
Herd counting based on VDNet convolutional neural network
-
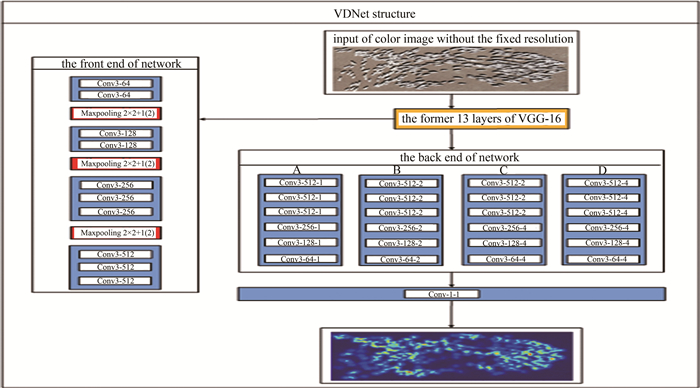
摘要: 为了避免传统羊群计数任务中,羊只之间相互遮挡带来的干扰,提高羊群计数的准确度,采用了视觉几何群(VGG-16)与空洞卷积(DC)相结合的VDNet神经网络羊群计数方法。该方法在网络前端采用去除了全连接层的VGG-16网络提取2-D特征,后端采用6层具有不同空洞率的DC提取更多的高级特征;DC在保持分辨率不变的同时扩大了感受野,替代池化操作,降低了网络的复杂性;最后用一层卷积核大小为1×1的卷积层输出高质量的密度图,通过对密度图像素积分得出输入图片中羊的数量,并进行了理论分析和实验验证。结果表明,VDNet的平均绝对误差为2.51,均方误差为3.74,平均准确率为93%。这一结果对羊群计数任务是有帮助的。Abstract: In order to avoid the interference of mutual occlusion between sheep in the traditional flock counting task and improve the accuracy of flock counting, the VDNet(VGG-16+DC net) convolutional neural network flock counting method, combining visual geometry group(VGG) 16 and dialated convolution (DC) net, was adopted. VGG-16 with the fully connected layer removed was used at the front end of the network to extract 2-D features, 6 layers of DC with different dilated rates was used to extract more advanced features. DC expanded the receptive field, replaced the pooling operation, and decreased the complexity of the network while kept the resolution unchanged at the same time. The theoretical analysis and experimental verification were carried out. Finally, a convolutional layer with a convolution kernel size of 1×1 was used to output a high-quality density map, and then the number of sheep in the input image was obtained by integrating the pixels of the density map. The results show that the average absolute error of the counting method in this paper is 2.51, the mean square error is 3.74, and the average accuracy is 93%, respectively. This result is helpful for the task of counting sheep.
-
Keywords:
- image processing /
- sheep count /
- dilated convolution /
- convolutional neural network
-
引言
光声成像是过去20年来新兴的一种生物医学成像模态[1-6],它是一种光激发的混合成像模式,将光学成像和超声成像的优点结合了起来。一方面,在光声成像中用来重建图像的信号是超声信号,生物组织对超声信号的散射要比光学信号低2~3个数量级,因此相比纯光学成像,光声成像具有更深的成像深度和更高的空间分辨率;另一方面,光声成像根据不同组织对可见光、近红外光的选择性吸收,利用特定波长的激光脉冲对组织进行照射,成像的是在生物组织内被吸收的激光脉冲能量的分布,其一定程度上反映组织的吸收系数分布,这在纯超声成像中是无法做到的,因此相比纯超声成像,光声成像具有更高的光学对比度。
目前光声成像系统逐步向实时[7-9]、多维度[10-11]方向发展,因此采用单通道、单超声换能器系统由于存在系统鲁棒性差,需进行多次调整,单切面扫描时间过长等问题已不能够适应最新的发展趋势,所以必须研发能够高速多通道采集光声信号的高鲁棒性光声成像系统。而国际上已有很多开展在体光声断层成像方面的研究[12-21], 这些研究中成像系统的实现方式和目的各有不同,有的采用线性阵列[12, 15-17],有的主要开展离体的成像实验[13-14]; 参考文献[18]中主要针对光声显微成像方面; 参考文献[19]中采用的是一个垂直放置的弧形的换能器阵列,需要旋转成像对象才能获得3维的图像; 参考文献[20]和参考文献中采用弧形换能器阵列开展实时在体实验,但是由于其激光是垂直激发成像对象即正交模式,所以只适合小动物脑部成像,不适合断层成像;参考文献[7]和参考文献[8]中专门设计用于开展临床实验。因此本文中采用背向传输模式, 即超声换能器阵列与脉冲激光在同一侧, 这样就保证了在成像不同断层时不会对成像对象带来影响, 同时利用美国国家仪器公司(Naticmal Instruments, NI)的数据采集模块和多通道弧形聚焦换能器来构建多通道采集模块以实现光声断层成像数据的高速采集, 最后利用正则化优化的基于模型的重建算法对原始数据进行高质量的图像重建。
1. 理论分析
1.1 光声成像前向模型
光声信号的产生是由于短时脉冲激光照射生物组织,组织中的吸收体吸收一部分能量使得局部温度升高,导致发生热弹性膨胀,从而产生超声波。在满足热力限制和应力限制的条件下,声压p(r, t)满足的关系[22]:
\begin{array}{l} \frac{{{\partial ^2}p(\mathit{\boldsymbol{r}}, t)}}{{\partial {t^2}}} - {c^2}\left( \mathit{\boldsymbol{r}} \right)\rho \left( \mathit{\boldsymbol{r}} \right)\nabla \cdot \\ \left[ {\frac{1}{{\rho \left( \mathit{\boldsymbol{r}} \right)}}\nabla p(\mathit{\boldsymbol{r}}, t)} \right] = \mathit{\Gamma }\frac{{\partial H(\mathit{\boldsymbol{r}}, t)}}{{\partial t}} \end{array} (1) 式中,r为3维空间内的位置坐标; t表示时间; c(r)和ρ(r)分别为组织的声速和密度; Γ为无量纲格鲁内森参量; H(r, t)是热源函数,代表单位时间、单位体积内的热量。假设生物组织的密度是均匀的,即在成像区域内ρ(r)是常数,并假设声速是均匀的,即c(r)为常数c,另外热源函数还可以表示为H(r, t)=H(r)×H(t),其中H(r)表示单位体积内沉积的热能量,H(t)表示脉冲激光光强随时间的分布函数。在实际成像过程中脉冲激光脉宽很短,理论上光强函数可假设为一个脉冲函数,即H(t)=δ(t),因此(1)式可表示为:
\frac{{{\partial ^2}p(\mathit{\boldsymbol{r}}, t)}}{{\partial {t^2}}} - {c^2}{\nabla ^2}p(\mathit{\boldsymbol{r}}, t) = \mathit{\Gamma }H\left( \mathit{\boldsymbol{r}} \right)\frac{{\partial \delta \left( t \right)}}{{\partial t}} (2) (2) 式可以等价地表示为一个初始值问题:
\frac{{{\partial ^2}p(\mathit{\boldsymbol{r}}, t)}}{{\partial {t^2}}} - {c^2}{\nabla ^2}p(\mathit{\boldsymbol{r}}, t) = 0 (3) 初始条件为:
\left\{ \begin{array}{l} p(\mathit{\boldsymbol{r}}, t)\left| {_{t = 0} = \mathit{\Gamma }H\left( \mathit{\boldsymbol{r}} \right)} \right.\\ \frac{{\partial p(\mathit{\boldsymbol{r}}, t)}}{{\partial t}}\left| {_{t = 0} = 0} \right. \end{array} \right. (4) 上述初始值问题可以通过求解一个泊松类型的积分[23]而得到一个解析解:
p(\mathit{\boldsymbol{r}}, t) = \frac{\mathit{\Gamma }}{{4{\rm{ \mathit{ π} }}c}}\;\frac{\partial }{{\partial t}}\int_{S'\left( {\mathit{\boldsymbol{r}}, t} \right)} {\frac{{H\left( {\mathit{\boldsymbol{r'}}} \right)}}{{\left| {\mathit{\boldsymbol{r}} - \mathit{\boldsymbol{r'}}} \right|}}} {\rm{d}}S'(\mathit{\boldsymbol{r}}, t) (5) 式中,积分的对象是一个半径为|r-r′|=ct的球形表面S′(r, t),在2维平面即断层平面,所有的光声信号源和测量点位于同一平面,此时积分是沿着半径为|r-r′|=ct的圆周L′(t)开展,忽略(5)式中的常数,光声断层成像的前向模型可表示为:
p(\mathit{\boldsymbol{r}}, t) = \frac{\partial }{{\partial t}}\int_{L'\left( t \right)} {\frac{{H\left( {\mathit{\boldsymbol{r'}}} \right)}}{{\left| {\mathit{\boldsymbol{r}} - \mathit{\boldsymbol{r'}}} \right|}}} {\rm{d}}L'(t) (6) 1.2 基于模型的逆向重建
光声断层重建算法主要分为3种:第1种是基于雷登变换的滤波反投影重建算法; 第2种是基于时间反转方法的重建算法; 第3种是基于模型的重建算法。滤波反投影算法虽然实现容易且重建速度很快,但是其重建图像含有条状伪影而影响图像质量。时间反转方法虽然通过反向模拟超声波传播来得到更好质量的重建图像,但是这个过程需要复杂的数值仿真,不适合实时成像的要求。而基于模型的重建算法是在采集的声压信号数据和组织的吸收分布之间建立一种线性映射关系,继而通过最优化方法去最小化采集的声压信号与利用模型计算的声压信号之间的误差。因而具有很强的灵活性,且模型矩阵只与所使用的图像网格和信号采集系统的参量有关,而与实际的成像对象无关。
在基于模型的光声断层重建算法中,第1步是计算模型矩阵,需要用到导数的数值近似表示,因此(6)式可近似表示为:
p(\mathit{\boldsymbol{r}}, t) \approx \frac{{I\left( {\mathit{\boldsymbol{r}}, t\Delta t} \right) - I\left( {\mathit{\boldsymbol{r}}, t - \Delta t} \right)}}{{2\Delta t}} (7) 式中, 采用的是导数的中间差分近似。I(r, t)为:
I\left( {\mathit{\boldsymbol{r}}, t\Delta t} \right) = \int_{L'\left( t \right)} {\frac{{H\left( {\mathit{\boldsymbol{r'}}} \right)}}{{\left| {\mathit{\boldsymbol{r}} - \mathit{\boldsymbol{r'}}} \right|}}} {\rm{d}}L'(t) (8) 第2步就是计算(8)式,方法有很多[24-25]。最后(8)式和(9)式可以表示为:
\mathit{\boldsymbol{p}} = \mathit{\boldsymbol{Ax}} (9) 式中,p∈Rm为向量化表示的超声换能器阵元采集到的声压信号, x∈Rn为向量化表示的吸收分布,也即初始声压分布,A∈Rm×n是模型矩阵或系统矩阵,表示一个线性算子描述组织的光学吸收分布与换能器探测的声压信号数据之间的关系。
基于模型的重建算法可以分为两类,第1类是通过求解(10)式最小二乘问题的算法,成为朴素算法,其解称为朴素解:
{\mathit{\boldsymbol{x}}_{{\rm{native}}}} = \mathop {{\rm{argmin}}}\limits_x \left\| {\mathit{\boldsymbol{p}} - \mathit{\boldsymbol{Ax}}} \right\|_2^2 (10) 式中,xnaive为最终求解的朴素解。
第2类算法为基于正则化的算法,由于基于模型的光声断层图像重建问题通常是病态的,因此朴素解与精确解之间通常有较大的偏离,为了获得更好的近似解,需要使用各种正则化项,比如Tikhonov正则化、稀疏正则化、全变分正则化等。
2. 系统实现
2.1 硬件系统
整个系统的硬件组成示意图如图 1所示。光声断层成像系统的激发脉冲激光器采用的是德国INNOLAS公司生产的掺钕钇铝石榴石(Nd: YAG)激光器,该激光器分成两部分:前部分为抽运源,抽运波长为532nm,输出能量为400mJ,重复频率为10Hz,脉冲宽度为4ns~8ns; 后部分为光学参量振荡器(optical parametric oscillator, OPO)可调谐激光器,波长调谐范围为680nm~960nm的红光及近红光波段,在750nm时,输出能量超过80mJ。其余还有耦合透镜、耦合光纤和10根光线束。
超声换能器采集硬件局部放大图如图 2a所示。超声换能器采用的是法国IMASONIC公司的定制中心频率是5MHz,带宽为80%,覆盖角度为270°的128阵元弧形聚焦换能器,结构图如图 2b所示,每个阵元的结构图如图 3a所示。聚焦的半径为40mm,阵元的高度为15mm,相邻阵元之间的间隔为0.1mm。在成像水箱中,通过一个具有四肢的夹具把换能器夹住,使之水平放置。而换能器夹具的上下面各有5个可以放置耦合光纤端头的楔形槽,上面5个楔形槽均匀分割整个圆周,下面的5个楔形槽与上面相应位置的楔形槽堆成,且每个楔形槽与水平放置的换能器成一定角度,而每一个耦合光纤端头把耦合进来的激光整形为线光源,这样就把线光源均匀地照射到换能器的聚焦平面内。
![Figure 3. Schematic of transducer element and simulated cross-sectional view of spatial response for the transducer]() Figure 3. Schematic of transducer element and simulated cross-sectional view of spatial response for the transducer
Figure 3. Schematic of transducer element and simulated cross-sectional view of spatial response for the transducer如图 2a所示,成像小鼠通过悬挂臂支撑系统垂直固定,在实际在体的成像试验中,小鼠先涂上超声耦合胶,之后体表面覆盖一层薄膜与水隔离,最后在小鼠嘴部通过麻醉系统设置好麻醉。竖直的悬挂臂被固定在水平横梁上,而水平横梁与机械垂直升降台融为一体通过直线电机如图 1所示。这里采用直线电机是为了减少电磁干扰对采集系统的噪声影响。之后机械垂直升降台通过直线电机的上下运动来达到控制成像小鼠采集不同的断层切片。图 3b中描绘了此超声换能器仿真的声场图。可以看到, 成像平面是一个直径近似为20mm、厚度为0.7mm的圆盘,此圆盘切片保证了系统在进行断层成像时的特异性。
超声换能器采集的128通道超声信号通过基于NI的采集模块进行处理。具体是工控机机箱采用的是NI的配有8个插槽和高带宽背板的PXIe-1082,每个插槽都可以插入PXI Express模块,且含有一个系统定时同步插槽。主机采用的是NI的基于Intel core i7-3610QE处理器的高性能嵌入式控制器PXIe-8135, 负责协调整个采集过程,这样就不用在需要额外的计算机。定时和同步模块采用的是NI的PXIe-6674T, 用于同步脉冲激光器触发信号和多通道采集模块。采集处理模块采用的是NI FlexRIO硬件,其为NI LabVIEW现场可编程门阵列(field-programmable gate array, FPGA)提供灵活且可定制的I/O。此硬件包含两部分,分别是4个FPGA模块PXIe-7965R和4个提供高性能模拟和数字I/O的适配器模块NI 5752。NI 5752为32通道数字化适配器模块,分辨率为12位,采样频率为50MS/s,另外还含有抗混叠滤波器和可编程时变增益控制,这样就可以在模数转换过程中对微弱的光声信号进行高频滤波和增益放大,以增大信号的信噪比。这两部硬件共同构成一个可重新配置的子系统,通过LabVIEW FPGA软件进行编程。
2.2 软件系统
整个采集系统的软件流程图如图 4所示。
首先, 脉冲激光器的同步触发信号给到PXIe-6674T,之后同步FlexRIO硬件采集数据,每个通道采集的数据会以一个一个64位的先进先出(first-in and first-out, FIFO)的数据结构通过直接内存访问(direct memory access, DMA)传输到内存,不需要经过控制器干预,然后再对数据进行处理,处理的数据可以一边进行实时显示,一边存储到硬盘进行后期重建。采集系统的前面板界面如图 5所示。
3. 成像实验
为了对整个光声断层成像系统进行验证,首先进行了系统的空间分辨率验证实验。利用水笔芯进行成像,水笔芯的内壁厚度为90mm,图 6a为成像结果图中通过水笔芯圆心的整个水平像素点特性曲线,图 6b为第2个峰值信号的局部放大图。在该峰值的一半处宽度测量为200μm,根据参考文献[26]中所述方法,一般来说,成像对象的大小近似为该物体真实大小和系统空间分辨率大小的平方和的平方根,即2002=902+r2,其中r为空间分辨率,所以该系统的空间分辨率约为180μm。
之后进行了离体成像实验。离体的实验对象是一个柱状模拟样品,用5%的琼脂粉和80%的去离子水经过搅拌均匀加热到透明状的液体后,再冷却到常温后加入15%的脂肪乳搅拌均匀,之后取一柱状容器,容器内固定两个六边形柱体模具,间隔为5mm,最后把混合液倒入容器内凝固形成一含有两个六边形柱体模具空腔的模拟样品仿体,再在空腔内注射黑色墨水,进行断层成像。激发波长为750nm,每次断层采集平均20次用于对原始数据进行去噪,一次采集长度为2600个点,图 7a为超声换能器第1个阵元采集的原始光声信号曲线。可以看到, 除有效信号外,噪声的幅值很小,这也说明了该光声断层成像采集系统具有很好的噪音抑制能力。重建算法采用的是正则化优化的基于模型的光声重建算法,结果图如图 7b所示。图像像素个数为256×256,每个像素的大小为0.1mm。可以看出, 重建结果中断层截面上两个六边形非常清楚。
![Figure 6. a—characteristic curve of horizontal pixel point in the reconstruction result of pen core b—partial enlargement of the second peak signals of Fig. 6a]() Figure 6. a—characteristic curve of horizontal pixel point in the reconstruction result of pen core b—partial enlargement of the second peak signals of Fig. 6a
Figure 6. a—characteristic curve of horizontal pixel point in the reconstruction result of pen core b—partial enlargement of the second peak signals of Fig. 6a![Figure 7. a—signal plot of 1# transducer b—the reconstructed photoacoustic tomography image of two hexagonal prisms]() Figure 7. a—signal plot of 1# transducer b—the reconstructed photoacoustic tomography image of two hexagonal prisms
Figure 7. a—signal plot of 1# transducer b—the reconstructed photoacoustic tomography image of two hexagonal prisms最终成像系统是为了能够开展小动物在体实验,所以又进行了在体小动物成像实验。实验对象为6周的BALB/c雄性裸鼠,在裸鼠体表涂上超声耦合胶用来保证声速的匹配,之后通过薄膜包裹保证实验中与水隔离。再把裸鼠嘴部接入异氟烷和氧气混合的麻醉气体,最后固定在小鼠固定支架上,激发波长为750nm,采集点数和采集平均次数分别为20和2600。通过控制直线电机的运动来采集裸鼠不同的断层数据。重建算法采用的是正则化优化的基于模型的光声重建算法,结果图如图 8b所示。可以看到,小鼠的肝部和脊柱都非常清晰,且重建图像内部非常均匀,伪影很少,另外裸鼠的皮肤与内脏的边界也很清晰,图 8a是裸鼠在该成像位置对应的组织切片图。重建图像的结果与组织切片图很吻合。图像像素个数为256×256,每个像素的大小为0.1mm。该试验很好地验证了该断层成像系统可以用来开展在体的小动物光声断层成像研究。
4. 结论
模拟样品和小鼠在体的成像实验结果均表明, 该断层成像系统可以用于开展小动物光声断层成像实验研究。另外该断层成像系统在采集一个断层数据且采集平均次数为20次时所耗费的时间为1.04ms,正则化优化的基于模型的光声重建算法在重建一个断层的数据且重建图像像素个数为256×256时所消耗的时间为40s左右,其中30s为系统矩阵的计算,剩余10s为重建图像的迭代计算。所以该断层成像系统可以高速采集断层数据,近实时地进行高质量的图像重建。后期计划对算法进行图形处理器加速以进一步缩短重建时间,使之达到实时。另外由于脉冲激光器为可调谐激光器,波长在红光和近红外波段连续可变,所以还可以进行多光谱成像,进而对组织中的血红蛋白和光声造影剂进行光谱分离,以提升该系统的科研应用价值。
-
![]()
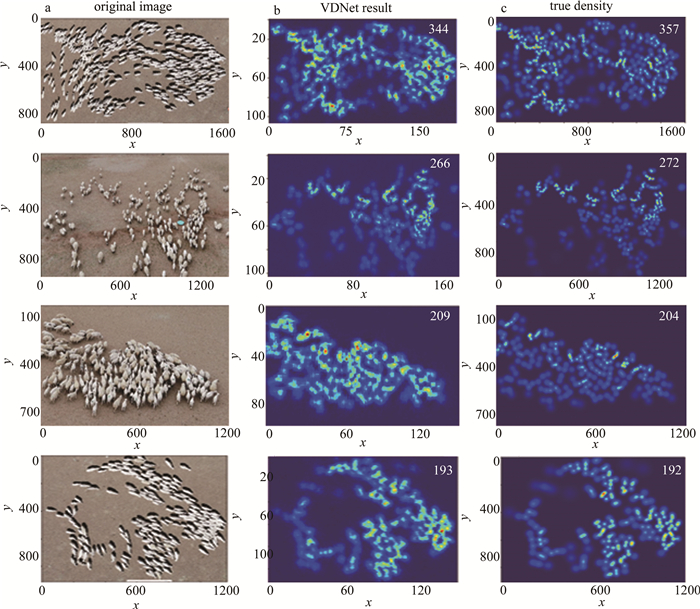
Figure 4. Experimental result from thm first image to the forth image
a—orginal image b—VDNet output result c—truth density map
![]()
Figure 5. Experimental result from the fifth image of the eighth image
a—orginal image b—VDNet output result c—truth density map
Table 1 Experimental comparison
method MAE MSE old method 10.05 13.37 the method in this paper 2.51 3.74  下载: 导出CSV
下载: 导出CSV
-
[1] TIAN L. Design of sheep number detection system[D]. Hohhot: Inner Mongolia University, 2019: 45-57(in Chinese).
[2] ZHANG L, XU J, TIAN Z, et al. Research and implementation of intelligent counting sheep system in pastoral areas[J]. Telecom Power Technologies, 2017, 34(4): 165-166(in Chinese). http://en.cnki.com.cn/Article_en/CJFDTotal-TXDY201704069.htm
[3] ENZWEILER M, GAVRILA D, GAVRILA D M. Monocular pedestrian detection: Survey and experiments[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2009, 31(12): 2179-2195. DOI: 10.1109/TPAMI.2008.260
[4] JONES M J, SNOW D. Pedestrian detection using boosted features over many frames[C]// International Conference on Pattern Recognition. New York, USA: IEEE, 2008: 8-11.
[5] WU B, NEVATIA R. Detection and tracking of multiple, partially occluded humans by bayesian combination of edgelet based part detectors[J]. International Journal of Computer Vision, 2007, 75(2): 247-266. DOI: 10.1007/s11263-006-0027-7
[6] FELZENSZWALB P F, GIRSHICK R B, McALLESTER D, et al. Object detection with discriminatively trained part-based models[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2010, 32(9): 1627-1645. DOI: 10.1109/TPAMI.2009.167
[7] LIU T, TAO D. On the robustness and generalization of cauchy regression[C]// 2014 4th IEEE International Conference on Information Science and Technology (ICIST). New York, USA: IEEE, 2014: 32-37.
[8] ZHAI J Y, TU L Zh, ZHUANG Y. Saliency detection based on boundary prior and adaptive region merging[J]. Computer Engineering and Applications, 2018, 54(6): 178-182(in Chinese). http://en.cnki.com.cn/Article_en/CJFDTotal-JSGG201806029.htm
[9] ZENG L, XU X, CAI B, et al. Multi-scale convolutional neural networks for crowd counting[C]// 2017 IEEE International Conference on Image Processing (ICIP). New York, USA: IEEE, 2017: 89-91.
[10] HUANG S Y, LI X, CHENG Zh Q, et al. Stacked pooling: Improving crowd counting by boosting scale invariance[J]. Computer Vision and Pattern Recognition, 2018(22): 46-52. http://arxiv.org/abs/1808.07456
[11] ZHANG Y, ZHOU D, CHEN S, et al. Single-image crowd counting via multi-column convolutional neural network[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York, USA: IEEE, 2016: 98-103.
[12] WU X, ZHENG Y, YE H, et al. Adaptive scenario discovery for crowd counting[J]. Computer Vision and Pattern Recognition, 2019(9): 12-16. http://ieeexplore.ieee.org/document/8683744
[13] OORO-RUBIO D, LÓPEZ-SASTRE R J. Towards perspective-free object counting with deep learning[C]// European Conference on Computer Vision(ECCV) 2016. New York, USA: IEEE, 2016: 56-64.
[14] LEI H L. Crowd counting algorithm based on multi model deep convolution network fusion[D]. Hohhot: Inner Mongolia University, 2020: 32-37(in Chinese).
[15] TANG S Y, TAO Y, ZHANG L L, et al. A deep crowd counting algorithm based on multi-column feature map fusion. Journal of Zhengzhou University (Natural Science Edition), 2018, 50(2): 69-74(in Chinese).
[16] WANG Y J, ZHANG W, LIU Y Y, et al. Two-branch fusion network with attention map for crowd counting[J]. Neurocomputing, 2020, 411: 1-8. DOI: 10.1016/j.neucom.2020.06.034
[17] WANG S, LU Y, ZHOU T, et al. SCLNet: Spatial context learning network for congested crowd counting[J]. Neurocomputing, 2020, 404: 227-239. DOI: 10.1016/j.neucom.2020.04.139
[18] WU X, ZHENG Y, YE H, et al. Counting crowds with varying densities via adaptive scenario discovery framework[J]. Neurocomputing. 2020, 397: 127-138. DOI: 10.1016/j.neucom.2020.02.045
[19] LI Y, ZHANG X, CHEN D. CSRNet: Dilated convolutional neural networks for understanding the highly congested scenes[J]. Computer Vision and Pattern Recognition, 2018 (27): 31-39. http://ieeexplore.ieee.org/document/8578218
[20] SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[J]. Computer Vision and Pattern Recognition, 2014(4): 19-25. http://arxiv.org/abs/1409.1556
[21] ZHANG C, LI H, WANG X, et al. Cross-scene crowd counting via deep convolutional neural networks[C]// 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York, USA: IEEE, 2015: 17-29.
-
期刊类型引用(2)
1. 吴明埝,沈一春,陈青青,王道根,李松林,谢书鸿,尹建华,徐拥军. 基于多分类高斯SVM的光纤信号的模式识别方法. 激光技术. 2025(01): 128-134 .  本站查看
本站查看
2. 孙强,郝敏. 基于CenterNet的草原牛羊计数研究. 现代计算机. 2023(11): 1-8 . 百度学术
其他类型引用(7)










计量
- 文章访问数: 7
- HTML全文浏览量: 1
- PDF下载量: 4
- 被引次数: 9