
Unsupervised band selection algorithm combined with K-L divergence and mutual information
-
摘要: 波段选择是重要的高光谱图像降维手段。为了达到降维的目的,提出结合K-L散度和互信息的无监督波段选择算法,并进行了理论分析和实验验证。首先选出信息熵最大的波段作为初始波段,然后将散度与互信息量的比值定义为联合散度互信息(KLMI)准则,选择KLMI值大且信息量也大的波段加入波段子集中,选出信息量大且相似度低的波段集合,最终利用k最近邻分类算法实现了基于最大方差主成分分析算法、聚类算法、互信息算法和本文中方法的真实高光谱数据分类实验。结果表明,本文中的算法总体分类精度和κ系数均达到0.8以上,高于其它算法;大多数地物的分类精度均得到提升,具有较好的分类性能。该算法是一种实用的高光谱图像降维算法。Abstract: Band selection is an important method of dimensionality reduction of hyperspectral images. In order to reduce the dimensionality, an unsupervised band selection algorithm combining K-L divergence and mutual information was proposed. And theoretical analysis and experimental verification were carried out. Firstly, the band with the largest information entropy was selected as the initial band. Then, the ratio of divergence to mutual information was defined as the criterion of joint K-L divergence mutual information (KLMI). The band which has large KLMI and information entropy was selected to band subset. Then bands with large information and low similarity were obtained. Finally, the real hyperspectral data classification experiments based maximum-variance principle component analysis (MVPCA), affinity propagation (AP), mutual information (MI) and the proposed method were realized by using k-nearest neighbor classifier. Experimental results show that, the accuracy of the proposed algorithm is higher than that of other algorithms. The overall classification accuracy and kappa coefficient κ are over 0.8. Classification accuracy of the most objects is improved. The proposed method has outstanding performance on classification and is a practical dimensionality reduction algorithm of hyperspectral image.
-
Keywords:
- remote sensing /
- band selection /
- K-L divergence /
- mutual information /
- classification
-
0. 引言
红外成像是将景物辐射或反射的红外光线进行光电转换从而成像,广泛应用于军事、医疗和灾备等领域,但是红外图像往往会存在亮度较暗和对比度较低的不足,降低了红外图像的应用效果[1]。因此,红外图像增强非常必要,以此来改善其亮度和对比度。改善红外图像效果的方法总体上包括直方图映射类方法、基于Retinex颜色恒常性理论的方法和基于学习框架类的增强方法[2]。全局直方图均衡能大大地拉伸图像的对比度,但是对于平滑区域会出现过度增强、而对微小细节区域的增强不足。为了在提升全局对比度的同时,又能改善微小细节的效果,ABHISEK等人[3]提出了一种增强红外图像的方法,其基于平台阈值的直方图均衡化,对平滑区域的直方图进行裁剪,而对微小细节区域的直方图进行补偿。LI等人[4]提出基于自适应阈值裁剪的双平台直方图均衡化,但是平台阈值的确定缺乏鲁棒性,对于不同的图像难以确定最优的平台阈值。为了限制图像的过度增强效果,PAUL等人[5]提出一阵基于自适应限幅的双子直方图均衡算法,但是对图像的亮度和对比度的改善不明显。CHEN等人[6]将高斯差分滤波器与平台直方图结合,更好地提升图像的对比度和显著化边缘信息。YAN等人[7]将红外图像划分为前景和背景两部分,然后分别进行全局直方图均衡增强,虽然对微小细节有一定的增强效果,但是依然无法避免过度增强。SRINIVAS等人[8]采用Hopfield神经网络结构计算能量曲线,将能量曲线分为3个区域,然后分别进行均衡化处理。
Retinex理论认为,图像可分解为低频和高频部分,可根据各自的特征分别进行处理。GU等人[9]根据亮通道先验和Retinex模型将红外图像分解为基础图像和细节图像,用引导滤波和全变分平滑算子去除块效果,保持图像的局部平滑,而根据细节变化先验对细节图像进行锐化。LUO等人[10]将图像分解为多尺度的低频图像和高频图像,而对多尺度的低频图像进行伽马校正,改善图像的亮度和对比度。对图像的低频进行伽马校正能改善图像的亮度,但对图像的细节增强不明显。CHENG等人[11]将图像拆分为入射光部分和反射光部分,用平台直方图均衡增强入射光部分,而对反射图像进行对比度和细节增强,然后将入射光部分与反射光部分融合,但是所采用的多种增强技术以及融合处理,均固定参数不变,缺乏鲁棒性。
近年来,深度学习被广泛应用于红外图像处理中。FAN等人[12]设计一种突出红外图像的前景目标而抑制背景噪声的卷积神经网络,但是通过仿真对训练数据集进行扩充,在一定程度上失去了深度学习的意义。在参考文献[13]中,KUANG等人采用条件生成对抗网络,以进一步优化图像增强效果,但是在可见光图像上进行训练的模型,难以适用于红外图像。PANG等人[14]设计了红外细节增强子网络和全局内容不变子网络,在避免局部过增强的同时,增强图像的深度细节特征和保持图像的空间结构。参考文献[15]中建立了一种用于红外图像增强的渐进融合网络,利用红外光场图像之间丰富的角度视觉来探索和融合红外增强图像的辅助信息。基于深度学习的红外图像增强方法虽然能在一定程度上改善图像的效果,但是受限于红外图像数据集,缺乏鲁棒性,对于不同的图像数据,其效果差异较大[16-18]。
为了克服现有红外图像增强方法的缺陷,在避免过增强的同时,更好地提高红外图像的质量,本文作者提出了融合线性变换与局部均衡的红外图像增强方法。对红外图像分别进行自适应的分段线性变换和局部直方图均衡,然后对两张增强图像进行金字塔分解和对应的加权融合,获得最终的增强图像。实验数据以主、客观的方式证明了所提出的方法优于现有方法。
1. 理论分析
本文中方法的步骤为:先对红外图像分别进行自适应的分段线性变换增强和局部直方图均衡增强,再根据对比度特征、显著性特征和亮度分布特征分别计算两张增强图像的权重图,然后以拉普拉斯金字塔和高斯金字塔的方式,分别对增强图像和权重图进行分解,最后将分解的图像与对应的权重图进行多尺度的线性融合,获得效果理想的红外图像。
1.1 自适应的分段线性变换
分段线性变换压缩分布较少的像素所占的灰度级区间,而拉伸分布较多的像素所占的灰度级区间,从而实现像素对灰度级空间的近似均匀分布,一方面改善图像的亮度,另一方面改善图像的对比度。令I(x)为红外图像I中灰度为x的像素,图像的灰度级数为L,灰度级x的动态范围为[0, L-1],像素的分段线性变换方法见下。
(a) 获取图像I的直方图h :
\boldsymbol{h}=\{h(x) \mid h(x)=\operatorname{count}(\boldsymbol{I}=x)\} (1) 式中:h(x)表示灰度值x对应的直方图中的值;count(I=x)表示统计图像I中灰度级为x的像素数。
(b) 对直方图进行累计求和并进行归一化,H(x)表示灰度级x对应于向量H中的值:
\begin{gathered} \boldsymbol{H}=\{H(x) \mid H(0)=h(0), \\ H(x)=H(x-1)+h(x)\} \end{gathered} (2) \boldsymbol{H}=\frac{\boldsymbol{H}}{H(L-1)} (3) (c) 为了保证绝大部分的像素尽可能均匀地分布于灰度级空间,将灰度级的映射目标范围[0, L-1]的5%和95%区间分点分别作为映射范围的上、下分段点:
y_1=\operatorname{round}(5 \% \times L)-1 (4) y_2=\operatorname{round}(95 \% \times L)-1 (5) 式中:round(·)为四舍五入取整函数。
(d) 将直方图累计频次为5%和95%对应的灰度级分别作为原图像灰度级的上、下分段点:
x_1=\underset{x \in[0, L-1]}{\arg }(H(x) \leqslant 0.05<H(x+1)) (6) 或
x_1=\underset{x \in[0, L-1]}{\arg }(H(x)<0.05 \leqslant H(x+1))+1 (7) x_2=\underset{x \in[0, L-1]}{\arg }(H(x) \leqslant 0.95<H(x+1)) (8) 或
x_2=\underset{x \in[0, L-1]}{\arg }(H(x)<0.95 \leqslant H(x+1))+1 (9) 式中:由于存在临界取值,根据H(x)=0.05还是H(x+ 1)=0.05,分段点x1分别有两种定义式;同样的,根据H(x)=0.95还是H(x+1)=0.95,分段点x2也分别有两种定义式。
(e) 分段线性变换。对红外图像I中灰度级为x的像素I(x)分段线性变换,可定义为:
I(x)=\left\{\begin{array}{l} \frac{y_1}{x_1} x, \left(x<x_1\right) \\ y_1+\frac{y_2-y_1}{x_2-x_1}\left(x-x_1\right), \left(x_1 \leqslant x \leqslant x_2\right) \\ y_2+\frac{(L-1)-y_2}{(L-1)-x_2}\left(x-x_2\right), \left(x_2<x\right) \end{array}\right. (10) 分段线性变换的效果如图 1所示。将处于灰度级区间[x1, x2]的近90%的像素,根据灰度级的相对距离,重新分布于较大的灰度级区间[y1, y2],而将处于区间[0, x1]和[x2, L-1]中少数的像素,根据灰度级的相对距离,重新分布于较窄的区间[0, y1]和[y2, L-1]。分段线性变换将图像的像素在整个灰度级动态空间进行近似均匀的重分布,从而改善图像的亮度和对比度。
1.2 局部直方图均衡化
一般地,统一的直方图均衡能明显地拉大图像的对比度,但是会产生过度增强和增强不足。为克服此缺陷,部分学者对直方图均衡方法进行改进,将图像划分为子图像块,分别进行直方图均衡化,但是会产生放大噪声,同时会产生块状效应。于是本文作者提出了局部直方图均衡化方法:对每一像素I(x),令Nx(k)为以I(x)为中心的、大小为k×k的邻域;对邻域Nx(k)中的像素进行直方图均衡化,像素I(x)取对应直方图均衡化后的像素值。方法的具体步骤见下。
(a) 对每一像素I(x),分别统计邻域Nx(k)的最小灰度值m、最大灰度值M和直方图hx:
\left\{\begin{array}{l} m=\min \left(N_x(k)\right) \\ M=\max \left(N_x(k)\right) \end{array}\right. (11) \begin{gathered} h_x(x-m)=\operatorname{count}\left(N_x(k)=x\right) \\ (x=m, \cdots, M) \end{gathered} (12) 式中:min(·)和max(·)分别取元素的最小和最大值。
(b) 对直方图hx进行均衡化:
\begin{gathered} \boldsymbol{H}_x=\left\{H_x(y) \mid H_x(0)=h_x(0)\right. \\ \left.H_x(y)=H_x(y-1)+h_x(y)\right\} \\ (y=0, \cdots, M-m) \end{gathered} (13) (c) 对均衡化后的直方图Hx进行归一化:
\boldsymbol{H}_x=\frac{\boldsymbol{H}_x}{H_x(M-m)} (14) (d) 对像素I(x)进行灰度映射变换:
I(x)=m+H_x(x-m) \times(M-m) (15) 步骤(a)中参数k的取值,在一定程度上影响局部对比度的提升:取值过大,微小的边缘细节得不到有效增强;取值过小,整体对比度的提升不明显。本文中通过实验的综合比较,取k=13为最优值。
1.3 多尺度的金字塔分解与融合
分段线性变换从像素分布上提升了图像的整体对比度,但是对局部的微小细节往往增强不足;而局部直方图均衡化能改善微小细节的对比度,但是对全局对比度的改善尚有欠缺。为了在改善红外图像的全局对比度的同时,局部细节也能得到清晰显示,分别对线性变换的增强图像和局部直方图均衡化增强的图像,根据对比度、显著性和亮度的权重图进行多尺度的金字塔融合,获得最终的增强图像。令线性变换的增强图像和局部直方图均衡化的增强图像分别为Il和Ih。
1.3.1 权重图的计算
对比度权重矩阵采用拉普拉斯滤波FL的绝对值进行计算。下标t分别是l, h。
\boldsymbol{w}_{c, t}=\left|F_{\mathrm{L}}\left(\boldsymbol{I}_t\right)\right| (16) 基于对比度权重矩阵的图像融合,可以突出显示对比度较大的像素信息。
显著性权重定义为图像的平均值与高斯平滑滤波FG图像的绝对残差图像:
\boldsymbol{w}_{\mathrm{s}, t}=\left|\operatorname{mean}(\boldsymbol{I})-F_{\mathrm{G}}\left(\boldsymbol{I}_t\right)\right| (17) 基于显著性权重矩阵的图像融合,可以强调像素的显著性特征。
一般地,效果理想的红外图像的亮度均值为灰度级范围的中值。亮度权重矩阵采用图像与理想亮度的差值的指数函数进行计算:
\boldsymbol{w}_{\mathrm{h}, t}=\exp \left[-\frac{\left(\boldsymbol{I}_t-0.5\right)^2}{2 \operatorname{var}\left(\boldsymbol{I}_t\right)}\right] (18) 式中:var(·)表示求方差。基于亮度权重的图像融合,通过权重强调亮度适应的像素在结果图像中的作用,而削弱亮度较大或较小的像素的作用,可以有效调节图像的亮度。
增强图像Il和Ih的归一化权重图分别为:
\boldsymbol{W}_1=\frac{\sum\limits_{r \in\{\mathrm{c}, \mathrm{~s}, \mathrm{~h}\}} \boldsymbol{w}_{r, \mathrm{l}}}{\sum\limits_{r \in\{\mathrm{c}, \mathrm{~s}, \mathrm{~h}\}} \sum\limits_{t \in\{1, \mathrm{~h}\}} \boldsymbol{w}_{r, t}} (19) \boldsymbol{W}_{\mathrm{h}}=\frac{\sum\limits_{r \in\{\mathrm{cs, }, \mathrm{~h}\}} \boldsymbol{w}_{r, \mathrm{~h}}}{\sum\limits_{r \in\{\mathrm{c}, \mathrm{~s}, \mathrm{~h}\}} \sum\limits_{t \in\{1, \mathrm{~h}\}} \boldsymbol{w}_{r, t}} (20) 1.3.2 权重图的高斯金字塔分解
高斯金字塔分解以原图像的高斯滤波图像为第1层,后续迭代地对图像进行下采样和高斯滤波,每一次的下采样和高斯滤波的结果为一层,直到获得指定层次的金字塔图像。
对权重图Wt进行n层的高斯金字塔分解的具体过程为:
\boldsymbol{T}_{\boldsymbol{W}, t}(1)=\boldsymbol{W}_t (21) \boldsymbol{P}_{W, t}(1)=F_{\mathrm{G}}\left(\boldsymbol{T}_{W, t}(1)\right) (22) …
\boldsymbol{T}_{\boldsymbol{W}, t}(l)=S_{\mathrm{DS}}\left(\boldsymbol{T}_{\boldsymbol{W}, t}(l-1)\right), (2 \leqslant l \leqslant n) (23) \boldsymbol{P}_{W, t}(l)=F_{\mathrm{G}}\left(\boldsymbol{T}_{W, t}(l)\right), (2 \leqslant l \leqslant n) (24) 式中:SDS为下采样;TW,t(l)为下采样金字塔;PW,t(l)为高斯分解的权重图金字塔。
1.3.3 增强图像的拉普拉斯金字塔分解
\boldsymbol{T}_{I, t}(1)=\boldsymbol{I}_t (25) \boldsymbol{P}_{I, t}(1)=F_{\mathrm{G}}\left(\boldsymbol{T}_{I, t}(1)\right) (26) …
\boldsymbol{T}_{I, t}(l)=S_{\mathrm{DS}}\left(\boldsymbol{T}_{I, t}(l-1)\right), (2 \leqslant l \leqslant n) (27) \boldsymbol{P}_{I, t}(l)=F_{\mathrm{G}}\left(\boldsymbol{T}_{I, t}(l)\right), (2 \leqslant l \leqslant n) (28) \begin{aligned} \boldsymbol{P}_{I, t}(l)= & \boldsymbol{P}_{I, t}(l)-S_{\mathrm{US}}\left(\boldsymbol{P}_{I, l}(l+1)\right), \\ & (1 \leqslant l \leqslant n-1) \end{aligned} (29) 式中:SUS为上采样;PI,t(l)为拉普拉斯分解的图像金字塔。
1.3.4 图像的加权融合
\boldsymbol{f}(l)=\sum\limits_{t \in\{1, \mathrm{~h}\}} \boldsymbol{P}_{W, t}(l) \times \boldsymbol{P}_{I, t}(l), (1 \leqslant l \leqslant n) (30) 1.3.5 图像的金字塔重构
迭代执行:
\begin{gathered} \boldsymbol{f}(l-1)=\boldsymbol{f}(l-1)+S_{\mathrm{US}}(\boldsymbol{f}(l)) \\ (l=n, n-1, \cdots, 2) \end{gathered} (31) 迭代最后输出的f (1)为金字塔融合的增强图像。
2. 实验验证
实验环境为I7 CPU和32G内存,以相关参考文献[5, 7, 11, 14]中提出的方法作为实验参照。分别根据增强图像的视觉感知效果和增强图像的客观质量指标,以主、客观的方式,证明本文中方法的实用性和优越性。实验素材来源于数据集OTCBVS Benchmark Dataset,其中包含室内和室外的红外图像、近景和远景的红外图像。
2.1 增强图像的视觉效果
各方法对5个场景红外图像的增强结果如图 2所示。各方法均能在不同程度上改善红外图像的效果。
参考文献[5]中为限幅的直方图均衡化方法,在保持较亮的前景部分基本不变的情况下,而对较暗的背景部分的对比度有一定程度的改善,但是效果不明显,将直方图分为前景的直方图和背景的直方图,分别进行限幅的直方图均衡化,虽然具有一定的自适应性,且避免了图像的过增强,但是欠增强效果较明显,图像暗区域的增强效果非常有限,图像的整体亮度较暗。参考文献[7]中在方法原理上类似于参考文献[5],将红外图像分为前景部分与背景部分,分别进行直方图均衡化,但是不进行限幅操作;从增强图像上看,参考文献[7]中最明显的特点就是对比度较大,但是因其不进行直方图限幅,在前景部分产生过增强,且部分暗处的图像信息未能得到有效的增强。参考文献[11]中将红外图像分为光照部分和细节部分,分别对其进行平台直方图均衡化和对比度拉伸,基本上避免了图像的过增强,但是增强图像的亮度整体偏低;对部分图像的增强效果较好,比如图 2d2和图 2d3,对于其余图像的对比度增强不足,在部分暗区域产生欠增强,部分图像信息未能正常显示。参考文献[14]中为基于内容和细节深度学习的图像增强方法,从其增强图像可以看出,图像的前景部分会产生失真的效果,比如图 2e1的裤子和图 2e2的车头部分,而背景的对比度较低、雾霾效果比较明显。因为根据可见光图像进行学习训练,导致其难以完全适用于红外图像。
相对地,采用本文中的方法对红外图像增强后,亮度较为适宜,对比度较大,图像暗处的信息得到了有效的增强,前景和背景的场景信息均得到较明显的增强。本文中的方法将自适应的分段线性变换和局部直方图均衡化的增强结果进行了多尺度的金字塔融合,除了图 2f2的车头部分和图 2f5的右下角产生少部分过增强效果之外,本文中方法的增强性能相对于现有方法有一定的优势。
2.2 增强图像的质量指标
本文中采用信息熵[19]、平均梯度[20]和变异系数(coefficient of variation, CV)[21]作为增强图像的质量指标,对增强图像进行评价。信息熵度量图像的有效信息量越大,图像的信息含量越大;平均梯度度量图像的对比度越大,图像的对比度越大;变异系数反映像素的离散程度,值越大,图像的边缘细节越清晰。
对应于图 2,采用各方法对5个场景红外图像进行增强后的信息熵、平均梯度和变异系数分别如表 1~ 表 3所示。
表 1 增强图像的信息熵Table 1. Entropy of enhanced images表 2 增强图像的平均梯度Table 2. Average gradient of enhanced image表 3 增强图像的变异系数Table 3. Coefficient of variation of enhanced images根据表 1中增强图像的信息熵可以看出,参考文献[5]中对原图像的信息熵的提升不明显,未能明显增加图像的有效信息含量;参考文献[7]中对各图像增强后的信息熵较大,明显提升图像的信息含量;而参考文献[11]和参考文献[14]中信息熵次之,两者的信息熵相差不大,但次于参考文献[7]和本文中方法。相对地,本文中方法的信息熵最大,能更有效地增加图像的有效信息含量。
采用各方法对不同场景的红外图像进行增强处理后,所获得的平均梯度如表 2所示。很明显,参考文献[5]和参考文献[14]中的平均梯度较小,对图像对比度的改善不明显;而参考文献[11]中的平均梯度比参考文献[5]和参考文献[14]要大,但是相对原图像的平均梯度,提升的幅度依然不明显;参考文献[7]中和本文中的方法平均梯度较大,能明显地提升图像的对比度,但是参考文献[7]在前景部分会产生过增强,破坏部分图像信息,因此其平均梯度小于本文中方法。
采用各方法对红外图像增强后的变异系数如表 3所示。由比较可知,参考文献[14]中的变异系数较小,增强图像的边缘细节信息较模糊;参考文献[5]中的变异系数相对于原图像提升的幅度也不明显,所以难以有效地显示边缘和细节信息;参考文献[7]和参考文献[11]中的变异系数较大,两者相差不大,能在较大程度上改善图像的边缘细节的清晰度。相对地,本文中方法获得的变异系数更大,能更有效地提升图像的边缘细节的清晰度。
以上增强图像的视觉感知效果以及增强图像的信息熵、平均梯度和变异系数,均证明了本文中的方法能更理想地提升红外图像的质量,更能显著化红外图像的边缘和细节。
3. 结论
为了更有效地改善红外图像的效果,提出了融合线性变换和局部均衡的方法。对红外图像分别进行自适应的分段线性变换和局部直方图均衡,然后对增强图像进行多尺度的金字塔融合。实验数据显示,本文中的方法能规避图像的过度增强,而且能较理想地改善图像的亮度、对比度和边缘细节的清晰度,具有更好的红外图像增强效果。改善提出方法的计算逻辑、降低方法的计算复杂度,是课题组下一步的研究方向。
-
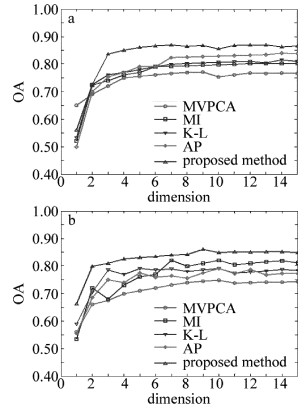
![]()
Figure 3. Overall classification accuracy of different samples with various bands
a—5% samples b—10% samples
Table 1 Comparison of band selection results and information
band selection algorithm MVPCA MI AP K-L proposed algorithm band selection results 8, 20, 36, 62, 63, 69, 70, 72, 92, 95 9, 32, 30, 23, 13,89, 57, 97, 100, 110 112, 113, 31, 114, 121,125, 156, 127, 164, 51 15, 49, 33, 87, 21, 63, 101, 99, 71, 56 112, 42, 31, 40, 108, 51, 120, 150, 21, 9 sum of entropy 67.1277 67.4139 67.0094 67.1058 67.7815  下载: 导出CSV
下载: 导出CSV
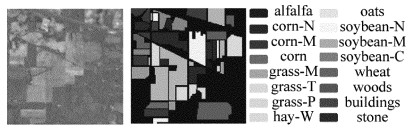
Table 2 Classification accuracy of various types of objects (5% samples)
class training samples test samples MVPCA MI AP algorithm in this paper alfalfa 23 23 0.53 0.43 0.38 0.94 corn-N 34 1394 0.49 0.65 0.64 0.71 corn-M 27 803 0.49 0.55 0.64 0.69 corn 25 212 0.37 0.40 0.47 0.66 grass-M 27 456 0.80 0.83 0.91 0.94 grass-T 26 704 0.90 0.90 0.92 0.99 grass-P 14 14 0.57 0.56 0.86 0.86 hay-W 27 451 0.97 0.98 0.98 1.00 oats 10 10 0.27 0.36 0.60 0.93 soybean-N 30 942 0.62 0.63 0.76 0.84 soybean-M 31 2424 0.64 0.77 0.79 0.81 soybean-C 28 565 0.38 0.52 0.47 0.58 wheat 25 180 0.91 0.89 0.98 0.99 woods 30 1235 0.90 0.93 0.94 0.96 buildings 27 359 0.38 0.53 0.47 0.77 stone 26 67 0.86 0.86 0.90 0.96 OA 0.65 0.71 0.76 0.82 κ 0.61 0.69 0.70 0.81
下载: 导出CSV
Table 3 Classification accuracy of various types of objects (10% samples)
class training samples test samples MVPCA MI AP algorithm in this paper alfalfa 23 23 0.28 0.71 0.7 0.79 corn-N 89 1428 0.64 0.60 0.74 0.74 corn-M 73 830 0.75 0.60 0.71 0.81 corn 66 237 0.49 0.49 0.49 0.64 grass-M 71 730 0.96 0.86 0.88 0.82 grass-T 81 478 0.73 0.92 0.94 0.98 hrass-P 14 28 0.47 0.57 0.83 0.62 hay-W 71 478 0.89 0.96 0.99 0.99 oats 10 10 0.44 0.47 0.58 0.47 soybean-N 76 896 0.76 0.74 0.71 0.72 soybean-M 112 2343 0.66 0.71 0.85 0.87 soybean-C 68 525 0.52 0.47 0.72 0.78 wheat 67 138 0.97 0.93 0.94 0.98 woods 89 1176 0.86 0.90 0.96 0.99 buildings 68 318 0.72 0.45 0.62 0.91 stone 47 46 0.20 0.91 0.88 0.91 OA 0.71 0.72 0.81 0.85 κ 0.63 0.69 0.75 0.82
下载: 导出CSV
-
[1] ZHANG B.Current progress of hyperspectral remote sensing in China[J].Journal of Remote Sensing, 2016, 20(5):1062-1090(in Chinese). http://d.old.wanfangdata.com.cn/Periodical/ygxb201605002
[2] BIOUCAS-DIAS J M, PLAZA A, CAMPS-VALLS G, et al. Hyperspectral remote sensing data analysis and future challenges[J]. IEEE Geoscience & Remote Sensing Magazine, 2013, 1(2):6-36. http://d.old.wanfangdata.com.cn/NSTLQK/NSTL_QKJJ0211502179/
[3] XIANG Y J, YANG G, ZHANG J F, et al.Dimensionality reduction for hyperspectral imagery manifoldlearning based on spectral gradient angles[J].Laser Technology, 2017, 41(6):921-926(in Chinese). http://www.jgjs.net.cn/EN/Y2017/V41/I6/921
[4] QIN F J, ZHANG A W, WANG Sh M, et al.Hyperspectral band selection based on spectral clustering and inter-class separability factor[J].Spectroscopy and Spectral Analysis, 2015, 35(5):1357-1364(in Chinese). http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=gpxygpfx201505047
[5] TAN Y Q.Unsupervised band selection for hyperspectral image based on multiobjective optmization[D].Xi'an: Xidian University, 2014: 19-21(in Chinese).
[6] MYRONENKO A, SONG X. Point set registration:Coherentpoint drifts[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2010, 32(12):2262-2275. DOI: 10.1109/TPAMI.2010.46
[7] CHENG H, WANG Zh Q, ZHANG Y Y.Research on geometric rectification of aerial images[J].Journal of Northeast Normal University, 2009, 41(3):50-54(in Chinese). http://en.cnki.com.cn/Article_en/CJFDTOTAL-DBSZ200903014.htm
[8] BATTITI R. Using mutual information for selecting features in supervised neural net learning[J].IEEE Transactions on Neural Networks, 1994, 5(4):537-550. DOI: 10.1109/72.298224
[9] KWAK N, CHOI Ch H. Improved mutual information feature selector for neural networks in supervised learning[C]//Proceeding of 1999 International Joint Conference on Neural Networks.New York, USA: IEEE, 1999: 1313-1318. https://www.researchgate.net/publication/3839328_Improved_mutual_information_feature_selector_for_neural_networks_in_supervised_learning?_sg=toPsvbZOD3mU5bFfrDR64mBMv1zT_bUfzIMlTAJ3x3aGJDfzLFgyQmcuQUgzz-I8JSuC4epdvbtOj6NdMAeqCg
[10] LIU X S, GE L, WANG B, et al.An unsupervised band selection algorithm for hyperspectral imagery based on maximal information[J].Journal of Infrared and Millimeter Waves, 2012, 31(2):166-176(in Chinese). DOI: 10.3724/SP.J.1010.2012.00166
[11] SHI Y, EBERHART R. A modified particle swarm optimizer[J].IEEE Xplore, 1998, 7803(5):69-73. http://d.old.wanfangdata.com.cn/OAPaper/oai_doaj-articles_cbf9945a97af956bcc6311e3ad1681bc
[12] KULLBACK S. Information theory and statistics[M]. New York, USA:John Wiley and Sons, 1959:55-70.
[13] ZHOU Y, LI X R, ZHAO L Y. Modified linear-prediction based band selection for hyperspectral image[J].Atca Optica Sinica, 2013, 33(8):0828002(in Chinese). DOI: 10.3788/AOS
[14] LANDGREBE D. Multispectral data analysis: A signal theory perspective[R]. West Lafayette, USA: Purdue University, 1998: 56-89.
[15] YANG J, HUA W Sh, LIU X, et al.Band selection algorithm for hyperspectral imagery based on K-L divergence and spectral divisibility distance[J].Journal of Applied Optics, 2014, 35(1):71-75(in Chinese). http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=yygx201401014



计量
- 文章访问数: 10
- HTML全文浏览量: 0
- PDF下载量: 4