| Citation: |
XU Yonghao, SONG Biao, CHEN Xiaofan, HUANG Meizhen. Application of micro near infrared spectrometer in measuring sugar content of apple[J]. LASER TECHNOLOGY, 2019, 43(6): 735-740. DOI: 10.7510/jgjs.issn.1001-3806.2019.06.001

|
| [1] |
LU W Zh. Modern near infrared spectroscopy analysis technology[M]. Beijing: China Petrochemical Press, 2007: 1-14(in Chin-ese).
|
| [2] |
SCHMUTZLER M, HUCK C W. Simultaneous detection of total antioxidant capacity and total soluble solids content by Fourier transform near-infrared (FT-NIR) spectroscopy: A quick and sensitive method for on-site analyses of apples[J]. Food Control, 2016, 66:27-37. DOI: 10.1016/j.foodcont.2016.01.026
|
| [3] |
GRASSI S, ALAMPRESE C. Advances in NIR spectroscopy applied to process analytical technology in food industries[J]. Current Opi-nion in Food Science, 2018, 22:17-21. DOI: 10.1016/j.cofs.2017.12.008
|
| [4] |
LI X F, HUANG M Zh, SHI M M. Application of wavelet analysis in measurement of glucose concentration in human serum by short-wave near infrared spectra[J]. Acta Laser Biology Sinica, 2010, 19(1):110-114(in Chinese). http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=jgswxb201001020
|
| [5] |
LIU Y D, XU H, SUN X D, et al. Non-destructive measurement of tomato maturity by near-infrared diffuse transmission spectroscopy[J]. Laser Technology, 2019, 43(1): 25-29(in Chinese). http://d.old.wanfangdata.com.cn/Periodical/jgjs201901006
|
| [6] |
XU X Q, CHEN G, ZHANG H. The development and latest progress of near infrared spectrometer[J]. Anhui Chemical Industry, 2017, 43(4): 7-10(in Chinese). http://www.en.cnki.com.cn/Article_en/CJFDTotal-AHHG201704005.htm
|
| [7] |
YU X Y, LU Q P, GAO H Zh. Current status and prospects of port-able NIR spectrometer[J]. Spectroscopy and Spectral Analysis, 2013, 33(11):2983-2988 (in Chinese). http://cn.bing.com/academic/profile?id=b8fba8b3dc66f657689d7479a1e92a82&encoded=0&v=paper_preview&mkt=zh-cn
|
| [8] |
SHI M M, HUANG M Zh. Design of a small rapid scanning near infrared spectroscopy[J]. Acta Photonica Sinica, 2011, 40(4):591-595(in Chinese). DOI: 10.3788/gzxb20114004.0591
|
| [9] |
ZHAO J W, ZHANG H D, LIU M H. Non-destructive determination of sugar contents of apples using near inf rared diffuse reflectance[J]. Transactions of the Chinese Society of Agricultural Engineering, 2005, 21(3): 162-165(in Chinese).
|
| [10] |
LIU Y D, YING Y B, FU X P. Study on predicting sugar content and valid acidity of apples by near infrared diffuse reflectance technique[J]. Spectroscopy and Spectral Analysis, 2005, 25(11):1793-1796(in Chinese). http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=gpxygpfx200511014
|
| [11] |
WANG J H, HAN D H. Analysis of near infrared spectra of apple ssc by genetic algorithm optimization[J]. Spectroscopy and Spectral Analysis, 2008, 28(10): 2308-2311(in Chinese). http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=gpxygpfx200810022
|
| [12] |
ZHANG H D, ZHAO J W, LIU M H. Near infrared determination of sugar content in apples based on orthogonal signal correction and partial least square(OSC/PLS) method[J]. Food Science, 2005, 26(6): 189-192(in Chinese). http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=spkx200506041
|
| [13] |
LI Y X, ZOU X B, DONG Y. Near infrared determination of sugar content in apples based on GA-iPLS[J]. Spectroscopy and Spectral Analysis, 2007, 27(10): 2001-2004(in Chinese). http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=gpxygpfx200710024
|
| [14] |
LIU Y D, ZHOU Y R. GA-LSSVM based near infrared spectroscopy detection of apple sugar content[J]. Journal of Northwest A&F University (Natural Science Edition), 2013, 41(7):229-234(in Ch-inese). http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=xbnydxxb201307036
|
| [15] |
PEIRS A, SCHENK A, NICOLA B M. Effect of natural variability among apples on the accuracy of VIS-NIR calibration models for optimal harvest date predictions[J]. Postharvest Biology and Technology, 2005, 35(1):1-13. DOI: 10.1016/j.postharvbio.2004.05.010
|
| [16] |
CHEN X, LIU F. Application of MIV method in near infrared analysis of apple TSC[J]. Computers and Applied Chemistry, 2012, 29(7):812-816(in Chinese). http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=jsjyyyhx201207010
|
| [17] |
SUN Y H, LIU Y Y, DING Y Q. Experimental study on near infrared spectroscopy detection of sugar degree of apple[J]. Journal of Food Safety and Quality, 2015(8):3021-3025(in Chinese). http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=spaqzljcjs201508023
|
| [18] |
WANG X D, LIU H, DANG B Sh. Miniature digital micro-mirror device hadamard transform near-infrared spectrometer[J]. Acta Optica Sinica, 2015, 35(5):388-394(in Chinese). http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=gxxb201505052
|
| [19] |
LIU J, CHEN F F, LIAO Ch Sh, et al. A Digital micromirror device-based hadamard transform near infrared spectrometer[J]. Spectroscopy and Spectral Analysis, 2011, 31(10):2874-2878(in Ch-inese). http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=gpxygpfx201110061
|
| [20] |
LEI M, FENG X L, ZHANG X M, et al. Hadamard transform NIR spectroscopy instrument[J]. Modern Scientific Instruments, 2009(4):44-46(in Chinese). http://d.old.wanfangdata.com.cn/Periodical/xdkxyq200904012
|
| [21] |
WANG X M, WANG H F, YAO N F. Parameter optimization of laser displacement sensor based on particle swarm optimization algorithm[J]. Laser Technology, 2018, 42(2): 181-186(in Chin-ese). http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=jgjs201802008
|
| [22] |
JIANG X Sh. Improved particle swarm algorithms for multi-dimensional optimization problems[D]. Hangzhou: Zhejiang Sci-Tech University, 2016: 7-9(in Chinese).
|
| [23] |
HOU Y, ZHAO L, LU H W. Fuzzy neural network optimization and network traffic forecasting based on improved differential evolution[J]. Future Generation Computer Systems, 2018, 81: 425-432. DOI: 10.1016/j.future.2017.08.041
|
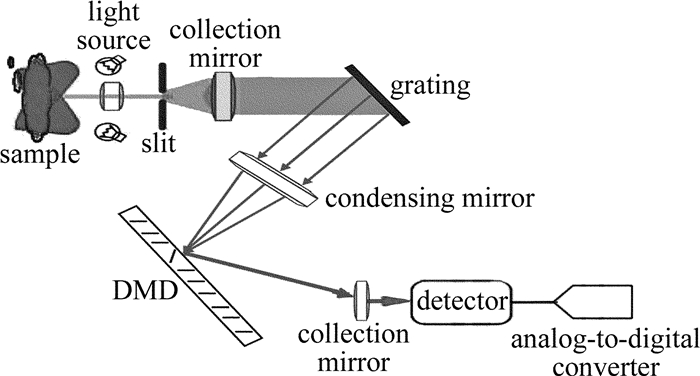
 DownLoad:
DownLoad: