 网站地图
网站地图


-
高光谱图像是由成像光谱仪接收的数十上百个波段所反射回来的地物的光谱特性组成。高光谱图像由两个空间维和一个光谱维构成,光谱维中的光谱向量代表了高光谱图像中相应像素独特的光谱特征。由于光谱特征在特征识别方面的优势, 目前高光谱图像处理技术已经被广泛应用到各种场景中[1-2],例如精准农业[3]、海洋监测[4]以及城乡规划[5]等。在这些应用场景中,高光谱图像分类起到了重要作用。近年来,一些空谱联合分类算法被用来提升分类精度[6-8]。这些方法用于学习训练样本标签是可行的,然而在实际应用中并非如此。
有监督的高光谱图像分类算法要求样本是标记完成的,但是手动标记过程非常困难,仅凭视觉解释的训练样本并不可靠。具体来说,引入误标签的原因有如下几点:(1)全球定位系统会对目标对象的空间位置产生不准确的估计,导致很难确定高光谱像素的精确位置; (2)对于一些场景,比如海洋和湿地,这样的场景人类无法到达,在这种情况下,基于人类视觉解读的训练样本标签不可避免会产生噪声; (3)当标记一个包含许多不规则形状土地覆盖物的场景时,人工贴标签的过程中会产生错误。
为了解决训练样本的误标签问题,对计算机视觉领域进行了深入的研究。LU等人[9]提出一种基于曼哈顿距离优化的学习模型来检测弱噪声标签。FOODY等人[10]发现, 噪声标签会影响基于支持向量机的机载制图分类。虽然许多研究已经解决了计算机视觉领域的噪声标签问题,但由于高光谱图像的高维和非线性结构,这些方法不能直接扩展到高光谱图像误标签分类中。最近几年,关于带有噪声标签的高光谱图像分类算法得到了关注。KANG等人[11]首次提出了基于光谱检测和边缘保持滤波的噪声标签检测和校正方法。TU等人[12]通过融合光谱角度和局部离群值因子来检测高光谱图像中的噪声标签,实验结果表明,该算法能有效地检测出有噪声的标签。密度峰值(density peak, DP)聚类算法作为一种鲁棒的聚类算法首次在科学杂志上被提出[13]。TU等人[14]首次利用DP聚类算法来检测高光谱图像训练样本中的误标签,基于DP聚类的高光谱图像误标签检测算法在检测过程中没有考虑相邻光谱像素之间的空间相关性。为了解决这一问题,TU等人[15]提出一种新的基于空间DP聚类(k-spatial density peak, K-SDP)的噪声标签检测算法,该算法通过加入中心样本的邻域样本来进一步检测中心样本的异常程度。然而,参考文献[14]和参考文献[15]中没有考虑原始高光谱图像中存在稀疏噪声的问题。参考文献[16]中提出一种基于核熵分量分析(kernel entropy component analysis, KECA)的噪声标签检测方法,但是,该算法在检测过程中没有考虑到训练样本的上下文信息。多种基于约束能量最小化(constrained energy minimum, CEM)算法已被广泛应用于高光谱图像处理中。ZOU等人[17]提出一种用于高光谱图像目标检测的二次约束能量最小化检测器。此外,ZHANG等人[18]提出一种混合稀疏性和CEM的检测器,以提高目标检测的性能。CEM也有效地应用到了高光谱图像误标签检测上。TU等人[19]提出了一种层次约束能量最小值(hierarchical constrained energy minimum, HCEM)方法来检测经过监督任务训练的原始训练集的错误标记样本,该方法可以准确地去除原始训练集的噪声标签,有效地提高监督分类任务的性能。但是,该算法的一个缺点是使用原始的光谱角制图算法(spectral angle mapping, SAM)来衡量光谱向量的相似度。原始的SAM是一种全局性的描述指标,当部分波段属性值有变化、或全部波段属性值具有不同的变化值时, 往往导致光谱角余弦的失真。
为了解决参考文献[14]~参考文献[16]和参考文献[19]中所出现的问题,本文作者提出基于低秩稀疏和改进光谱角制图的密度峰值聚类算法(low rank sparse-normalized spectral angular mapping density peak clustering, LRS-NSAMDP)。相比于DP聚类算法[14]和K-SDP[15]算法,本算法的改进是去除原始高光谱图像中的稀疏噪声,提取高光谱图像中的低秩成分,降低每一类样本中的加权平均局部密度,从而减少了光谱向量中的误标签数目,提高了分类精度。相比于基于层次约束能量最小值的高光谱图像误标签分类算法[19],本算法对原始的SAM算法进行改进,将光谱向量在波段上的属性值除以该光谱向量的模进行归一化,相比于SAM算法降低了同类像元之间的光谱角,使同类像元更加接近,从而更容易检测出训练样本中的像元之间差异较大的误标签。通过以上两个改进,相比于其它先进的遥感图像误标签分类算法,提升了总体精度(overall accuracy, OA)、平均精度(average accuracy, AA)和kappa系数。
-
一幅原始高光谱图像Y ≡[y1, y2, …, yQ],Q代表每一波段的像素数。由于高光谱图像相邻波段之间的高相关性,根据线性回归理论和最小二乘法理论[20],假设zi为传感器在第i波段读取的相关系数向量,所以有:
$ \boldsymbol{z}_i=\boldsymbol{Z}_{\partial_i} \boldsymbol{\beta}_i+\boldsymbol{\xi}_i $
(1) $ \hat{\boldsymbol{\beta}}_i=\left(\boldsymbol{R}_{\partial_i, \partial_i}{ }^{\prime}-\boldsymbol{R}_{\partial_i, i}{ }^{\prime} \boldsymbol{R}_{i, \partial_i}{ }^{\prime} / \boldsymbol{R}_{i, i}{ }^{\prime}\right) \hat{\boldsymbol{R}}_{\partial_i, i} $
(2) 式中,Z∂i表示去除第i波段后的相关系数矩阵,βi表示第i波段的回归向量,ξi代表稀疏噪声向量, $ \hat{\boldsymbol{R}}$=(YYT)为自相关矩阵,R′为自相关矩阵$ \hat{\boldsymbol{R}}$的逆,R∂i, ∂i′表示删除第i行和第i列的自相关矩阵的逆;上标^表示估计值。
接下来根据预测到的稀疏噪声向量$ \hat{\boldsymbol{\xi}}$i来估计信号子空间。计算原始高光谱图像Y自相关矩阵$ \hat{\boldsymbol{R}}$Y,同理计算稀疏噪声向量ξi的自相关矩阵$ \hat{\boldsymbol{R}}$ξ,计算真实信号原始光谱向量x的自相关矩阵$ \hat{\boldsymbol{R}}$x, 并计算其特征向量E,将高光谱图像所在的空间分解为k维子空间Ek和Eγ,Eγ表示子空间Ek的正交补空间。设Uk为子空间Ek的投影矩阵,Uγ为子空间Eγ的投影矩阵, $\hat{\boldsymbol{x}} $k≡Uky, 为观测到的光谱向量y在子空间Ek上的投影,在此将$\hat{\boldsymbol{x}} $ k和原始光谱向量x之间的最小均方误差作为估计子空间的准则[21],可得:
$ K=(\hat{k}, \hat{\pi})=\underset{k, \pi}{\operatorname{argmin}}\left\{\operatorname{tr}\left(\boldsymbol{U}_{\boldsymbol{R}} \hat{\boldsymbol{R}}_{\boldsymbol{Y}}\right)+2 \operatorname{tr}\left(\boldsymbol{U}_k \hat{\boldsymbol{R}}_{\boldsymbol{\xi}}\right)\right\} $
(3) 式中,K为设置项,$\widehat{k}$为δ=tr(UR $ \hat{\boldsymbol{R}}$Y)+2tr(Uk $ \hat{\boldsymbol{R}}$ξ)取负值的个数,tr表示矩阵的迹, $ \hat{\pi}$为置换项, π为波段1~i的矩阵排列。将δ取负值时所对应的特征向量E中的子集作为预测到的子空间$\hat{\boldsymbol{S}} $,具体来说,子空间$\hat{\boldsymbol{S}} $可以根据$\widehat{k}$和$ \hat{\pi}$所对应的特征向量进行检索得到[21]。
-
SAM是KRUSE等人在1993年提出的[22],把图像中的每一个像元的光谱视为一个高维向量,通过计算两向量之间的夹角来度量光谱间的相似性,夹角越小,两光谱越相似,属于同类地物的可能性越大,因而可根据光谱角的大小来辨别未知数据的类别。分类时,通过计算未知数据与已知数据间的光谱角,并把未知数据的类别归为最小光谱角对应的类别中, 如下式所示:
$ \cos \alpha=\frac{A \cdot B}{|A||B|}=\frac{\sum\limits_{i=1}^L A_i B_i}{\sqrt{\sum\limits_{i=1}^N A_i A_i} \sqrt{\sum\limits_{i=1}^N B_i B_i}} $
(4) 式中, L为波段数,A和B分别表示两个光谱向量在L个波段上的属性值,α为光谱角。夹角越小, 余弦值较大;相反夹角大, 相应的余弦值就较小。
-
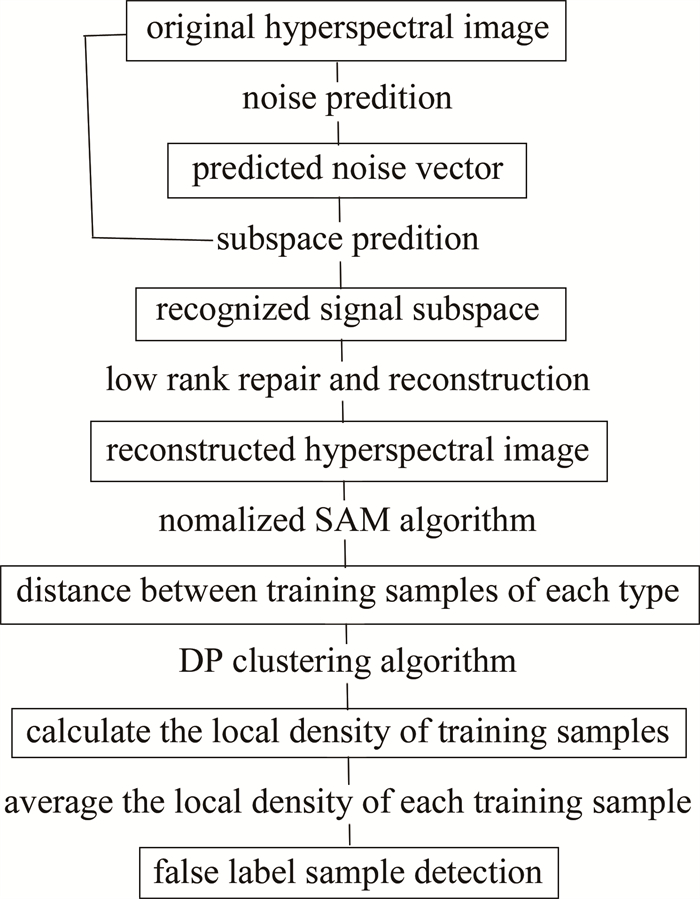
图 1是所提出的LRS-NSAMDP的流程图。主要分为5个步骤:(1)基于低秩稀疏表示的高光谱图像低秩特征提取;(2)计算各个类中训练样本间的距离;(3)训练样本局部密度的计算;(4)检测误标签训练样本;(5)支持向量机分类。
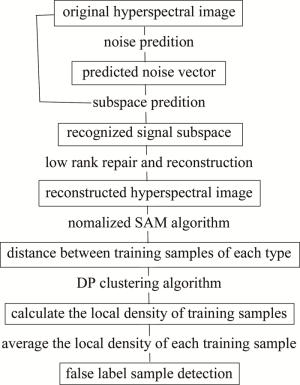
Figure 1. Flow chart of LRS-NSAMDP algorithm
-
根据第1.1节中得到原始高光谱图像Y的信号子空间$\hat{\boldsymbol{S}} $,该问题可表述为:
$ \boldsymbol{z}=\min \limits_z \frac{1}{2}\|\boldsymbol{M}(\boldsymbol{I} \otimes \hat{\boldsymbol{S}}) \boldsymbol{z}-\boldsymbol{y}\|^2+\delta \phi(\boldsymbol{z}) $
(5) 式中, $ \otimes$表示克罗内克乘积,‖·‖表示矩阵的范数,I表示单位矩阵,Z表示相关系数矩阵,z为向量化z,M为掩模,ϕ(z)表示正则化函数,δ是正则化系数,y为向量化图像Y。设掩模Mp作用在未观测到的像素p所对应的高光谱图像yp,所以有:
$ \boldsymbol{y}_p=\boldsymbol{M}_p \hat{\boldsymbol{S}} \boldsymbol{z}_p+\boldsymbol{n}_p $
(6) 式中,np表示噪声部分,根据参考文献[21]可得$ \hat{\boldsymbol{z}} $p,计算$\hat{\boldsymbol{y}} $p= $\hat{\boldsymbol{S}} $ $ \hat{\boldsymbol{z}} $p得到完全观测到的高光谱图像$ \hat{\boldsymbol{Y}}$。在恢复未观测到的分量后,需要去除原始噪声。所以有:
$ \boldsymbol{Z}=\min\limits_\boldsymbol{Z} \frac{1}{2}\|\hat{\boldsymbol{S}} \boldsymbol{Z}-\hat{\boldsymbol{Y}}\|^2+\delta \phi(\boldsymbol{Z}) $
(7) 对于(7)式的优化问题,在此利用3维块匹配滤波算法进行去噪,得到相关系数矩阵z,所以重构的高光谱图像X可由$ \hat{\boldsymbol{X}}$ = $\hat{\boldsymbol{S}} $z得到。
-
根据得到的重构后的高光谱图像$ \hat{\boldsymbol{X}}$的训练样本$ \hat{\boldsymbol{T}}$,m表示训练样本$ \hat{\boldsymbol{T}}$中类的个数,$ \hat{\boldsymbol{T}}$jn表示第j类中的n个训练样本,在此提出基于归一化的光谱角计算方法来度量光谱相似度。
$ \left\{\begin{array}{l} \hat{\boldsymbol{g}}_a=\frac{\hat{\boldsymbol{T}}_{j a}}{\sum\limits_{a=1}^n \sqrt{\left(\hat{\boldsymbol{T}}_{j a}\right)^2}} \\ \hat{\boldsymbol{g}}_b=\frac{\hat{\boldsymbol{T}}_{j b}}{\sum\limits_{b=1}^n \sqrt{\left(\hat{\boldsymbol{T}}_{j b}\right)^2}} \end{array}\right. $
(8) $ d_{a b}=\arccos \left[\frac{\hat{\boldsymbol{g}}_a{ }^{\mathrm{T}} \hat{\boldsymbol{g}}_b}{\left\|\hat{\boldsymbol{g}}_a\right\|\left\|\hat{\boldsymbol{g}}_b\right\|}\right] $
(9) 式中, $ \hat{\boldsymbol{g}}$a和$ \hat{\boldsymbol{g}}$b分别表示归一化后的第a个和第b个样本的光谱向量,dab表示两样本之间的距离。通过计算第j类中第l个像素和类中其它像素之间的距离,第l个像素的距离数组可以构造如下:
$ \boldsymbol{d}_l=\left[d_{l, l 1}, d_{l, l 2}, \cdots, d_{l, l j}\right]^{\mathrm{T}} $
(10) 式中,lj代表第j类中的所有像素数,每一类样本的距离矩阵Dj={d1, d2, …, dj}。
-
为了计算训练样本间的局部密度,定义截止距离dc,计算方式如下:
$ \boldsymbol{d}_{\mathrm{c}}=\boldsymbol{S}(t), \left(t=\left\langle\frac{N_j \cdot\left(N_j-1\right)}{100} \cdot \theta\right\rangle\right) $
(11) 式中, S(t)为将Dj的上三角矩阵中的非零元素从最小到最大排序得到的矩阵,Nj为第j重样本总数, θ为随机参数,〈·〉为四舍五入运算。根据得到的dc矩阵计算每一类的局部密度$\rho=\sum \exp \left[-\left(\boldsymbol{D}_j / \boldsymbol{d}_{\mathrm{c}}\right)^2\right] $。
-
根据每一类中每一个训练样本的局部密度,误样本可以通过线性阈值决策函数计算得到:
$ \boldsymbol{W}=\left\{\begin{array}{l} \boldsymbol{H}_{j a}, \left(\rho_{j a} \geq \lambda \bar{\rho}_j\right) \\ \mathit{\Phi}, (\text { otherwise }) \end{array}\right. $
(12) 式中, W为检测完成后并删除误样本后的训练集, Hja为检测为正确标签的第j类中的第a个样本,ρja为第j类第a个样本的局部密度, ρj为第j类样本的平均局部密度, λ为随机参数, 。
-
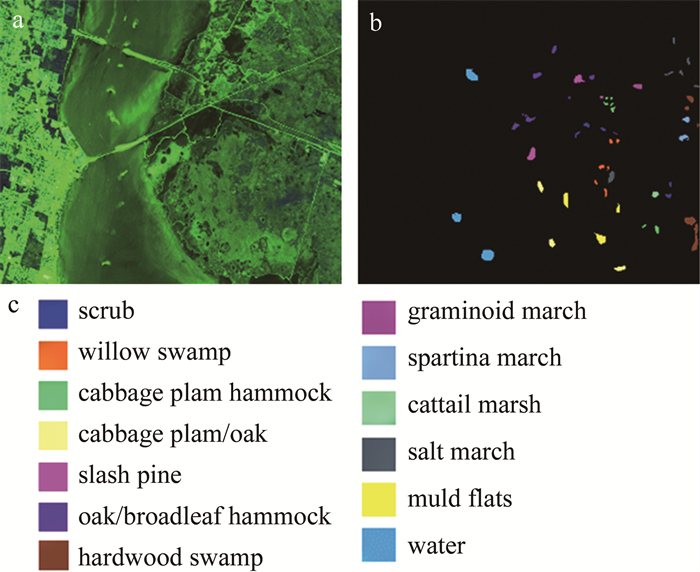
Kennedy Space Center(KSC)数据集是由AVIRIS高光谱仪于1996年在佛罗里达州肯尼迪太空中心采集的512像素×614像素大小的高光谱图像,包含224个波段,经过噪声去除后还剩下176个波段,空间分辨率是18m,有13个地物类别,总样本大小为5211。
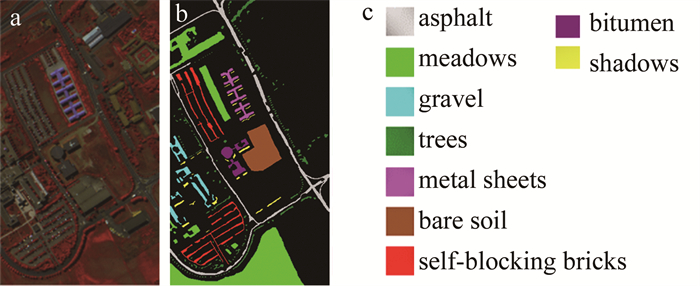
University of Pavia(PaviaU)数据集是由ROSIS高光谱仪在帕维亚大学上空采集的610像素×340像素大小的高光谱图像,共包含9类地物115个波段,去掉含噪声波段后,其余103个波段作为实验数据集,总体样本大小为42776。本算法的实验以及对比算法实验的运行环境为12G内存,英特尔酷睿i5 2.2GHz的CPU,开发环境为MATLAB R2018a。图 2和图 3分别给出了两种数据集的假彩色图像、地物真值图和每一类物种。
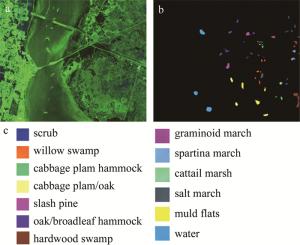
Figure 2. KSC dataset
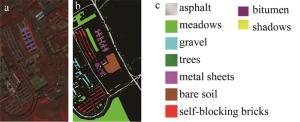
Figure 3. PaviaU dataset
-
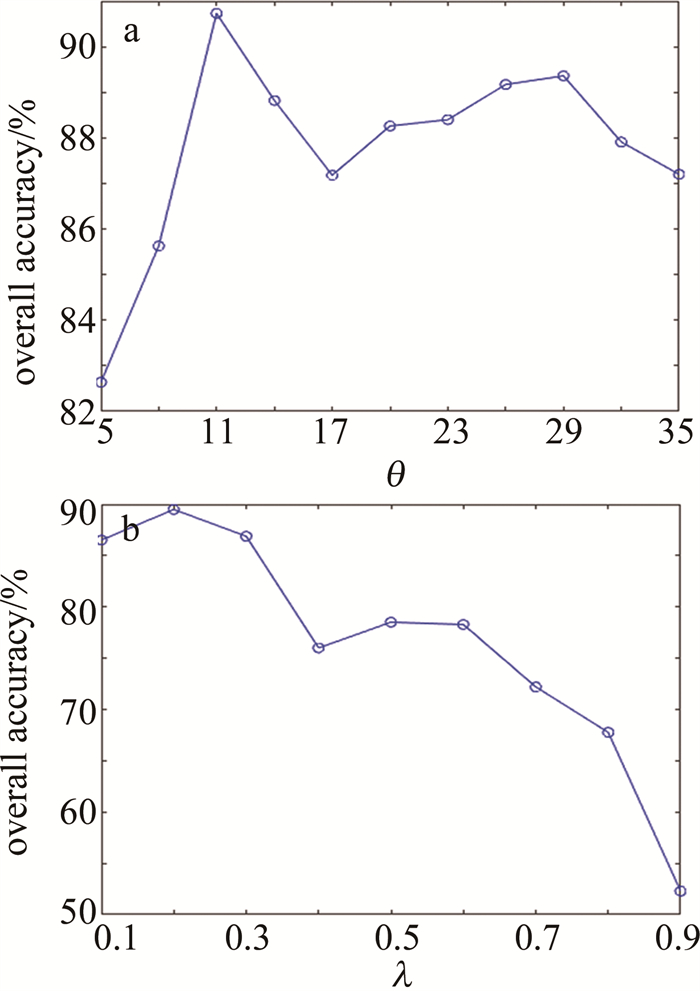
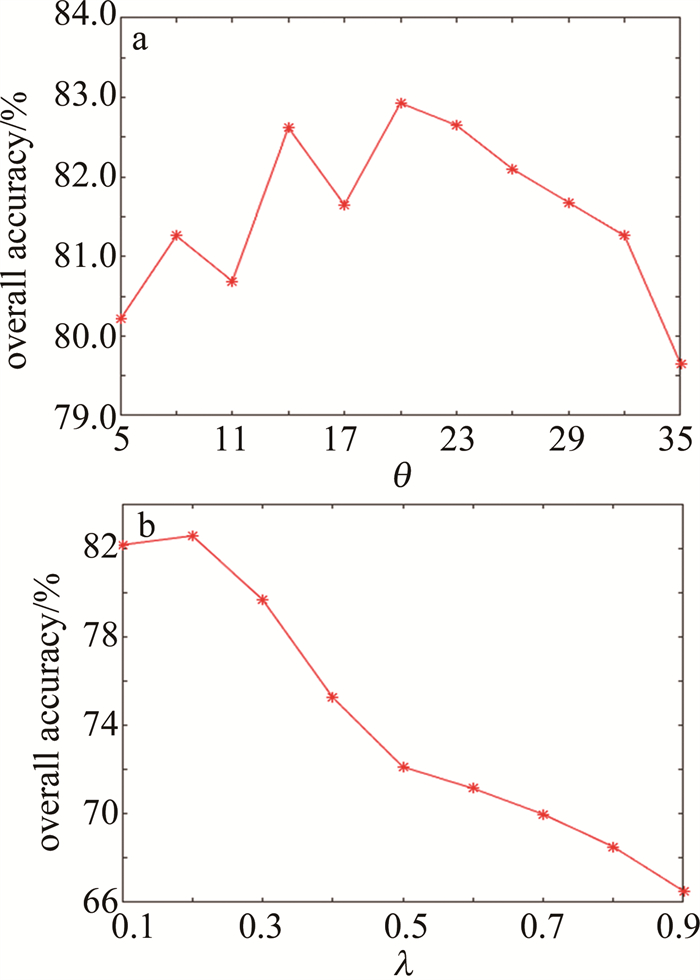
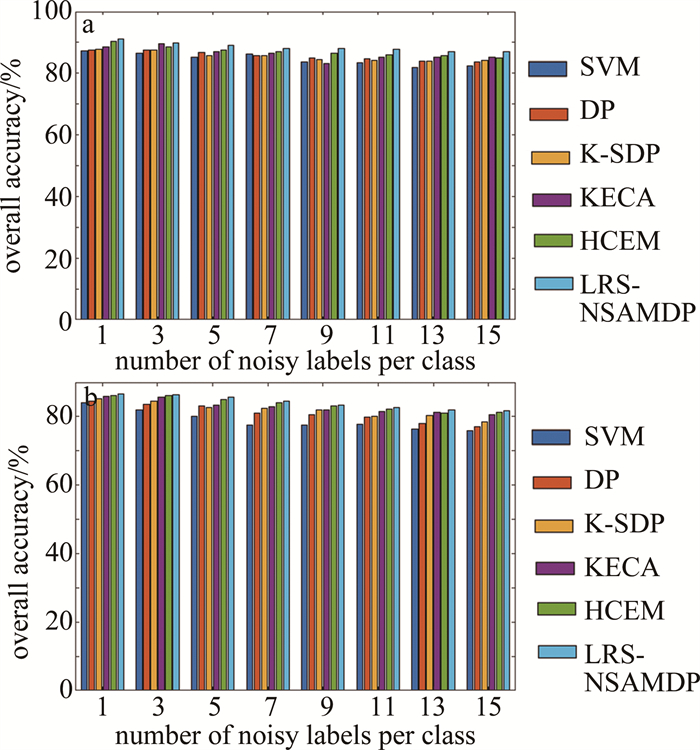
本算法提出的两个参数分别为:计算局部密度的随机参数θ和检测误标签训练样本的随机参数λ,图 4和图 5中分别展示了在KSC和PaviaU两个数据集上的不同参数下对OA的影响。为了证明算法的有效性,后续实验使用广泛应用在高光谱图像分类算法中的支持向量机(support vector machine, SVM)作为分类器,具体使用LIBSVM工具箱中的分类器,SVM的参数采用交叉验证的方式来确定。对于KSC数据集,对每一类随机选取25个真实样本和5个不确定标记样本,对于PaviaU数据集,对每一类随机选取50个真实样本和10个不确定标记样本。
根据图 4和图 5可以看出,随机参数θ在两个数据集上的波动范围相较于系数λ较小,比如在PaviaU数据集上,最大的局部密度只比最小的局部密度高2%左右,而在KSC数据集上最大的局部密度比最小的局部密度要高15%以上,因此决定本算法的精度值主要是随机参数θ。从图 4和图 5还可以看出, 在KSC数据集上,当取θ=11、λ=0.2时, 可以取得局部最优的OA值; PaviaU数据集上, 当取θ=20、λ=0.2时,可以取得局部最优的OA值。因此对于一个新的数据集,建议取θ=20、λ=0.2作为提出算法的参数设置。
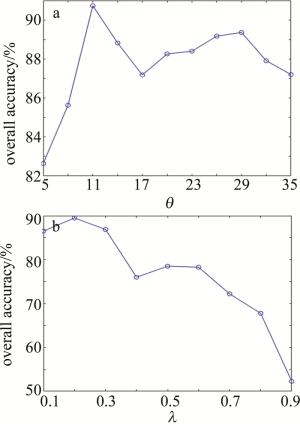
Figure 4. On KSC dataset, the parameter θ and λ coefficient of different local densities λ impact on OA
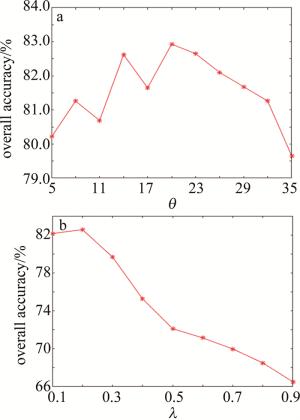
Figure 5. On PaviaU dataset, the parameter θ and λ coefficient of different local densities λ impact on OA
-
为了验证本算法的有效性,在此计算成功检测出的误样本数做为判别标准。具体验证方式为:根据DP聚类算法计算每一类样本的局部密度,得到聚类中心标签集合,根据(12)式统计ρja < λρj的数目r1,r1越小表示误标签越少,从而判别为正确标签的训练样本数目就越多,后续的分类精度就越高。
表 1中,T(true)表示真实标签,U(uncertain)表示不确定标签。从表中可以看出, DP聚类算法[14]检测到的误标签个数要大于K-SDP算法[15]和LRS-NSAMDP算法,删除掉误标签样本后的正确训练样本W={W1, W2, …, Wm}越少,后续的分类精度就越低。K-SDP[15]算法通过加入中心样本的邻域样本来进一步检测中心样本的异常程度,相比于DP聚类算法[14]考虑了相邻光谱像素之间的空间相关性,提升了后续分类精度。LRS-NSAMDP算法提取了原始高光谱图像的低秩成分,去除了原始图像中的稀疏噪声,使用基于归一化的光谱角制图算法来计算光谱相似度,减少了类样本之间像素的距离,增大了截止距离,根据(12)式推导可知, 降低了阈值λρj,从而r1的值会变小,误标签数目减少,相比于其它两种误标签检测算法,判别为正确标签的训练样本数目就多,后续的分类精度就越高。
Table 1. Umber of false labels in each class detected by different detection algorithms under different uncertain samples
为了验证改进光谱角制图算法的优越性,在此将多种距离度量算法应用在本算法当中,比如,欧几里得距离(Euclidean distance, ED)[23]、光谱信息散度(spectral information divergence, SID)[24]、相关系数(correlation coefficient, CC)[25]以及SAM[22]。根据表 2可以明显看出,本文中提出的归一化光谱角相似度算法取得了较优的分类精度,因此后续的对比实验采用本文中提出的归一化光谱角相似度算法来度量距离。
Table 2. Classification performance of KSC dataset under the false labeles detected by different distance measurement algorithms
-
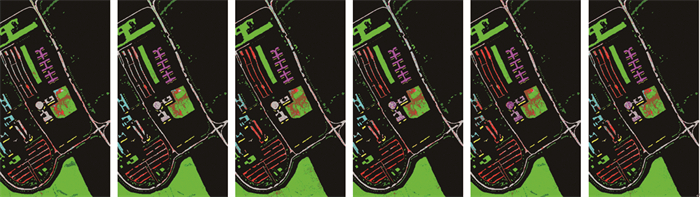
将本算法和先进的误标签检测算法进行对比,具体包括SVM算法[26]、DP聚类算法[14]、K-SDP算法[15]、KECA算法[16]和HCEM算法[19]。本算法的实验参数采用第3.2节中给出的参数,为了保持对比算法在最优的条件下进行对比,所有参数采用文献中给出的默认参数。在KSC数据集上,实验采用每一类25个正确样本加5个不确定样本、25个正确样本加15个不确定样本。在PaviaU数据集上,实验采用每一类50个正确样本加10个不确定样本、50个正确样本加20个不确定样本。限于篇幅,图 6和图 7中分别展示了在KSC数据集上25个正确样本加5个不确定样本和PaviaU数据集上50个正确样本加10个不确定样本下的不同误标签检测算法随机一次地物分类图。表 3和表 4中分别展示了不同误标签检测算法在KSC和PaviaU数据集上随机运行10次后求平均值的分类精度表格。

Figure 6. Feature classification map (25T+5U) obtained by different algorithms in KSC dataset

Figure 7. Feature classification map (50T+10U) obtained by different algorithms in PaviaU dataset
Table 3. Classification accuracy under different false label algorithms on KSC dataset
class number of true samples anduncertain samples 25T+5U 25T+15U SVM DP K-SDP KECA HCEM LRS-NSAMDP SVM DP K-SDP KECA HCEM LRS-NSAMDP scrub 93.53 95.30 95.04 93.29 92.87 96.44 96.11 95.73 95.30 93.38 87.79 96.83 will-S 79.86 83.77 81.30 85.60 89.90 88.49 77.02 74.53 76.62 79.93 86.39 88.27 cabb-H 91.84 84.55 83.43 82.76 83.67 78.18 86.19 84.34 85.04 81.06 84.16 70.89 cabb-O 58.72 64.64 64.31 62.60 61.99 65.89 56.02 57.00 56.64 60.02 54.48 57.89 slash-P 51.88 61.92 62.86 62.45 63.28 58.04 57.14 57.82 57.34 56.72 75.00 51.57 broad 51.72 57.08 59.27 55.13 54.59 75.09 36.10 48.74 53.65 57.81 51.60 67.20 hardwood 56.83 70.00 64.99 66.96 65.14 84.38 53.19 65.48 66.03 60.36 64.65 76.47 graminoid 82.58 78.09 77.49 80.34 78.24 89.57 52.58 69.17 73.83 80.82 89.49 77.63 spartina 89.27 84.96 86.89 89.07 92.67 92.52 88.55 82.63 87.10 86.75 87.52 88.94 cattail 80.85 92.55 88.93 94.48 100.00 90.96 83.21 87.27 88.86 94.13 91.72 89.93 salt 86.72 87.33 91.52 92.60 94.29 94.89 97.78 90.71 90.95 90.83 90.59 95.49 muld 83.62 90.24 94.40 93.48 84.92 91.45 82.76 87.10 85.11 92.81 84.88 93.05 water 99.18 96.62 99.50 99.60 100.00 98.79 100.00 98.65 99.0 98.07 96.33 98.87 OA/% 83.57 85.47 86.19 86.67 87.52 89.43 79.90 82.60 84.97 85.19 85.23 86.49 AA/% 77.43 80.54 80.76 81.42 81.66 84.98 74.36 76.86 79.35 79.44 80.35 81.00 kappa 0.8171 0.8381 0.8460 0.8514 0.8607 0.8821 0.7766 0.8062 0.8325 0.8349 0.8345 0.8493 Table 4. Classification accuracy of PaviaU dataset with different false label algorithms
class number of true samples anduncertain samples 50T+10U 50T+20U SVM DP K-SDP KECA HCEM LRS-NSAMDP SVM DP K-SDP KECA HCEM LRS-NSAMDP asphalt 89.43 95.72 97.09 93.83 80.57 96.25 88.69 89.63 92.52 95.94 95.82 96.51 meadows 93.05 93.80 94.03 94.66 95.72 97.43 92.46 92.64 93.69 92.78 93.71 92.91 gravel 57.31 58.11 60.86 60.75 57.14 61.38 56.47 56.90 57.10 65.44 58.16 67.37 trees 71.22 75.79 80.51 73.04 88.67 86.84 67.07 70.52 72.58 81.67 78.59 89.60 M-sheets 85.51 94.23 95.41 86.01 99.10 98.35 84.50 88.67 89.40 81.22 86.05 81.48 B-soil 57.34 56.00 59.96 66.78 44.17 47.28 48.12 49.53 56.25 50.86 60.03 60.64 bitumen 48.44 43.99 52.73 51.71 56.16 58.94 46.09 40.77 48.89 67.86 70.43 68.52 self-Bricks 77.10 74.95 80.00 75.89 81.17 83.28 71.47 73.33 76.47 59.66 56.37 66.26 shadows 83.26 74.66 95.89 88.34 83.01 93.82 87.30 77.30 92.22 70.53 69.26 70.19 OA/% 76.73 78.91 79.55 81.11 82.25 83.49 72.46 75.27 76.32 76.53 78.12 81.42 AA/% 73.84 73.93 79.50 76.77 76.19 80.40 71.96 73.70 75.93 74.00 74.27 77.05 kappa 0.7135 0.7187 0.7542 0.7577 0.7601 0.7783 0.6649 0.6772 0.6973 0.6982 0.7158 0.7551 根据图 6可知,本文中提出的LRS-NSAMDP算法和真实地物分类图更相似,证明了相比于SVM、DP、K-SDP、KECA和HCEM算法,本文中提出的算法可以有效地去除带有误标签的训练样本。由表 3可以看出,当每一类训练样本中包含5个不确定样本时,本文中提出的算法的OA值要比SVM的OA值高5.86%,此外,和两个高光谱图像误标签检测算法DP聚类和K-SDP聚类相比,本算法对原始高光谱图像提取了低秩成分,提高了原始高光谱的质量。根据第3.3节可知,本算法相比于DP聚类和K-SDP聚类可以有效减少训练样本中的误标签,在KSC数据集上的不同误标签样本下,都提升了分类精度。相比于KECA算法,本算法使用改进的光谱角制图算法充分获取每一类训练样本间的上下文信息,在每一类包含5个不确定的训练样本上OA提升2.76%。相比于使用未改进光谱角制图的HCEM算法,本算法克服了原始光谱角余弦的失真问题,能够抑制误差,在每一类包含15个不确定的训练样本上OA提升1.26%。同时根据图 7和表 4可以得出同样的结论,例如,当每一类训练样本中包含10个不确定样本时,本算法相比于SVM、DP、K-SDP、KECA和HCEM算法,OA分别提高了6.76%, 4.58%, 3.94%, 2.38%, 1.24%,在两种数据集上充分证明了本算法的有效性。
图 8中给出了不同训练集下使用不同误标签检测算法的总体精度柱状图。其中包括本算法和5种不同对比算法进行10次重复实验后获得的OA平均值。可以看出, 本算法相比于SVM、DP、K-SDP、KECA和HCEM算法,两个数据集上都提高了OA值,证明了在误标签的检测过程中,提出的算法相比于对比算法更具有鲁棒性。
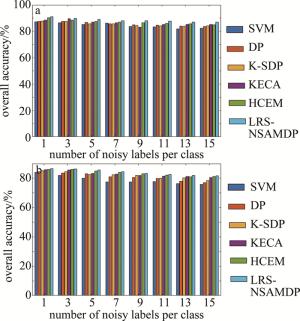
Figure 8. OA obtained by using different false label detection algorithms in different training sets
-
表 5中给出本方法在两个数据集上所有检测失败的不确定样本数,检测失败的不确定样本造成检测算法的误差。其中, 6×13表示在训练样本中所有的不确定样本数目,6表示每一类中的不确定样本数目,13表示类的数目(实验数据重复5次求得平均值), 其它类推。首先明显看出,本算法所有检测失败的不确定样本相比于DP算法和K-SDP算法检测失败的不确定样本数目少,证明本算法检测性能优越。仍然会出现检测误差的原因主要还是算法本身造成的。(12)式采用简单的线性阈值决策函数,该函数可能会导致无法准确度量、检测、去除临界值附近的待检测样本,造成系统误差。此外,本算法采用改进SAM算法来衡量光谱相似度和利用光谱信息,在检测过程中并没有利用到遥感图像的空间信息, 这也会造成系统误差, 可以采取自适应调节的软阈值决策函数、联合样本之间的空间上下文信息等来减少系统误差。另一方面,测量仪器、设备装置和环境会导致随机误差, 可以通过增加求平均值的次数以及使用最小二乘法求得最优值来减少随机误差。但是随机误差仍是不可以避免的。
Table 5. Detection performance of false labels for the proposed method on two datasets
dataset KSC PaviaU total uncertain samples 6×13 9×13 12×13 10×9 15×9 20×9 undetected false samples DP 7.4 6.8 5.7 21.7 21.1 20.7 K-SDP 6.1 5.4 4.8 20.4 18.2 17.8 LRS-NSAMDP 5.6 4.4 3.8 17.6 15.8 14.1 -
针对传统的基于有监督的误标签检测算法检测到的误标签过多而导致后续分类精度下降的问题,提出了一种基于低秩稀疏表示和改进光谱角制图的高光谱图像误标签分类算法。提取原始高光谱图像的低秩成分,使用基于归一化的光谱角制图算法计算光谱相似度。所提出的算法相比于其它误标签检测算法,去除了原始高光谱图像中的混合噪声,降低了阈值λρj的大小,从而使误标签数目变小。实验结果表明,与其它先进的误标签检测算法相比,本算法提高了分类精度。
低秩稀疏和改进SAM的高光谱图像误标签检测
False label detection in hyperspectral image based on low rank sparse and improved SAM
-
摘要: 为了解决基于监督学习的高光谱图像分类算法训练样本中存在的噪声标签会降低后续的分类精度的问题, 采用了一种基于低秩稀疏表示和改进光谱角制图(SAM)的高光谱图像误标签检测算法。首先对高光谱图像中信号子空间进行预测, 根据预测到的子空间对原始高光谱图像重构并去噪; 然后通过基于归一化的光谱角制图算法来获取每一类样本间的距离信息, 得到每类样本间的光谱相似度, 并利用密度峰值聚类算法得到每个训练样本的局部密度; 最后采用基于局部密度的决策函数对噪声标签进行检测, 使用支持向量机在两个真实数据集上验证。结果表明, 该算法比先进的层次结构的高光谱图像误标签检测算法提高了1.91%的总体精度。这一结果对高光谱图像分类是有帮助的。Abstract: In order to solve the problem that reduction of the subsequent classification accuracy in the hyperspectral image classification algorithm based on supervised learning due to the presence of noise labels in the training samples, a false label detection algorithm based on low rank sparse representation and improved spectral angle mapping (SAM) was adopted. Firstly, the signal subspace of hyperspectral image was predicted, and the original hyperspectral image was reconstructed and denoised according to the predicted subspace. Next, the normalized spectral angle mapping algorithm was used to obtain the distance information between each class of samples, and the spectral similarity between each class of samples was obtained. Then, the density peak clustering algorithm was used to get the local density of each training sample. Support vector machine was used to verify the results on two real datasets. The experimental results show that the overall accuracy is improved by 1.91% compared with the advanced hierarchical structure of hyperspectral image false label detection algorithm. This result is helpful for hyperspectral image classification.
-
Figure 2. KSC dataset
a—false color image b—ground object truth map c—name of each species
Figure 3. PaviaU dataset
a—false color image b—ground object truth map c—name of each species
Figure 4. On KSC dataset, the parameter θ and λ coefficient of different local densities λ impact on OA
Figure 5. On PaviaU dataset, the parameter θ and λ coefficient of different local densities λ impact on OA
Figure 6. Feature classification map (25T+5U) obtained by different algorithms in KSC dataset
a—SVM, OA: 85.20% b—DP, OA: 87.04% c—K-SDP, OA: 86.41% d—KECA, OA: 86.72% e—HCEM, OA: 87.90% f—LRS-NSAMDP, OA: 88.51%
Figure 7. Feature classification map (50T+10U) obtained by different algorithms in PaviaU dataset
a—SVM, OA: 75.63% b—DP, OA: 79.01% c—K-SDP, OA: 80.44% d—KECA, OA: 81.43% e—HCEM, OA: 82.72% f—LRS-NSAMDP, OA: 83.28%
a—KSC b—PaviaU
Figure 8. OA obtained by using different false label detection algorithms in different training sets
Table 1. Umber of false labels in each class detected by different detection algorithms under different uncertain samples
 下载: 导出CSV
下载: 导出CSV
Table 2. Classification performance of KSC dataset under the false labeles detected by different distance measurement algorithms
下载: 导出CSV
Table 3. Classification accuracy under different false label algorithms on KSC dataset
class number of true samples anduncertain samples 25T+5U 25T+15U SVM DP K-SDP KECA HCEM LRS-NSAMDP SVM DP K-SDP KECA HCEM LRS-NSAMDP scrub 93.53 95.30 95.04 93.29 92.87 96.44 96.11 95.73 95.30 93.38 87.79 96.83 will-S 79.86 83.77 81.30 85.60 89.90 88.49 77.02 74.53 76.62 79.93 86.39 88.27 cabb-H 91.84 84.55 83.43 82.76 83.67 78.18 86.19 84.34 85.04 81.06 84.16 70.89 cabb-O 58.72 64.64 64.31 62.60 61.99 65.89 56.02 57.00 56.64 60.02 54.48 57.89 slash-P 51.88 61.92 62.86 62.45 63.28 58.04 57.14 57.82 57.34 56.72 75.00 51.57 broad 51.72 57.08 59.27 55.13 54.59 75.09 36.10 48.74 53.65 57.81 51.60 67.20 hardwood 56.83 70.00 64.99 66.96 65.14 84.38 53.19 65.48 66.03 60.36 64.65 76.47 graminoid 82.58 78.09 77.49 80.34 78.24 89.57 52.58 69.17 73.83 80.82 89.49 77.63 spartina 89.27 84.96 86.89 89.07 92.67 92.52 88.55 82.63 87.10 86.75 87.52 88.94 cattail 80.85 92.55 88.93 94.48 100.00 90.96 83.21 87.27 88.86 94.13 91.72 89.93 salt 86.72 87.33 91.52 92.60 94.29 94.89 97.78 90.71 90.95 90.83 90.59 95.49 muld 83.62 90.24 94.40 93.48 84.92 91.45 82.76 87.10 85.11 92.81 84.88 93.05 water 99.18 96.62 99.50 99.60 100.00 98.79 100.00 98.65 99.0 98.07 96.33 98.87 OA/% 83.57 85.47 86.19 86.67 87.52 89.43 79.90 82.60 84.97 85.19 85.23 86.49 AA/% 77.43 80.54 80.76 81.42 81.66 84.98 74.36 76.86 79.35 79.44 80.35 81.00 kappa 0.8171 0.8381 0.8460 0.8514 0.8607 0.8821 0.7766 0.8062 0.8325 0.8349 0.8345 0.8493
下载: 导出CSV
Table 4. Classification accuracy of PaviaU dataset with different false label algorithms
class number of true samples anduncertain samples 50T+10U 50T+20U SVM DP K-SDP KECA HCEM LRS-NSAMDP SVM DP K-SDP KECA HCEM LRS-NSAMDP asphalt 89.43 95.72 97.09 93.83 80.57 96.25 88.69 89.63 92.52 95.94 95.82 96.51 meadows 93.05 93.80 94.03 94.66 95.72 97.43 92.46 92.64 93.69 92.78 93.71 92.91 gravel 57.31 58.11 60.86 60.75 57.14 61.38 56.47 56.90 57.10 65.44 58.16 67.37 trees 71.22 75.79 80.51 73.04 88.67 86.84 67.07 70.52 72.58 81.67 78.59 89.60 M-sheets 85.51 94.23 95.41 86.01 99.10 98.35 84.50 88.67 89.40 81.22 86.05 81.48 B-soil 57.34 56.00 59.96 66.78 44.17 47.28 48.12 49.53 56.25 50.86 60.03 60.64 bitumen 48.44 43.99 52.73 51.71 56.16 58.94 46.09 40.77 48.89 67.86 70.43 68.52 self-Bricks 77.10 74.95 80.00 75.89 81.17 83.28 71.47 73.33 76.47 59.66 56.37 66.26 shadows 83.26 74.66 95.89 88.34 83.01 93.82 87.30 77.30 92.22 70.53 69.26 70.19 OA/% 76.73 78.91 79.55 81.11 82.25 83.49 72.46 75.27 76.32 76.53 78.12 81.42 AA/% 73.84 73.93 79.50 76.77 76.19 80.40 71.96 73.70 75.93 74.00 74.27 77.05 kappa 0.7135 0.7187 0.7542 0.7577 0.7601 0.7783 0.6649 0.6772 0.6973 0.6982 0.7158 0.7551
下载: 导出CSV
Table 5. Detection performance of false labels for the proposed method on two datasets
dataset KSC PaviaU total uncertain samples 6×13 9×13 12×13 10×9 15×9 20×9 undetected false samples DP 7.4 6.8 5.7 21.7 21.1 20.7 K-SDP 6.1 5.4 4.8 20.4 18.2 17.8 LRS-NSAMDP 5.6 4.4 3.8 17.6 15.8 14.1
下载: 导出CSV
-
[1] ZHANG L, WEI W, ZHANG Y N, et al. Cluster sparsity field: An internal hyperspectral imagery prior for reconstruction[J]. International Journal of Computer Vision, 2018, 126(8): 797-821. doi: 10.1007/s11263-018-1080-8 [2] LI Sh T, HAO Q N, GAO G H, et al. The effect of ground truth on performance evaluation of hyperspectral image classification[J]. IEEE Transactions on Geoence & Remote Sensing, 2018, 56(12): 7195-7206. [3] PARK B, LU R F. Hyperspectral imaging technology in food and agriculture[M]. New York, USA: Springer, 2015: 305-331. [4] RUITENBEEK F, DEBBA P, MEER F D, et al. Mapping white micas and their absorption wavelengths using hyperspectral band ratios[J]. Remote Sensing of Environment, 2006, 102(3/4): 211-222. [5] HU Y F, ZHANG Q L, ZHANG Y Z, et al. A deep convolution neural network method for land cover mapping: A case study of Qinhuangdao, China[J]. Remote Sensing, 2018, 10(12): 2053. doi: 10.3390/rs10122053 [6] GUAN Sh H, YANG G, LI H, et al. Hyperspectral image classification based on 3-D convolutional recurrent neural network[J]. Laser Technology, 2020, 44(4): 485-491(in Chinese). [7] ZHANG X G, GAO Z Y, JIAO L C, et al. Multifeature hyperspectral image classification with local and nonlocal spatial information via markov random field in semantic space[J]. IEEE Transactions on Geoence & Remote Sensing, 2018, 56(3): 1409-1424. [8] FANG L Y, HE N J, LI Sh T, et al. A new spatial-spectral feature extraction method for hyperspectral images using local covariance matrix representation[J]. IEEE Transactions on Geoence & Remote Sensing, 2018, 56(6): 3534-3546. [9] LU Zh W, FU Zh Y, XIANG T, et al. Learning from weak and noisy labels for semantic segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 39(3): 486-500. [10] FOODY G M. The effect of mis-labeled training data on the accuracy of supervised image classification by SVM[C]// 2015 IEEE International Geoscience and Remote Sensing Symposium (IGARSS). New York, USA: IEEE, 2015: 4987-4990. [11] KANG X D, DUAN P H, XIANG X L, et al. Detection and correction of mislabeled training samples for hyperspectral image classification[J]. IEEE Transactions on Geoence & Remote Sensing, 2018, 56(10): 5673-5686. [12] TU B, ZHOU Ch L, KUANG W L, et al. Hyperspectral imagery noisy label detection by spectral angle local outlier factor[J]. IEEE Geoscience and Remote Sensing Letters, 2018, 15(9): 1417-1421. doi: 10.1109/LGRS.2018.2842792 [13] ALEX R, LAIO A. Clustering by fast search and find of density peaks[J]. Science, 2014, 344(6191): 1492-1496. doi: 10.1126/science.1242072 [14] TU B, ZHANG X F, KANG X D, et al. Density peak-based noisy label detection for hyperspectral image classification[J]. IEEE Transactions on Geoence & Remote Sensing, 2019, 57(3): 1573-1584. [15] TU B, ZHANG X F, KANG X D, et al. Spatial density peak clustering for hyperspectral image classification with noisy labels[J]. IEEE Transactions on Geoscience and Remote Sensing, 2019, 57(7): 5085-5097. doi: 10.1109/TGRS.2019.2896471 [16] TU B, ZHANG Ch L, PENG J, et al. Kernel entropy component analysis-based robust hyperspectral image supervised classification[J]. Remote Sensing, 2019, 11(23): 2823. doi: 10.3390/rs11232823 [17] ZOU Zh X, SHI Zh W. Quadratic constrained energy minimization for hyperspectral target detection[C]//2015 IEEE International Geoscience and Remote Sensing Symposium (IGARSS). New York, USA: IEEE, 2015: 4979-4982. [18] ZHANG Y F, XIE B B, SUN J, et al. A hybrid sparsity and constrained energy minimization detector for hyperspectral images[C]//2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS). New York, USA: IEEE, 2017: 1137-1140. [19] TU B, ZHOU Ch L, LIAO X L, et al. Hierarchical structure-based noisy labels detection for hyperspectral image classification[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2020, 13: 2183-2199. doi: 10.1109/JSTARS.2020.2994162 [20] KIM S J, KOH K, LUSTIG M, et al. An interior-point method for large-scale & 1-regularized least squares[J]. IEEE Journal of Selected Topics in Signal Processing, 2007, 1(4): 606-617. doi: 10.1109/JSTSP.2007.910971 [21] BIOUCAS-DIAS J M, NASCIMENTO J M. Hyperspectral subspace identification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2008, 46(8): 2435-2445. doi: 10.1109/TGRS.2008.918089 [22] KRUSE F A, LEFKOFF A B, BOARDMAN J W, et al. The spectral image processing system (SIPS): Software for integrated analysis of AVIRIS data[J]. Remote Sensing of Environment, 1993, 44(2/3): 145-163. [23] CUI M S, PRASAD S. Class-dependent sparse representation classifier for robust hyperspectral image classification[J]. IEEE Transactions on Geoscience & Remote Sensing, 2015, 53(5): 2683-2695. [24] SU H J, SHENG Y H. Orthogonal projection divergence-based hyperspectral band selection[J]. Spectroscopy and Spectral Analysis, 2011, 31(5): 1309-1313(in Chinese). doi: 10.3964/j.issn.1000-0593(2011)05-1309-05 [25] TU B, YANG X C, LI N Y, et al. Hyperspectral image classification via superpixel correlation coefficient representation[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2018, 11(11): 4113-4127. doi: 10.1109/JSTARS.2018.2866901 [26] MELGANI F, BRUZZONE L. Classification of hyperspectral remote sensing images with support vector machines[J]. IEEE Transactions on Geoscience and Remote Sensing, 2004, 42(8): 1778-1790. doi: 10.1109/TGRS.2004.831865 -
 点击查看大图
点击查看大图
计量
- 文章访问数: 4864
- HTML全文浏览量: 3473
- PDF下载量: 12
- 被引次数: 0
