
Application of harmonic regeneration noise reduction algorithm in photoelectric musical sound detection
-
摘要:
为了抑制乐音信号光电探测时的系统噪声并保留乐音的音色,提出了一种改进的谐波重构算法来进行降噪处理。首先计算信号的先验信噪比,并在此基础上构建用于降噪处理的维纳滤波器;然后针对乐音信号存在多个谐波分量的特征,提出了一种梳状滤波器的设计方案;对乐音信号功率谱进行逆傅里叶变换后,确定乐音信号在一个基音周期内的采样点数,并将其作为梳状滤波器的节点参数,由此完成乐音信号的谐波增强;通过先验信噪比的计算对降噪效果进行了理论分析,再通过实验验证得到了不同降噪算法的降噪效果。结果表明,该算法能够很好地进行降噪处理,在信噪比为-5 dB、0 dB和5 dB时,相较于传统谐波重构算法而言,降低乐音信号对数频谱畸变的性能提升了50%以上,能够很好地保留乐音信号的音色。该研究为不同类型乐器演奏中的音色分析及评价提供了参考。
Abstract:For the photoelectric detection technology of music signal, an improved harmonic reconstruction algorithm was proposed to reduce the system noise while retaining the timbre of music. Firstly, the priori signal-to-noise ratio of the signal was calculated, and Wiener filter for noise reduction processing was constructed. Then a comb filter design scheme was proposed to address the characteristic of multiple harmonic components in music signals. After performing the inverse Fourier transform on the power spectrum of the music signal, the number of sampling points within one fundamental period of the music signal was determined. The number of samples was used as the node parameter of the comb filter, and the harmonic enhancement of the music signal was thus accomplished. The noise reduction effect was theoretically analyzed through the calculation of the priori signal-to-noise ratio, and then the noise reduction effect of different noise reduction algorithms was obtained through experimental verification. The results show that the algorithm can perform denoising well. Compared with the traditional harmonic reconstruction algorithm, the performance of reducing the log-spectral distortion of music signal is improved by more than 50% when the signal-to-noise ratio is -5 dB, 0 dB and 5 dB, and the timbre of the music signal can be well preserved. This study provides a reference for timbre analysis and evaluation in performances of different types of musical instruments.
-
0. 引言
激光作为载波的光电探测技术具有灵敏度高、探测距离远、抗干扰能力强等多项优势,因而被广泛用于各种信息的探测处理和记录分析中[1-2]。各种音频信号由于谱带宽、谐波信息丰富、信号强度有限等特点,相比传统压电传感技术,使用光电探测方式能够更好地复原其特征,并进行更精确地分析和记录。然而,在信号的光电转换过程中,探测器的内部固有噪声难以通过外部手段消除[3],因此需要后期利用各种降噪算法来提高信号的质量。目前,针对音频信号中的语音增强已开展了一些降噪算法研究,并在语音的可懂度上实现了很好的处理结果[4-6]。相对而言,乐音增强方面却少有研究,因为乐音信号丰富的频谱信息组成了不同的音色[7-9],在信号的记录与噪声处理时,关键是保证频谱的还原程度,这也是难点所在。
在信号处理时, 维纳滤波器[10-13]是最常用的降噪手段。该方法利用信号的先验信噪比构建滤波器的增益系数,再对信号进行降噪处理。在实际应用中,由于信号的先验信噪比通常是未知的,因此各种先验信噪比的估算算法得到了大量使用[14-17]。对于低信噪比条件下具有谐波特性的信号进行增强处理,可采用谐波重构降噪法(harmonic regeneration noise reduction,HRNR)[18-19],通过人为构建谐波信号来影响维纳滤波器的先验信噪比,提高算法的可靠性。然而,光电探测系统的噪声来源和种类较多,尽管HRNR算法对先验信噪比进行了改善,得到的增强信号仍会存在大量残留噪声。这些噪声对高次谐波的影响非常明显,不利于乐音信号的复原。针对这一问题,本文作者提出了一种结合基音检测算法的时域梳状滤波器来增强乐音谐波信号的处理方案,使得维纳滤波器的先验信噪比更加符合乐音特征,降低了噪声对乐音信号音色的影响。
1. 乐音信号的噪声抑制算法
1.1 噪声影响下的乐音信号
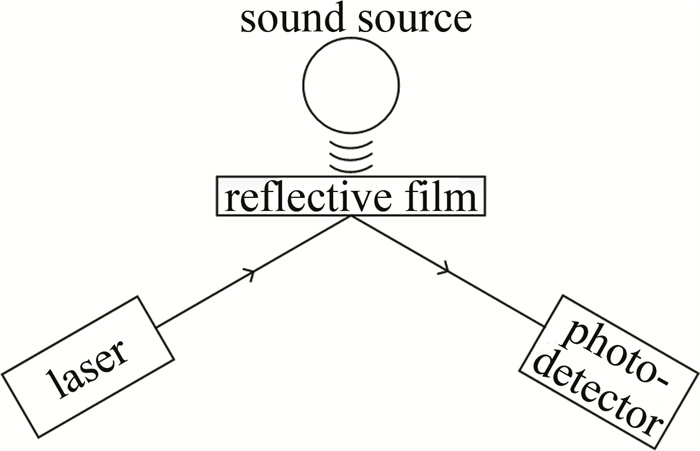
在基音的基础上存在不同的谐波成分,使得各种乐器有了自己独特的音色[7],因此通过频谱分析可对乐器或演奏过程的音色进行分析和评价。信号探测是进行乐音分析的前提,当乐音信号通过振动加载到激光载波上后,光电探测器接收到光束振动信息,并通过光电转换得到对应的电压。探测光路如图 1所示。
当光电探测器获得激光所携带的振动信号后,理论上可在频域对乐音信号进行复原,但是乐音本身是一种线性时变信号,与傅里叶变换所需的平稳信号前提不符。因此,往往需要对其进行分帧处理,即在一段较短的时间内将乐音看作平稳信号,通过一个在时域上可滑动的窗函数对信号进行截取,然后做短时傅里叶变换(short-time Fourier transform,STFT)来完成频谱分析。本文中重点针对探测器在光电转换过程中无法避免的内部固有噪声进行处理,首先通过直流激光信号的探测器输出可以获得噪声分布,然后再分析探测器噪声的处理过程。
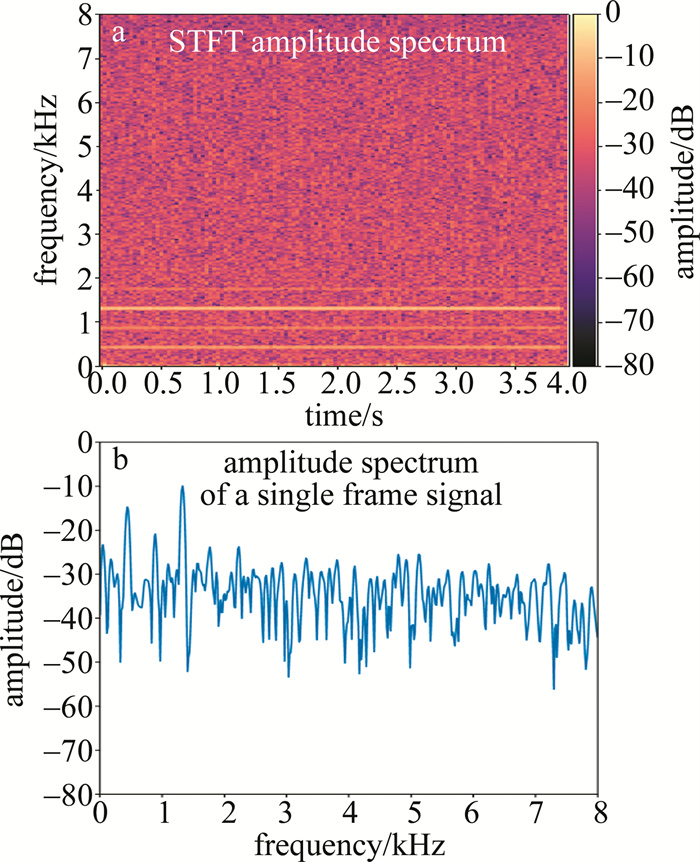
在仿真分析时,将实测噪声信号与一个采样率为16 kHz、持续时间4 s、基音为442 Hz的标准单簧管(clarinet)信号以0 dB的信噪比(signal-to-noise ratio, SNR)进行混合,作为带噪信号。设STFT的窗口长度为1024个点,相邻两帧重叠点数为512,截取窗函数为Hanning窗,可以得到对应124帧信号的强度分布(见图 2a)及起始时间为0.96 s的1帧信号的频谱(见图 2b)。
从图 2可以看到,光电转换过程中的噪声对单簧管的频谱分布造成了极大的干扰,而高频谐波由于本身幅值较低,受到的干扰尤为严重,因此当对该信号进行再现时,音色也将完全被破坏掉。
1.2 维纳滤波降噪原理
维纳滤波是一种常见的信号处理算法,通过信号的先验信噪比构建增益系数,再与信号进行频域相乘来进行降噪处理。其降噪过程可表示为[15]:
\boldsymbol{S}(p, k)=\boldsymbol{H}(p, k) \boldsymbol{Y}(p, k) (1) 式中:S (p, k)为增强信号STFT谱;Y (p, k)为带噪信号STFT谱;H (p, k)为维纳滤波的增益系数,具体表示为:
\boldsymbol{H}(p, k)=\frac{\boldsymbol{\xi}_{\text {prior }}(p, k)}{1+\boldsymbol{\xi}_{\text {prior }}(p, k)} (2) 式中:p为STFT的帧数;k为STFT的频点;ξprior(p, k)为带噪信号的先验信噪比。
另外,为了促使低信噪比下被抑制的谐波成分得到恢复,可利用HRNR算法[18-19]在时域上人为构造一个新的谐波信号。具体过程可表示为:
s_{\mathrm{NL}}(n)=\left\{\begin{array}{l} {\left[a s_{\mathrm{TSNR}}(n)\right]^2, \left(s_{\mathrm{TSNR}}(n) \geqslant 0\right)} \\ -\left[a s_{\mathrm{TSNR}}(n)\right]^2, \left(s_{\mathrm{TSNR}}(n) <0\right) \end{array}\right. (3) 式中:a为常数,通常取值为5[19];sTSNR(n)为经过传统的两步噪声消除法(two-step noise reduction,TSNR)[15]所得到的增强信号在时域上的表示;sNL(n)为sTSNR(n)通过非线性处理后的结果;n为数字信号中离散的第n个抽样点。得到处理结果后,通过半波整流即可获得最终重新构造的谐波信号:
s_{\text {harmo }}(n)=s_{\mathrm{NL}}(n) P\left(s_{\mathrm{NL}}(n)\right) (4) 式中:P(·)为半波整流,目的是获得与基音周期一致的周期方波。
通过上述方式生成的谐波信号虽然并不能直接当成理想信号的估计值,但可以用于改进先验信噪比。在HRNR算法中,先验信噪比可表示为:
\begin{aligned} & \boldsymbol{\xi}_{\mathrm{HRNR}}(p, k)=\left\{\boldsymbol{H}_{\mathrm{TSNR}}(p, k)\left|\boldsymbol{S}_{\mathrm{TSNR}}(p, k)\right|^2+\right. \\ & \left.\left[1-\boldsymbol{H}_{\mathrm{TSNR}}(p, k)\right]\left|\boldsymbol{S}_{\mathrm{harmo}}(p, k)\right|^2\right\} / \boldsymbol{\gamma}(p, k) \end{aligned} (5) 式中:\left|\boldsymbol{S}_{\text {harmo }}(p, k)\right|^2为谐波信号sharmo(n)的功率谱;\left|\boldsymbol{S}_{\mathrm{TSNR}}(p, k)\right|^2是通过TSNR算法得到的增强信号sTSNR(n)的功率谱;HTSNR(p, k)为利用TSNR算法的先验信噪比得到的维纳滤波器增益系数;γ (p, k)为噪声功率谱的估计值。
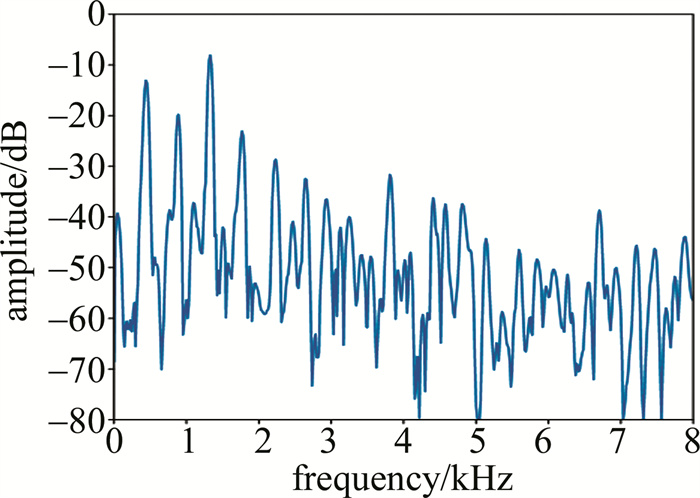
利用HRNR算法的先验信噪比构造维纳滤波器对图 2中的带噪信号进行降噪,得到最终的处理结果在起始时间为0.96 s的1帧信号的频谱, 如图 3所示。由图可见,HRNR算法得到的增强信号仍然存在大量残留噪声,能量较低的高次谐波也没有得到较好的复原。这是由于由TSNR算法得到的增强信号往往本身就包含大量残留噪声,谐波特性已不再明显。尽管式(3)的非线性处理能一定程度上增强信号的谐波分量,但对先验信噪比的影响非常有限。为了克服这一问题,本文作者对HRNR算法进行了改进。
![图 3 HRNR算法降噪后的单帧信号幅度谱]() 图 3 HRNR算法降噪后的单帧信号幅度谱Figure 3. Amplitude spectrum of a single frame signal after noise reduction by HRNR algorithm
图 3 HRNR算法降噪后的单帧信号幅度谱Figure 3. Amplitude spectrum of a single frame signal after noise reduction by HRNR algorithm2. 基于梳状滤波的改进谐波重构降噪算法
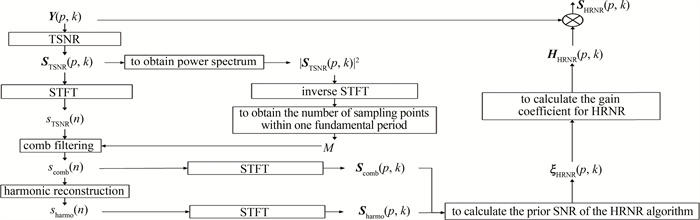
首先通过梳状滤波器[20]对TSNR所得增强信号sTSNR(n)进行处理,然后再进行谐波构造和先验信噪比计算。梳状滤波器的幅频特性呈现出一种类似梳子的结构,这种排列使其能够有效抑制谐波间的残余噪声,从而在整个谱段提高信噪比。将每帧sTSNR(n)信号按照一个基音周期内的采样点数M的长度分割为R段,第r段梳状滤波结果为r段sTSNR(n)信号的平均值,其过程可表示为:
s_{\text {comb }}^{(r)}(n)=\frac{1}{r} \sum\limits_{i=0}^{r-1} s_{\mathrm{TSNR}}^{(r-i)}(n), (r=1, 2, \cdots, R) (6) 式中:s_{\mathrm{TSNR}}^{(r-i)}(n)为每帧sTSNR(n)信号被分割后的第r-i段;scomb(r)(n)为第r段梳状滤波结果;R为每帧sTSNR(n)信号的总分割段数。最后再将这R段梳状滤波结果按顺序拼接, 即可得到每帧sTSNR(n)信号梳状滤波后的结果scomb(n)。
进行梳状滤波的关键是要估计一个基音周期内的采样点数M,本文作者在处理时依次对每帧TSNR增强信号的功率谱进行逆傅里叶变化,从而获取该帧信号在一个基音周期内的采样点数估计值[21];然后对各帧估计值进行统计,将估计次数最多的采样点数设为M。整个降噪流程如图 4所示。
![图 4 基于梳状滤波的改进HRNR降噪算法流程]() 图 4 基于梳状滤波的改进HRNR降噪算法流程Figure 4. Flow chart of the improved HRNR noise reduction algorithm based on comb filter
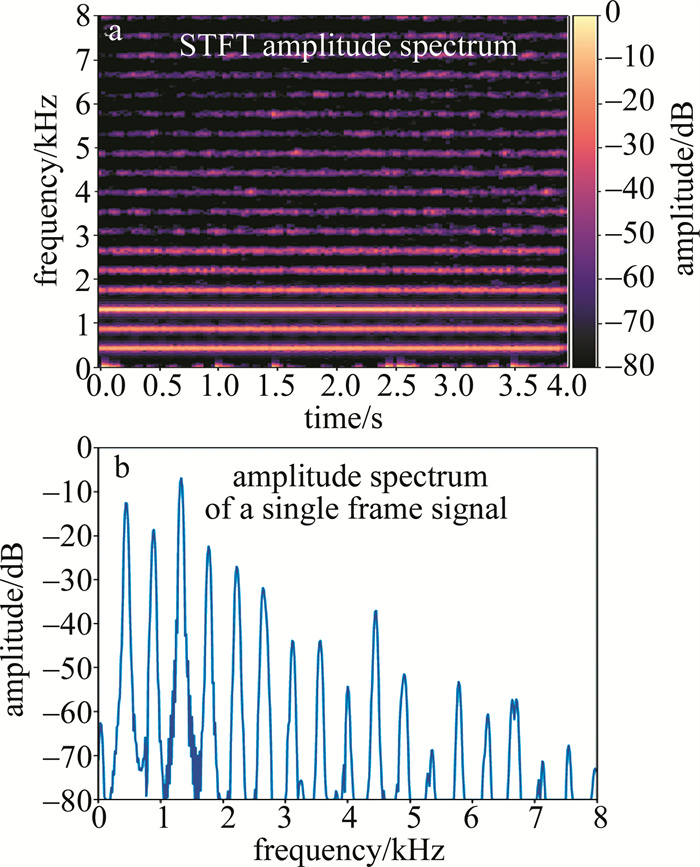
图 4 基于梳状滤波的改进HRNR降噪算法流程Figure 4. Flow chart of the improved HRNR noise reduction algorithm based on comb filter利用上述的改进HRNR算法对图 2中的带噪信号进行降噪,通过计算得到sTSNR(n)信号在一个基音周期内采样点数M=36,将每帧信号的1024个点按36点的长度分割,得到总段数R=29。最终处理结果的强度分布及起始时间为0.96 s的1帧信号的频谱如图 5所示。
![图 5 改进算法降噪后单簧管的幅度谱]() 图 5 改进算法降噪后单簧管的幅度谱Figure 5. Amplitude spectrum of clarinet after noise reduction by the improved algorithm
图 5 改进算法降噪后单簧管的幅度谱Figure 5. Amplitude spectrum of clarinet after noise reduction by the improved algorithm从图 5可以看到,相较于传统HRNR算法,本文中通过梳状滤波后再进行谐波构造和先验信噪比计算的做法显著抑制了各次谐波之间的残留噪声。在TSNR增强信号本身存还在大量残留噪声的情况下,该改进算法仍能较好地恢复乐音信号中幅值较低的高次谐波。
3. 实验及结果分析
为验证改进谐波重构降噪算法的性能,本文中选择了单簧管(clarinet)、竖笛(recorder) 和贝斯(bass) 3种不同的乐器进行降噪处理。这3种乐器具有不同的谐波分量,即音色,同样以-5 dB、0 dB、5 dB的信噪比和光电探测器噪声进行混合得到带噪信号,再分别用TSNR算法、HRNR算法和本文中的算法对带噪信号进行处理,得到对应的增强信号。为了定量比较降噪处理结果,采用了对数频谱畸变(log-spectral distortion,LSD)来反映各算法所得增强信号的频谱失真情况。LSD的表达式为[22]:
\begin{gathered} D= \\ \frac{1}{P} \sum\limits_{p=0}^{P-1} \sqrt{\frac{1}{K / 2+1} \sum\limits_{k=0}^{K / 2}\left[10 \lg \left(\frac{\left|\boldsymbol{S}_{\text {ideal }}(p, k)\right|^2}{\left|\boldsymbol{S}_{\text {enhan }}(p, k)\right|^2}\right)\right]^2} \end{gathered} (7) 式中:Sideal(p, k)为理想乐音信号的STFT谱;Senhan(p, k)为通过降噪处理后的增强乐音信号STFT谱;STFT窗口长度为1024个点,相邻两帧重叠点数为512,截取窗函数为Hanning窗,P为STFT总帧数,共124帧;K为每帧信号进行傅里叶变换的点数,具体取值为1024。LSD反映了增强信号与干净信号之间的频谱差异,其值越小表示两个频谱越相似,即相应增强信号的频谱失真越小。不同算法处理后的单簧管、竖笛和贝斯信号LSD如表 1~表 3所示。
表 1 不同算法处理后的单簧管信号对数频谱畸变Table 1. Log-spectral distortion of clarinet signal processed by different algorithmsinput SNR/ dB noise reduction algorithm the performance improvement percentage of the algorithm presented in this paper compared with the original HRNR/% TSNR/ dB HRNR/ dB the algorithm presented in this paper/dB -5 5.3180 4.6872 2.2289 52.45 0 5.2139 4.6383 2.1577 53.48 5 5.0601 4.5866 2.1107 53.98 表 2 不同算法处理后的竖笛信号对数频谱畸变Table 2. Log-spectral distortion of recorder signal processed by different algorithmsinput SNR/ dB noise reduction algorithm the performance improvement percentage of the algorithm presented in this paper compared with the original HRNR/% TSNR/ dB HRNR/ dB the algorithm presented in this paper/dB -5 5.7524 5.0775 2.4831 51.10 0 5.6642 5.0402 2.4067 52.25 5 5.5301 4.9904 2.3155 53.60 表 3 不同算法处理后的贝斯信号对数频谱畸变Table 3. Log-spectral distortion of bass signal processed by different algorithmsinput SNR/ dB noise reduction algorithm the performance improvement percentage of the algorithm presented in this paper compared with the original HRNR/% TSNR/ dB HRNR/ dB the algorithm presented in this paper/dB -5 5.7562 5.1405 2.4812 51.73 0 5.6787 4.9896 2.3759 52.38 5 5.3730 4.7044 2.1780 53.70 从表 1~表 3可以看到,本文中的改进HRNR算法对乐音信号处理后得到的增强信号在频谱上的对数频谱畸变最小,相较于原HRNR算法而言有明显的提升效果。
作者在同一台电脑、Python编程环境下,分别用原HRNR算法和本文中的改进算法对信噪比为-5 dB、0 dB、5 dB的带噪单簧管、竖笛和贝斯信号处理10次,一共得到90次处理结果。对这90次计算效果进行统计,结果如下:传统的HRNR算法耗时约为0.2830 s,本文中改进算法耗时为0.3056 s,增多了0.0226 s;传统的HRNR算法占用内存约24.5974 Mbyte,本文中改进算法占用内存约25.0435 Mbyte,增多了0.4461 Mbyte。可以看到,本文中的改进算法相较于传统HRNR算法而言,在提高了噪声处理能力的同时,并没有明显增加耗时和资源占用。
4. 结论
采用谐波重构降噪算法计算了维纳滤波器的先验信噪比,再通过维纳滤波器来消除光电乐音探测信号中的噪声。实验中发现:原谐波重构降噪算法处理后得到的乐音增强信号仍存在许多残留噪声。为了进一步减小噪声对乐音音色的影响,本文中对谐波重构降噪算法进行了改进,引入了功率谱2次处理的基音检测方法来获取乐音信号的在一个基音周期内的采样点数,通过梳状滤波器抑制残留噪声,再进行谐波重构和先验信噪比计算;随后对不同信噪比下基音为442 Hz的乐音信号分别采用了TSNR算法、HRNR算法和本文中的改进HRNR算法进行处理,对比了在相同信噪比条件下,不同降噪算法处理后的频谱失真情况。计算结果显示,本文中算法在对有不同谐波成分的乐音均具有更好的重构能力,对数频谱畸变值相对传统HRNR算法下降超过50%。本文作者提出的算法能够很好地完成乐音探测过程中的噪声处理,但由于应用场景重点是在音质的评价上,因此不需要考虑信噪比过低的极端情况。当信噪比降至-22 dB以下时,本文中算法所需的基频信号也将被噪声完全淹没,基音周期便无法利用,则梳状滤波器也无法使用。
-
![]()
图 3 HRNR算法降噪后的单帧信号幅度谱
Figure 3. Amplitude spectrum of a single frame signal after noise reduction by HRNR algorithm
![]()
图 4 基于梳状滤波的改进HRNR降噪算法流程
Figure 4. Flow chart of the improved HRNR noise reduction algorithm based on comb filter
![]()
图 5 改进算法降噪后单簧管的幅度谱
Figure 5. Amplitude spectrum of clarinet after noise reduction by the improved algorithm
表 1 不同算法处理后的单簧管信号对数频谱畸变
Table 1 Log-spectral distortion of clarinet signal processed by different algorithms
input SNR/ dB noise reduction algorithm the performance improvement percentage of the algorithm presented in this paper compared with the original HRNR/% TSNR/ dB HRNR/ dB the algorithm presented in this paper/dB -5 5.3180 4.6872 2.2289 52.45 0 5.2139 4.6383 2.1577 53.48 5 5.0601 4.5866 2.1107 53.98  下载: 导出CSV
下载: 导出CSV
表 2 不同算法处理后的竖笛信号对数频谱畸变
Table 2 Log-spectral distortion of recorder signal processed by different algorithms
input SNR/ dB noise reduction algorithm the performance improvement percentage of the algorithm presented in this paper compared with the original HRNR/% TSNR/ dB HRNR/ dB the algorithm presented in this paper/dB -5 5.7524 5.0775 2.4831 51.10 0 5.6642 5.0402 2.4067 52.25 5 5.5301 4.9904 2.3155 53.60
下载: 导出CSV
表 3 不同算法处理后的贝斯信号对数频谱畸变
Table 3 Log-spectral distortion of bass signal processed by different algorithms
input SNR/ dB noise reduction algorithm the performance improvement percentage of the algorithm presented in this paper compared with the original HRNR/% TSNR/ dB HRNR/ dB the algorithm presented in this paper/dB -5 5.7562 5.1405 2.4812 51.73 0 5.6787 4.9896 2.3759 52.38 5 5.3730 4.7044 2.1780 53.70
下载: 导出CSV
-
[1] 李民. 激光测振在振动计量中的若干技术问题的研究[D]. 杭州: 浙江大学, 2004: 5-14. LI M. Research on several technology problems of low frequency laser vibration measuring system in the field of vibration quantifivation[D]. Hangzhou: Zhejiang University, 2004: 5-14(in Chinese).
[2] 龚靖, 伍波, 万家硕, 等. 基于WDR联合FFT方法的脉冲相干测速精度研究[J]. 激光技术, 2023, 47(1): 92-97. GONG J, WU B, WAN J Sh, et al. Research on the precision of pulse coherent velocimetry based on WDR combined FFT method[J]. Laser Technology, 2023, 47(1): 92-97(in Chinese).
[3] 许根源. 全自动血凝仪的光电检测系统设计与实现[D]. 镇江: 江苏科技大学, 2017: 29-30. XU G Y. Design and realization of photoelectric detection system of automatic blood coagulation instrument[D]. Zhenjiang: Jiangsu University of Science and Technology, 2017: 29-30(in Chinese).
[4] 吴艳. 激光音频信号探测中的噪声抑制[D]. 成都: 四川大学, 2021: 48-60. WU Y. Noise suppression in laser audio signal detection[D]. Chengdu: Sichuan University, 2021: 48-60(in Chinese).
[5] 许春冬, 徐琅, 周滨. 结合优化U-Net和残差神经网络的单通道语音增强算法[J]. 现代电子技术, 2022, 45(9): 35-40. XU Ch D, XU L, ZHOU B. Single channel speech enhancement algorithm combining optimized U-Net and residual network[J]. Modern Electronics Technique, 2022, 45(9): 35-40(in Chinese).
[6] 陈昱帆. 可穿戴式设备多传感器语音增强算法研究[D]. 重庆: 重庆邮电大学, 2022: 46-48. CHEN Y F. Research on multi-sensor speech enhancement algorithm for wearable devices[D]. Chongqing: Chongqing University of Posts and Telecommunications, 2022: 46-48(in Chinese).
[7] 高雨轩. 基于深度学习的音乐音频分类研究[D]. 广州: 华南理工大学, 2020: 7-9. GAO Y X. Research on music audio classification based on deep learning[D]. Guangzhou: South China University of Technology, 2020: 7-9(in Chinese).
[8] 赵庆磊, 邵峰晶, 孙仁诚, 等. 乐器识别中频谱特征与聚合策略性能评估[J]. 青岛大学学报(自然科学版), 2021, 34(2): 38-44. ZHAO Q L, SHAO F J, SUN R Ch, et al. Performance evaluation of spectrum features and aggregation strategies for musical instrument recognition[J]. Journal of Qingdao University (Natural Science Edition), 2021, 34(2): 38-44(in Chinese).
[9] PRABAVATHY S, RATHIKARANI V, DHANALAKSHMI P. Cla-ssification of musical instruments using SVM and KNN[J]. International Journal of Innovative Technology and Exploring Engineering, 2020, 9(7): 1186-1190. DOI: 10.35940/ijitee.G5836.059720
[10] 王佳佳, 周克良. 优化的维纳滤波算法在心音信号中降噪的应用[J]. 沈阳大学学报(自然科学版), 2021, 33(2): 150-154. WANG J J, ZHOU K L. Application of optimized wiener filter algorithm for noise reduction in heart sound signals[J]. Journal of Shenyang University (Natural Science Edition), 2021, 33(2): 150-154(in Chinese).
[11] 潘嘉琦, 曹科才, 丁嘉存, 等. 基于维纳滤波的无人机语音系统的设计与实现[J]. 计算机与数字工程, 2021, 49(10): 2161-2167. PAN J Q, CAO K C, DING J C, et al. Design and implementation of UAV phonetic system based on wiener filtering[J]. Computer and Digital Engineering, 2021, 49(10): 2161-2167(in Chinese).
[12] 王方杰, 金赟. 基于谐波重构滤波的数字助听器语音增强算法[J]. 电子器件, 2018, 41(6): 1605-1611. WANG F J, JIN Y. Speech enhancement based on harmonic reconstruction filter used in digital hearing aids[J]. Chinese Journal of Electron Devices, 2018, 41(6): 1605-16117(in Chinese).
[13] 邵睿, 彭硕, 查文文, 等. 基于BiLSTM的生猪音频识别[J]. 合肥学院学报(综合版), 2022, 39(2): 113-119. SHAO R, PENG Sh, ZHA W W, et al. Pig audio recognition based on BiLSTM[J]. Journal of Hefei University(Comprehensive Edition), 2022, 39(2): 113-119(in Chinese).
[14] EPHRAIM Y, MALAH D. Speech enhancement using a minimum-mean square error short-time spectral amplitude estimator[J]. IEEE Transactions on Acoustics, Speech, and Signal Processing, 1984, 32(6): 1109-1121. http://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=1164453
[15] PLAPOUS C, MARRO C, SCALART P. Improved signal-to-noise ratio estimation for speech enhancement[J]. IEEE Transactions on Audio, Speech, and Language Processing, 2006, 14(6): 2098-2108.
[16] 欧世峰, 赵晓晖. 改进型先验信噪比估计语音增强算法[J]. 吉林大学学报(工学版), 2009, 39(3): 787-791. OU Sh F, ZHAO X H. Modified priori SNR estimation for noisy speech enhancement[J]. Journal of Jilin University (Engineering and Technology Edition), 2009, 39(3): 787-791(in Chinese).
[17] 魏静, 王雪婷, 刘法胜. 一种融合相位的先验信噪比算法[J]. 电声技术, 2022, 46(12): 112-115. WEI J, WANG X T, LIU F Sh. A priori signal-to-noise ratio algorithm based on phase[J]. Audio Engineering, 2022, 46(12): 112 -115(in Chinese).
[18] PLAPOUS C, MARRO C, SCALART P. Speech enhancement using harmonic regeneration[C]//Proceedings of IEEE International Conference on Acoustics. Philadelphia, USA: IEEE Press, 2005: 157-160.
[19] 王杰, 杨程程, 莫嘉永, 等. 谐波重构先验信噪比估计算法[J]. 计算机工程与应用, 2018, 54(7): 44-48. WANG J, YANG Ch Ch, MO J Y, et al. A priori SNR estimator based on harmonic regeneration[J]. Computer Engineering and Applications, 2018, 54(7): 44-48(in Chinese).
[20] 夏均忠, 刘远宏, 冷永刚, 等. 微弱信号检测方法的现状分析[J]. 噪声与振动控制, 2011, 31(3): 156-161. XIA J Zh, LIU Y H, LENG Y G, et al. Analysis of methods of weak signal detection[J]. Noise and Vibration Control, 2011, 31(3): 156-161(in Chinese).
[21] 张天骐, 张战, 权进国, 等. 语音信号基音检测的二次谱方法[J]. 计算机应用, 2005, 25(4): 934-936. ZHANG T Q, ZHANG Zh, QUAN J G, et al. Power spectrum reprocessing approach for pitch detection of speech[J]. Journal of Computer Applications, 2005, 25(4): 934-936(in Chinese).
[22] VALIN J M, ROUAT J, MICHAUD F. Microphone array post-filter for separation of simultaneous non-stationary sources[C]//2004 IEEE International Conference on Acoustics, Speech, and Signal Processing. Montreal, Canada: IEEE Press, 2004: 224.
计量
- 文章访问数: 2
- HTML全文浏览量: 2
- PDF下载量: 2