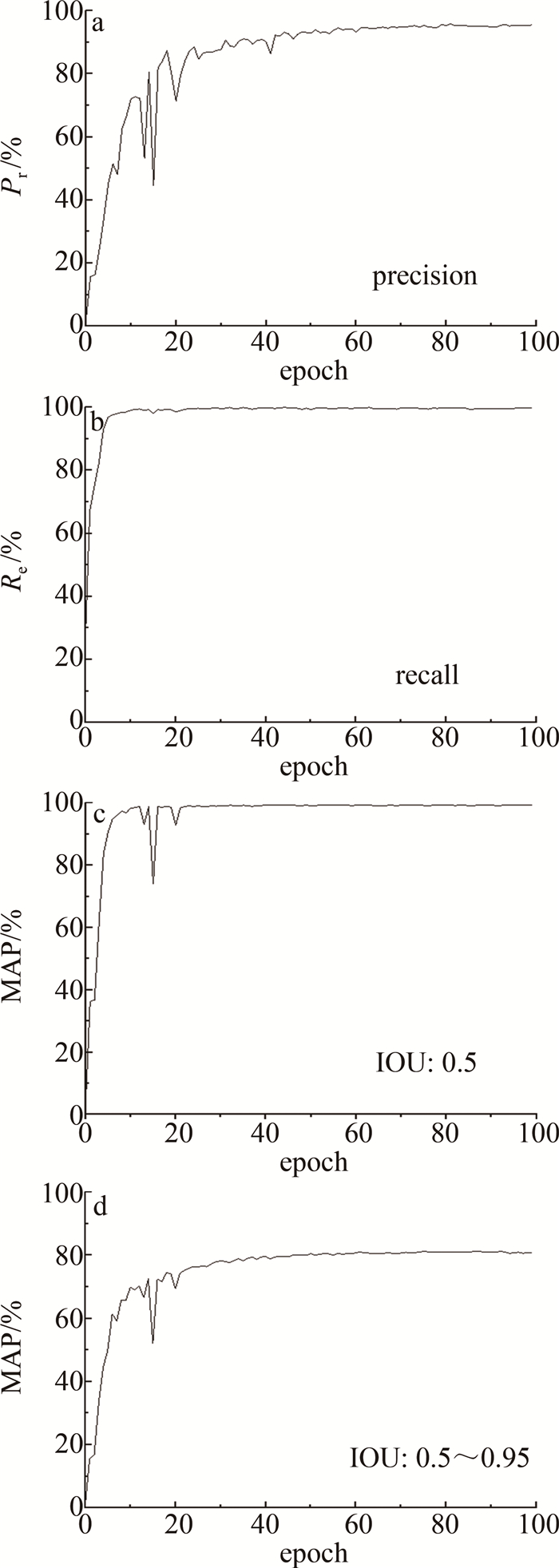
图 7是改进模型的准确率、召回率以及MAP曲线图。横坐标为训练次数,纵坐标为百分率。图 7a显示改进后网络的精确率已达到95.62%,图 7b显示召回率已达到99.69%,图 7c为交并比(intersection over union,IOU)阈值设为0.5时的MAP值,显示已达到99.10%,图 7d为不同IOU阈值(0.5~0.95,步长0.05)时的平均MAP值,显示已达到80.61%。由图 7a可知,在训练50次时, 已经收敛且收敛接近1。
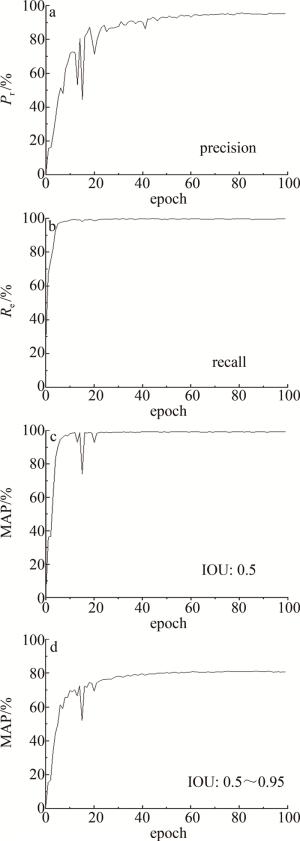
图 7 训练过程中准确率、召回率和MAP
Figure 7. Precision, recall and MAP during training
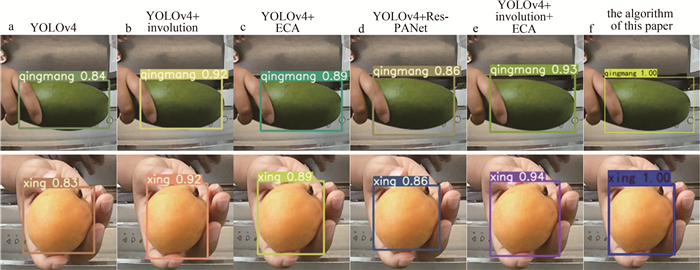
图 8是训练后本文中改进模型对水果的识别效果。每个框的左上角代表算法检测框的置信度,置信度是YOLO系列算法评估检测框准确性的指标,表示预测框检测到某个物品种类时,预测框与物品真实框的重合程度[20-22],如下式所示:
$ C_{\mathrm{i}}=P_{\mathrm{r}}\left(O_{\mathrm{b}}\right) \times I_{\mathrm{p, t}} $
(9) 
图 8 本文中算法的水果识别结果
Figure 8. Fruit recognition results of this algorithm
式中,Ci代表检测框的置信度;Ob代表物体;Ip, t代表检测框与真实框的交并比,即真实框与预测框交集部分与并集部分的比值,大小在0~1之间[23]。
通过与目前主流网络YOLOv3-SPP、YOLOv4、YOLOv5进行对比测试,来检验本文中改进模型的识别性能。实验结果如表 1所示。本文中模型的MAP相比较YOLOv3-SPP、YOLOv4、YOLOv5都大幅上升,分别增长了31.4%、15.3%、10.2%,模型大小相比较YOLOv4减小了115 Mbit。本文中的改进模型传输帧数为41.67/s,虽相较于YOLOv4的每秒传输帧数稍有降低, 但依然满足检测实时性, 且MAP具有明显提高。
表 1 主流检测算法性能对比
Table 1. Performance comparison of mainstream detection algorithms
model MAP/% size/Mbit number of frames transmitted/s-1 YOLOv3-SPP 68.00 323 35.13 YOLOv4 84.10 488 43.47 YOLOv5 89.20 55.8 45.23 the algorithm of this paper 99.40 373 41.67 -
为了验证改进算法所采用模块对YOLOv4的提升效果,本文中进行了消融实验。分别在YOLOv4网络的基础上分别单独添加内卷算子、残差结构和ECA通道注意力机制进行对比验证。表 2为消融实验结果。表中involution代表用内卷算子替换YOLOv4中CSP-Darknet53连接处的普通卷积、ECA代表添加ECA通道注意力以及Res-PANet代表在PANet中引入残差结构。消融实验分别比较了各种模块组合下的MAP和实时检测帧率。不难看出,原始YOLOv4的MAP仅为84.10%,传输帧数为43.47/s。在此模型上将CSP-Darknet53中连接处卷积层替换为involution后MAP提高了6%,每秒传输帧数提升了4%,由此已证明内卷算子的有效性;单引入ECA通道注意力,虽会降低网络的运算速度从而导致检测帧率小幅下降,但MAP提高5%,表明ECA可以在不影响实时性检测的情况下有效提升MAP;若只将在PANet处添加残差结构,MAP和每秒传输帧数小有提升,表明Res-PANet在解决网络加深所带来梯度爆炸问题的同时提升算法检测精度。最后同时加入involution、ECA以及Res-PANet结构后,MAP上升至99.40%,在大幅提高平均精准度的情况下也保证了较高的检测帧率。
表 2 消融实验
Table 2. Ablation experiment
model MAP/% number of frames transmitted/s-1 YOLOv4 84.10 43.47 YOLOv4+involution 90.70 47.52 YOLOv4+ECA 89.42 40.30 YOLOv4+Res-PANet 85.64 44.56 YOLOv4+involution+ECA 93.12 42.14 the algorithm of this paper 99.40 41.67 为展示本文中的算法消融实验的实际效果,选取部分测试集中的水果图片进行检测实验。图 9a是原始YOLOv4结果,图 9b是单加入内卷算子的结果,图 9c是单加入ECA的结果,图 9d是单加入Res-PANet结果,图 9e是添加内卷算子和ECA的结果,图 9f是本文中的改进算法。通过对比可以看出, 本文中所添加模块均能有效提高水果的置信度,即识别精度,通过对YOLOv4加入内卷算子、ECA注意力以及残差结构,实验所得水果种类识别率最高,可达100%。而其余模型识别率均小于本文中的算法,其中原始YOLOv4识别率最低,仅为84.10%,体现出所加模块的优越性。

图 9 消融实验结果对比
Figure 9. Comparison of ablation results
-
水果识别算法的发展趋势要求识别准确率高,识别速度快。本文作者在CSPDarknet53中添加ECA注意力机制,通过分配特征图中每个通道不同权重优化主干网络特征提取效果,丰富了模型识别水果种类的性能;用内卷算子替换CSPBlock连接处的卷积层,使得水果检测模型精度提高同时内存消耗减少;在PANet增加残差块,避免了可能会出现的梯度消失状况稳定网络的性能。实验数据表明,本文中的改进模型相比较于YOLOv4,MAP提高了15.30%,达到99.10%,模型大小减小115 Mbit,检测效果有明显的提升,传输帧数为41.67/s,满足工业实时性要求。在接下来的研究中将会着重改进特征融合网络结构,尝试增添不同的特征融合网络结构,在提高MAP的基础上进一步减小模型尺寸和参数的数量,并且在工程中实现。
基于改进YOLOv4算法的水果识别检测研究
Research on fruit recognition detection algorithm based on improved YOLOv4
-
摘要: 为了解决目前水果识别检测方法效率低、误检率高、通用性低、实时性差等问题, 提出了一种基于改进的你只用看一遍(YOLO)统一框架的实时目标检测YOLOv4算法的水果识别检测方法。首先在主干网络的基础上增加高效通道注意力机制, 增强网络提取图像语义信息能力; 其次用内卷算子替换主干网络中跨级局部模块连接处卷积层, 减小了模型大小, 增强了网络预测性能; 最后在路径聚合网络基础上添加残差模块, 加快网络收敛速度的同时防止了网络梯度爆炸。数据集选取生活中常见的火龙果、橙子、葡萄、青芒等10种水果, 拍摄共获得6670张图片。结果表明, 本文中的方法均值平均精度(MAP)为99.1%, 准确率为95.62%, 传输帧数为41.67/s; MAP相比YOLOv4提升了15.3%。该研究满足高检测精度和检测速度要求, 对水果识别精度的提高具有重要的参考价值。Abstract: In order to solve the problems of low efficiency, high false detection rate, low versatility, poor real-time performance of the current fruit identification and detection methods, a fruit recognition detection method based on improved you only look once (YOLO) YOLOv4 algorithm was proposed in this study. Firstly, an efficient channel attention was added to the backbone network to enhance the network's ability to extract semantic information from images. Secondly, the convolutional layers at the cross stage partial block junction in the backbone network were replaced by involutions, which reduced the model size and enhanced the network prediction performance. Finally, residual modules were added to the feature fusion network path aggregation network to speed up network convergence and prevent network gradient explosion. The datasets selected 10 kinds of fruits common in life: dragon fruits, oranges, grapes, green mangoes and so on with a total of 6670 pictures. The experiments show that the mean average precision (MAP) of the proposed method is 99.10%, the precision is 95.62%, and the number of frames transmitted is 41.67/s, respectively. MAP is improved by 15.3% compared with YOLOv4. This study meets the requirements of high detection accuracy and detection speed and has important reference value for improving the accuracy of fruit identification.
-
表 1 主流检测算法性能对比
Table 1. Performance comparison of mainstream detection algorithms
model MAP/% size/Mbit number of frames transmitted/s-1 YOLOv3-SPP 68.00 323 35.13 YOLOv4 84.10 488 43.47 YOLOv5 89.20 55.8 45.23 the algorithm of this paper 99.40 373 41.67  下载: 导出CSV
下载: 导出CSV
表 2 消融实验
Table 2. Ablation experiment
model MAP/% number of frames transmitted/s-1 YOLOv4 84.10 43.47 YOLOv4+involution 90.70 47.52 YOLOv4+ECA 89.42 40.30 YOLOv4+Res-PANet 85.64 44.56 YOLOv4+involution+ECA 93.12 42.14 the algorithm of this paper 99.40 41.67
下载: 导出CSV
-
[1] SEYED I S, HOSSEIN K. A deep neural network approach towards real-time on-branch fruit recognition for precision horticulture[J]. Expert Systems with Applications, 2020, 159(30): 113594. [2] KANG H W, ZHOU H Y, WANG X, et al. Real-time fruit recognition and grasping estimation for robotic apple harvesting[J]. Sensors, 2020, 20(19): 5670. doi: 10.3390/s20195670 [3] LI Q W, JIA W K, SUN M L, et al. A novel green apple segmentation algorithm based on ensemble U-Net under complex orchard environment[J]. Computers and Electronics in Agriculture, 2021, 180(6): 105900. [4] ALTAHERI H, ALSULAIMAN M, MUHAMMAD G. Date fruit classification for robotic harvesting in a natural environment using deep learning[J]. IEEE Access, 2019, 7: 117115-117133. doi: 10.1109/ACCESS.2019.2936536 [5] SUN S Sh, JIANG M, LIANG N, et al. Combining an information-maximization-based attention mechanism and illumination invariance theory for the recognition of green apples in natural scenes[J]. Multimedia Tools and Applications, 2020, 79(37/38): 1-27. [6] YU L Y, XIONG J T, FANG X Q, et al. A litchi fruit recognition method in a natural environment using RGB-D images[J]. Biosystems Engineering, 2021, 204(1): 50-63. [7] WU G, LI B, ZHU Q B, et al. Using color and 3D geometry features to segment fruit point cloud and improve fruit recognition accuracy[J]. Computers and Electronics in Agriculture, 2020, 174(6): 105475. [8] 陈超, 齐峰. 卷积神经网络的发展及其在计算机视觉领域中的应用综述[J]. 计算机科学, 2019, 46(3): 69-79. CHEN Ch, QI F. Review on development of convolution neural and its application in computer vision[J]. Computer Science, 2019, 46(3): 69-79(in Chinese). [9] 董戈. 基于深度学习和图像处理的水果收获机器人抓取系统[J]. 农机化研究, 2021, 43(3): 260-264. doi: 10.3969/j.issn.1003-188X.2021.03.046 DONG G. Fruit harvesting robot handling system based on deep learning and image processing[J]. Journal of Agricultural Mechanization Research, 2021, 43(3): 260-264(in Chinese). doi: 10.3969/j.issn.1003-188X.2021.03.046 [10] 翟超飞, 马宇亮, 赵德金. 卷积神经网络水果识别[J]. 南方农机, 2021, 52(10): 59-60. doi: 10.3969/j.issn.1672-3872.2021.10.021 ZHAI Ch F, MA Y L, ZHAO D J. Convolutional neural network fruit recognition[J]. China Southern Agricultural Machinery, 2021, 52(10): 59-60(in Chinese). doi: 10.3969/j.issn.1672-3872.2021.10.021 [11] 黄玉富, 朴燕, 张汉辉. 基于多尺度特征融合的水果图像识别算法研究[J]. 长春理工大学学报(自然科学版), 2021, 44(1): 87-94. doi: 10.3969/j.issn.1672-9870.2021.01.013 HUANG Y F, PIAO Y, ZHANG H H. Research on fruit image recognition algorithm based on multi-scale feature fusion[J]. Journal of Changchun University of Science and Technology(Natural Science Edition), 2021, 44(1): 87-94(in Chinese). doi: 10.3969/j.issn.1672-9870.2021.01.013 [12] 彭红星, 黄博, 邵园园, 等. 自然环境下多类水果采摘目标识别的通用改进SSD模型[J]. 农业工程学报, 2018, 34(16): 155-162. doi: 10.11975/j.issn.1002-6819.2018.16.020 PENG H X, HUANG B, SHAO Y Y, et al. A general improved SSD model for target recognition of multiple types of fruit picking in natural environments[J]. Transactions of the Chinese Society of Agricultural Engineering, 2018, 34(16): 155-162(in Chinese). doi: 10.11975/j.issn.1002-6819.2018.16.020 [13] 王辉, 张帆, 刘晓凤. 基于DarkNet-53和YOLOv3的水果图像识别[J]. 东北师大学报(自然科学版), 2020, 52(4): 60-65. WANG H, ZHANG F, LIU X F. Fruit image recognition based on DarkNet-53 and YOLOv3[J]. Journal of Northeast Normal University(Natural Science Edition), 2020, 52(4): 60-65(in Chinese). [14] 钟志峰, 夏一帆, 周冬平, 等. 基于改进YOLOv4的轻量化目标检测算法[J]. 计算机应用, 2021, 40(10): 32-39. ZHONG Zh F, X Y F, ZHOU D P, et al. Lightweight object detection algorithm based on improved YOLOv4[J]. Journal of Computer Applications, 2021, 40(10): 32-39(in Chinese). [15] 傅隆生, 冯亚利, ELKAMIL Tola, 等. 基于卷积神经网络的田间多簇猕猴桃图像识别方法[J]. 农业工程学报, 2018, 34(2): 205-211. FU L Sh, FENG Y L, ELKAMIL T, et al. Image recognition method of multi-cluster kiwifruit in the field based on convolutional neural network[J]. Transactions of the Chinese Society of Agricultural Engineering, 2018, 34(2): 205-211(in Chinese). [16] LI D, HU J, WANG C H, et al. Involution: Inverting the inherence of convolution for visual recognition[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021. New York, USA: IEEE, 2021: 12321-12330. [17] TAN M X, PANG R M, LE Q V. Efficientdet: Scalable and efficient object detection[C]//CVPR 2020: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2020: 10781-10790. [18] 熊俊涛, 刘振, 汤林越, 等. 自然环境下绿色柑橘视觉检测技术研究[J]. 农业机械学报, 2018, 49(4): 45-52. XIONG J T, LIU Zh, TANG L Y, et al. Research on visual inspection technology of green citrus in natural environment[J]. Transactions of the Chinese Society for Agricultural Machinery, 2018, 49(4): 45-52(in Chinese). [19] FANG W, WANG L, REN P M. Tinier-YOLO: A real-time object detection method for constrained environments[J]. IEEE Access, 2019, 8: 1935-1944. [20] 刘春妹, 高洪民, 王学田, 等. 基于深度学习的水果图像识别系统[J]. 微波学报, 2020, 36(s1): 427-430. LIU Ch M, GAO H M, WANG X T, et al. Fruit image recognition system based on deep learning[J]. Journal of Microwaves, 2020, 36(s1): 427-430(in Chinese). [21] 柳长安, 冯雪菱, 孙长浩, 等. 基于改进麻雀算法的最大2维熵分割方法[J]. 激光技术, 2022, 46(2): 274-282. LIU Ch A, FENG X L, SUN Ch H, et al. Maximum 2-D entropy image segmentation method based on improved sparrow algorithm[J]. Laser Technology, 2022, 46(2): 274-282(in Chinese). [22] HU J, SHEN L, SUN G. Squeeze-and-excitation networks[C]//CVPR 2018: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2018: 7132-7141. [23] WANG W H, XIE E Z, SONG X G, et al. Efficient and accurate arbitrary-shaped text detection with pixel aggregation network[C]//ICCV 2019: Proceedings of the IEEE/CVF International Conference on Computer Vision. New York, USA: IEEE, 2019: 8440-8449. -
 点击查看大图
点击查看大图
图(9) / 表(2)
计量
- 文章访问数: 2274
- HTML全文浏览量: 1174
- PDF下载量: 29
- 被引次数: 0
