
Research on indoor visual aid algorithms for visually impaired people
-
摘要:
为了解决现有室内视觉辅助算法检测性能低、模型参数量大、不易部署于边缘设备等问题,对你只看一次(YOLO)网络YOLOv7-tiny进行改进,提出一种新的YOLOv7-ghost网络模型。针对模型参数量大的问题,引入幽灵瓶颈(GB)代替部分池化操作和高效层聚合网络(ELAN),大幅度降低模型参数量;构建了一个全新的高性能轻量化模块(即C2f-全局注意力模块),综合考虑全局和局部特征信息,更好地捕捉节点的上下文信息; 然后引入快速空间金字塔池化和幽灵瓶颈(SPPF-GB)模块,对特征进行重组和压缩,以融合不同尺度的特征信息、增强特征的表达能力;最后在头部引入可变形卷积(DCN),增强感受野的表达能力,以捕获目标周围更细粒度的目标结构和背景信息。结果表明,改进后的模型参数量下降了20.33%,模型大小下降了18.70%,平均精度mAP@0.50和mAP@0.50~0.95分别提升了1.2%和3.3%。该网络模型在保证轻量化的同时,检测精度得到了大幅度的提升,更利于室内场景目标检测算法实际应用的部署。
-
关键词:
- 图像处理 /
- 轻量化 /
- 幽灵瓶颈模块 /
- C2f-全局注意力模块 /
- 多尺度特征融合 /
- 可变形卷积 /
- YOLOv7-tiny网络模型
Abstract:In order to solve the problems of low detection performance, large number of model parameters and difficult deployment in edge devices of the existing indoor vision aided algorithm, the YOLOv7-tiny network was improved and a new YOLOv7-ghost network model was proposed. Firstly, aiming at the problem of large number of model parameters, ghost bottleneck (GB) was introduced to replace partial pooling operation and efficient layer aggregation network (ELAN) to significantly reduce the number of model parameters. Secondly, by constructing a new high-performance lightweight module(C2f-global attention module), the global and local feature information were comprehensively considered to better capture the context information of nodes. Then, spatial pyramid pooling-fast and ghost bottleneck (SPPF-GB) module were introduced to recombine and compress the features to fuse the feature information of different scales and enhance the expression ability of features. Finally, deformable convolution network(DCN) was introduced in the head part to enhance the expression ability of receptive field, so as to capture more fine-grained target structure and background information around the target. The results show that, the parameters of the improved model decrease by 20.33%, the model size decreases by 18.70%, and mean average accuracy mAP@0.50 and mAP@0.50~0.95 increases by 1.2% and 3.3%, respectively. The network model not only ensures lightweight, but also greatly improves the detection accuracy, which is more conducive to the deployment of indoor scene target detection algorithm.
-
0. 引言
世界卫生组织最近公布的关于视力障碍者的统计数据显示,全球约有2.53亿人患有视力障碍:其中有3600万人失明,2.17亿人患有中度至重度视力障碍[1]。视觉是人类最重要的感觉之一,人类从外界获取的信息约有83%来自视觉,视力障碍对个人的生活质量具有重要的影响,视力的丧失必然导致获取信息和执行日常任务的能力受损。对于视障人士来说,在室内外环境中可能面临诸多障碍。由于室内环境中目标种类多样,障碍物形状大小、尺寸多变,背景复杂,并且室内空间也随光照动态变化,这使得视障人士更加难以探寻室内物体[2]。复杂的室内环境使得室内目标检测任务相较于传统的通用目标检测任务具有更高的难度和挑战性。因此,为了使视障人群能够在室内环境下便利活动,促进其独立性和社会参与度,进一步改善室内目标检测算法的实时性和准确性将具有非常重要的现实意义。
传统的目标检测方法大多通过人工构建目标特征因子来对室内目标进行检测[3-4],这种方式存在目标语义信息缺失问题,并且受计算资源的限制,导致模型的检测性能以及泛化性能较差。近年来,随着大数据分析、计算机技术和深度学习的快速发展[5], 神经网络模型从基于区域卷积神经网络(region based convolutional neural networks, R-CNN)[6]开始, 到现在的你只看一次(you only look once, YOLO)网络[7],应用到室内场景的目标检测模型层出不穷,性能也越来越好[8],但是它们仍然具有较高的参数量和运算量,存在特征表达能力局限,受限于计算资源从而检测精度、检测速度及鲁棒性方面表现较差等问题。参考文献[5]和参考文献[9]中对室内目标检测算法进行了研究,试图在模型参数量和模型检测性能之间找到平衡,但模型精度会因为参数量的减少而下降,并且轻量化后的模型依然占据很大的存储空间,不利于嵌入式平台端的部署。
目前,YOLO系列算法因其出色的性能和能有效地平衡精度和速度而受到研究者们广泛的关注,但依然存在参数量过大、计算成本过高等问题[10],不便于部署到嵌入式平台,难以投入实际应用。因此,研究者们开始对其进行轻量化改进以适用于边缘端设备。BO等人[11]直接使用重复堆叠网络(ShuffleNetv2)[12]替换原有骨干网络, 实现了参数量的下降,同时利用注意力模块捕捉特征,虽然参数量和计算量都大幅度改善,但损失了1.1%的精度。LI等人[13]提出一种基于YOLOv3[14]的简化版网络DS-YOLO,以解决YOLOv3在嵌入式平台上检测速度低的问题,虽然该模型推理速度快,但在一些小目标等细节上的检测效果不如原模型。PEI等人[15]在YOLOv4算法主干网络中引入高效通道注意力机制和内卷算子,增强了网络的预测性能,并且减小了模型大小,不过模型大小仍达488 Mbit,该算法满足检测的实时性,但很难部署到嵌入式平台。WU等人[8]提出了一种新的YOLOv5-ghost神经网络结构,调整了原YOLOv5s[16]的网络层结构,降低了计算复杂度,使得该网络更适合嵌入式设备,但该模型的检测精度下降了2.6%。
尽管上述模型在轻量化方面都取得了不错的成绩,但大多未能在检测精度和模型参数量、模型大小等方面取得较好的平衡。因此,本文作者选用时下检测速度更快、检测性能更高的YOLOv7-tiny[17]模型作为研究对象,设计了一个更易于部署到边缘设备的以改进算法YOLOv7-ghost模块为主进行模型重构的轻量化网络。它是一种轻量级网络,与原来的网络相比,模型更小、检测精度更高,能够同时满足室内物体检测识别任务中模型对检测精度和实时性的要求。
1. 改进的YOLOv7-ghost算法
YOLOv7-tiny是YOLOv7模型中网络层数最少、网络结构最简单且参数量最少、面向图形处理器(graphic processing unit, GPU)的边缘架构[17],它有着更快的检测精度和检测速度。尽管YOLOv7-tiny在不同的目标检测任务中取得了不错的成绩,但在面对实际问题、部署移动端或计算资源有限的边缘设备时,很难表现其突出的性能优势。本文作者对YOLOv7-tiny模型进行改进,以应对部署到计算能力和存储能力有限的嵌入式设备时模型轻量化和精度保证的问题。
改进的主要工作见下。
(a) 在整个网络引入幽灵瓶颈结构(ghost bottleneck,GB)[18],代替原始的高效层聚合网络(efficient layer aggregation networks, ELAN),以大幅度降低模型的参数量和大小。
(b) 在网络中引入新模块C2f全局注意力模块(global attention module, GAM)[19],联合YOLOv8n中C2f-GAM高性能、轻量化的优势和GAM[20]捕捉关键信息的特长,增强模型的特征提取能力,提升模型的检测性能。
(c) 在网络中引入多尺度特征融合新模块快速空间金字塔池化模块(spatial pyramid pooling-fast, SPPF)[16],该模块结合SPPF-GB和GB结构进行改进,将浅层位置信息与深层语义信息进行高效融合,增强网络的特征表达能力。
(d) 在网络的头部部分引入可变形卷积网络(deformable convolution network, DCN)[21],使网络自适应关注目标信息,获得一个更准确的检测框,提升模型的检测精度。
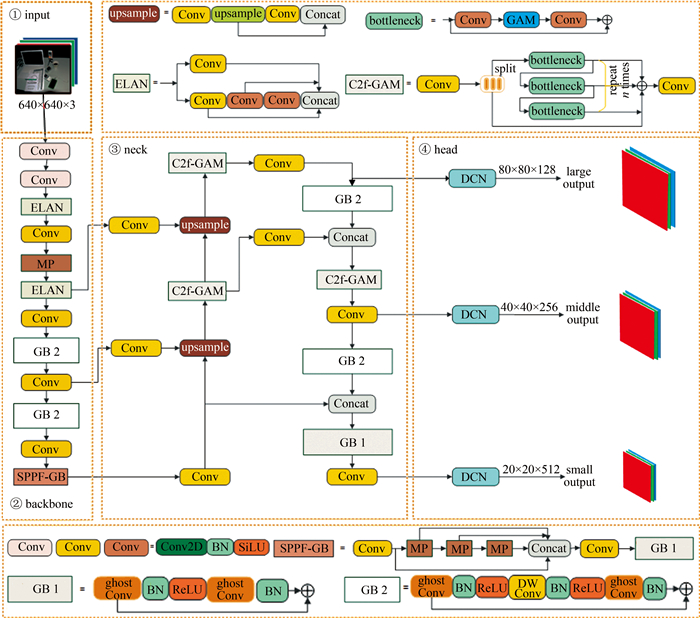
改进后的YOLOv7-ghost网络模型如图 1所示。图中, upsample表示上采样; Conv表示卷积(convolution); Concat表示连接(concatenate); MP表示最大池化(maximum pooling); SiLU表示sigmoid函数与linear unit函数的结合;DW Conv表示深度卷积(depthwise convolution); BN表示批量归一化(batch normalization); ReLU表示线性整流函数(rectified linear unit)。
1.1 GB模块
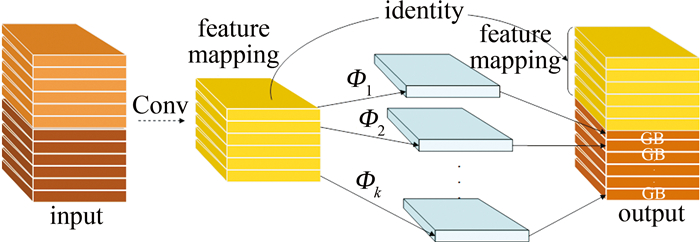
Ghost模块作为时下比较流行的轻量化即插即用模块,与网络中轻量化模块ShuffleNet[22]、MobileNet[23]等有着同等的竞争优势。Ghost模块主要分为卷积部分、线性变换运算和特征拼接3个步骤。首先利用传统的卷积得到特征映射;然后通过线性变换运算Φ操作(类似于3×3卷积)对每个通道的固有特征图进行处理,生成Ghost特征图;将第1步得到的内在特征图和第2步得到的Ghost特征图连接起来,得到最终的输出结果。通过这种方式,Ghost模块能够在较小计算成本、较少参数量的前提下获得与普通卷积相似的特征信息。Ghost模块如图 2所示。
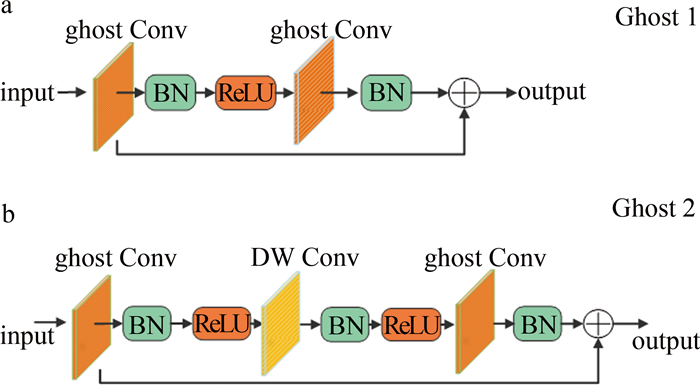
GB模块的链接与残差网络(residual network, ResNet)[24]中的基本残差块相似,它集成了多个卷积层和快捷方式,主要由两个堆叠的Ghost模块组成,根据步长分两种形式,如图 3a和图 3b所示。第1个Ghost模块用于增加特征维度以生成丰富的特征信息,而第2个Ghost模块则用于减少特征维度,使其与快捷路径一致,然后将快捷路径连接到这两个Ghost模块的输入和输出之间。在每一层后面使用BN和ReLU非线性激活。本文中根据模型架构在网络中不同位置引入两种形式大幅度降低了模型参数量。
1.2 SPPF-GB模块
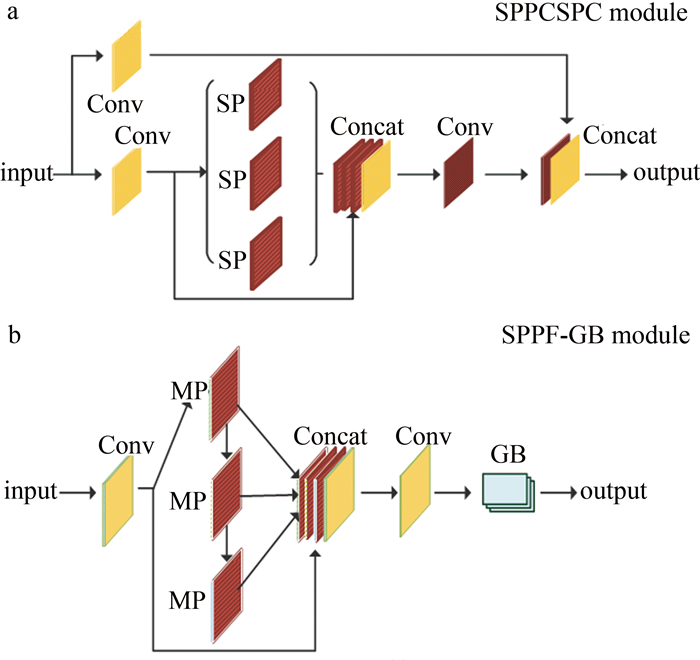
空间金字塔池化模块(spatial pyramid pooling, SPP)[25]由HE等人提出,它将输入的特征图与5×5、9×9、13×13池化核的3次最大池化操作处理的3个特征图并行连接,提取最终的特征图。然而这种操作需要花费很长的时间, 为了进一步提高模块的运行效率,获取多尺度特征的高层语义信息,研究者基于SPP提出了速度更快的快速空间金字塔池化模块(SPP-fast, SPPF)[16]模块,SPPF模块将卷积块处理的特征图与5×5池化核的最大池化操作处理的3个特征图进行拼接融合,提取最终的特征图。为获取语义抽象的特征,本文作者在SPPF后面增加一个GB,构建了高性能轻量化特征融合模块SPPF-GB(如图 4所示)。该模块通过级联的方式将池化后的特征做进一步的特征提取,以获取语义抽象的特征信息;并且由于串行级联池化核,可以获取不同感受野层次的特征信息,每个池化层都直接输出到下一层,这使得信息之间的传递更加直接和高效;使用残差连接的方式将池化后不同尺度的特征信息与池化前的特征信息拼接堆叠在一起,既可以整合多尺度局部特征信息,又可以使网络具有全局视角,帮助模型更好地理解特征的内在结构和规律; 最后将拼接后的特征依次送入一个卷积块和GB模块,以提取更深层的语义表达,增强了模型的特征提取能力。由于GB卷积高效轻量,因此,使用SPPF-GB模块代替原始网络的SPPCSPC模块(其中CSPC表示跨阶部分联系(cross stage partial connection)), 除了可释放近一个卷积块的参数量消耗外,还可以提升网络对冗余信息的理解能力,加强网络对关键信息的认识,学习到更细粒度的关键信息。
1.3 C2f-GAM模块
1.3.1 GAM模块
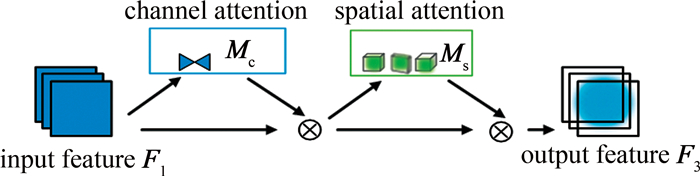
GAM是全局注意力机制,同时包含通道注意力子模块和空间注意力子模块,可以减少特征的丢失并在全局维度上放大特征。在通道注意子模块中首先使用3维排列来保留跨3维的信息。用一个双层多层感知器(multilayer perceptron, MLP)放大跨维通道空间依赖性。在空间注意子模块中,为了关注空间信息,使用了两个卷积层进行空间信息融合。其中C×H×W分别表示输入特征图的通道数、高和宽,r为缩减比。图 5为通道注意子模块,图 6为空间注意子模块。
整个GAM过程如图 7所示。
给定输入特征图 F1∈ RC×H×W,先将输入特征与经过通道注意力子模块得到的特征图逐元素相乘得到中间态 F2,再将 F2与经过空间注意力子模块得到的特征图逐元素相乘得到输出态 F3。具体公式如下[20]:
\boldsymbol{F}_2=\boldsymbol{M}_{\mathrm{c}}\left(\boldsymbol{F}_1\right) \otimes \boldsymbol{F}_1 (1) \boldsymbol{F}_3=\boldsymbol{M}_{\mathrm{s}}\left(\boldsymbol{F}_2\right) \otimes \boldsymbol{F}_2 (2) 式中: Mc和 Ms分别为通道注意图和空间注意图; \otimes 表示逐元素的乘法。
1.3.2 C2f-GAM模块
YOLOv8模型是梯度流丰富的C2f结构, 该结构拥有更强的特征提取能力,能较好地提取到目标信息。由于室内场景昏暗、光照不足,目标较为分散且背景干扰较强,导致模型刻画语义信息的能力变弱。为了提升网络对关键信息的关注度,增强模型对室内目标语义与边缘信息的特征提取能力,本文作者在C2f瓶颈结构中引入GAM模块,设计了C2f-GAM模块。如图 8所示,该模块主要由Conv、split、瓶颈结构(由两个Conv和一个GAM模块)组成。假设输入通道数为C,C通道特征图首先通过第1个Conv模块输出后经分为两份C/2通道的特征张量,其中一份张量作为主梯度流保存在列表中,另一份张量输入到瓶颈结构中,并且级联n个瓶颈结构,每个瓶颈结构模块的输出都作为下一个的输入,同时每个瓶颈结构模块的输出都存入到列表,实现提高训练速度的同时对特征张量进行并行计算,形成丰富的特征梯度流,最终把列表中的不同尺度特征图拼接后送入最后一个Conv模块中压缩融合后特征图的通道数。通过级联n个瓶颈结构获得多尺度梯度特征流,并将来自不同层级的特征图堆叠在一起,促进了特征融合后通道空间信息跨维交互的能力,保留了更多的空间信息和语义信息,提高了目标检测的性能。由于该模块结合了GAM与C2f,拥有更强地减少信息弥散和放大全局维度特征交互的能力,促进了模型对小型、低对比度目标的检测,能够提高模型的检测精度和泛化能力。
1.4 可变形卷积DCN
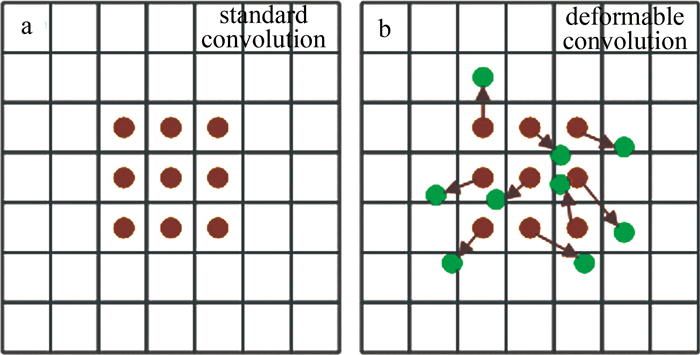
卷积神经网络CNN受其构建模块中的固定几何结构所限,难以对几何变换进行建模。对于室内场景中尺寸、长宽比相差较大的目标来说,使用标准的普通卷积对其进行特征提取缺乏良好的适应性,无法准确捕捉到贴近物体轮廓的信息[26],这是因为标准的卷积核形状是矩形的,对固定形状的目标特征提取效果较好,而对于形状不固定的目标,使用可变形卷积DCN代替标准卷积,将在采样时获得一个从前面的特征映射中学习到的偏移量从而扩大网络感受野,获得一个比标准卷积更贴近目标对象的轮廓信息,这大大提高了卷积神经网络CNN建模几何变换的能力。
如图 9所示,由于可变形卷积在标准卷积核中的每个采样点上增加了一个2维偏移量[27],将其放在网络主干部分会增加网络的计算消耗,本文中用其代替网络检测头的标准卷积,不仅不会增加过多的计算消耗,还会增强模型建模几何的能力。
![图 9 标准卷积和可变形卷积的采样示意图]() 图 9 标准卷积和可变形卷积的采样示意图Figure 9. Sampling diagram of standard and deformable convolution
图 9 标准卷积和可变形卷积的采样示意图Figure 9. Sampling diagram of standard and deformable convolution2. 实验与结果分析
2.1 数据集
根据视障人群日常生活需求,构建了室内场景数据集。自制数据集由两部分组成,一部分是将JIANG等人[9]对Indoor_CVPR09[28]、NYU2[29]、SUN[30]的数据集进行筛选,并进行一定补充的室内物体检测数据集;另一部分来自MS COCO[31]数据集和真实室内场景拍摄的图片。数据集共14个类别,包含12507张图片,分别是sofa、cabinet、table、chair、closestool、door、bed、washer、refrigerator、bottle、cup、shoes、tissue、cellphone,划分为:训练集(10005张)、验证集(1250张)和测试集(1252张)。
2.2 实验环境与评估指标
本文中的实验平台设置见表 1。模型训练200轮,批量数值为16,采用Adam优化器进行优化,初始学习率为0.001,采用余弦退火算法对学习率进行自动调整。实验中采用模型参数量、平均精度均值(mean average precision, mAP)mAP@0.50和MAP@0.50~0.95、帧率和模型大小作为模型性能的评价指标。其中,0.50表示交并比(intersection over union, IoU)为0.50,0.50~0.95表示交并比阈值范围从0.50~0.95。
表 1 实验平台Table 1. Experimental platformcomponent configuration central processing unit AMD 3900X memory 32 Gbyte GPU NVIDIA GTX3090 CUDA software platform 11.1 operation system Ubuntu 20.04 Python version Python 3.8 Pytorch version Pytorch 1.8.1 2.3 SPPF-GB模块实验
为验证多尺度特征融合模块SPPF-GB对网络的贡献,将其与SPP、SPPF、原模型中的SPPCSPC进行实验对比,以验证该模块在网络中的有效性。实验情况见表 2。
表 2 SPPF-GB模块实验Table 2. Experiment of SPPF-GB modulemodel parameter number/106 mAP@0.50/% mAP@0.50~0.95/% frame rate/s-1 SPP 5.85 68.7 44.5 294 SPPF 5.85 68.3 44.9 294 SPPCSPC 6.05 69.1 45.8 244 SPPF-GB 5.89 69.3 45.6 244 根据表 2可知,在网络中引入所设计的SPPF-GB模块后: 一方面不仅模型参数量比原模型(SPPCSPC模块所属模型)更少,检测精度还与原模型相当, 可以看出,尽管SPPF-GB模块所需的参数量比SPP、SPPF略多,但精度却有不小的提升;另一方面,虽然模型参数量相比原模型低,但模型帧率与原模型相当,这是因为在SPPF模块后面添加GB结构,加深了网络的深度,使得帧率并没有随着参数量的下降而增加,且模块通过GB结构进一步加强了网络对冗余特征的理解,使得特征重要的区域更加凸显,增强了特征的表达能力。
2.4 C2f-GAM模块设计实验
为了设计高性能的轻量化模块,以GB轻量化网络(YOLOv7-tiny+GB网络)作为基线进行实验,分别在C2f模块瓶颈结构中引入挤压激励机制(squeeze-and-excitation,SE)[32]、基于归一化注意力模块(normalization attention module,NAM)[33]、协调注意力机制(coordinate attention,CA)[34]、多头自我关注机制(multi-head self-attention,MHSA)[35]、卷积块注意力模块(convolutional block attention module,CBAM)[36]和GAM注意力机制进行实验,实验情况见表 3。
表 3 C2f-GAM模块设计实验Table 3. Design experiment of C2f-GAM modulemodel parameter number/10-6 mAP@0.50/% mAP@0.50~0.95/% frame rate/s-1 baseline 3.82 67.4 44.5 294 SE 4.62 68.4 45.1 256 NAM 4.62 68.7 45.8 270 CA 4.63 68.1 45.4 238 MHSA 4.73 68.0 44.0 270 CBAM 4.62 68.7 45.4 244 GAM 4.87 69.1 46.7 244 根据表 3可知,在C2f模瓶颈结构中添加GAM注意力模块,相比添加SE、NAM、CA、MHSA、CBAM 5个注意力模块,虽然模型参数量略高,但模型检测精度得到了极大提升,在与其它5个注意力对比模型中检测精度最高,检测精度MAP@0.50和MAP@0.50~0.95值达到69.1%和46.7%,比基线模型分别高出1.7%和2.2%。由于C2f模块通过级联n个瓶颈结构获得多尺度梯度特征流,增加了模型的深度和复杂度,使得模型帧率表现略差,但通过这种方式,能够有效地建立上下文之间的依赖关系从而提升网络特征表示能力,得到更精细、更准确的边缘轮廓信息,提高网络的表现,在实时性以及提升检测性能方面,达到了设计高性能模块的目的。
2.5 消融实验
为了验证本文中算法各改进模块功能的有效性,对所改进的各功能模块进行消融实验。结果如表 4所示。
表 4 消融实验Table 4. Ablation experimentplan GB C2f-GAM SPPF-GB DCN parameter number/106 mAP@0.50/% mAP@0.50~0.95/% frame rate/s-1 model size/Mbit 1 6.05 69.1 45.8 244 12.3 2 √ 3.82 67.4 44.5 294 7.9 3 √ √ 4.87 69.1 46.7 244 10.0 4 √ √ √ 4.71 69.4 47.1 294 9.7 5 √ √ √ √ 4.82 70.3 49.1 294 10.0 根据表 4可知,2号方案通过引入GB模块,改进后的模型由于参数量的大幅度下降,精度mAP@0.50和mAP@0.50~0.95有所下降,模型大小仅为7.9 Mbit,帧率增加到294/s;3号方案引入C2f-GAM模块后,在模型参数量增加约1×106的情况下,模型精度得到了大幅度提升,mAP@0.50和mAP@0.50~0.95分别提升了1.7%和2.2%,帧率有所下降;4号方案引入高性能轻量化模块SPPF-GB后,模型精度得到了进一步的提升,mAP@0.50和mAP@0.50~0.95分别提升了0.3%和0.4%,并且模型拥有更少的参数量,主要原因是SPPF-GB模块更注重增强方法的感受野,它能有效地增强网络的学习能力和鲁棒性;5号方案引入可变形卷积DCN后,由于新增了偏移量,增加了部分计算消耗,但此时模型参数量和模型检测性能最佳,相比原模型,此时模型参数量下降了20.33%,模型大小下降了18.70%,mAP@0.50和mAP@0.50~0.95分别达到了70.3%和49.1%,较原模型分别提升了1.2%和3.3%,说明模型引入可变形卷积DCN后,网络能自动调节目标感受野的大小,输出更准确的感受野范围,提高模型对目标轮廓的敏感度,捕捉到更准确的目标框位置,提高模型的检测精度。
综上所述,改进后的YOLOv7-ghost模型相比原始网络,参数量更少、模型大小更小,检测精度mAP@0.50和mAP@0.50~0.95更高,各方面性能指标有所改进,有效改善了室内目标特征信息缺失的问题,提高了网络对冗余信息、目标关键信息的理解能力,这充分体现了本文中改进算法的有效性和优越性。
2.6 与其它算法的对比
为验证本文中方法对室内目标检测的有效性,将改进算法与faster R-CNN[37]、SSD[10]、YOLOv3-tiny、YOLOv5s、YOLOv8n、YOLOv7-tiny进行实验对比,实验结果如表 5所示。
表 5 主流检测算法性能对比Table 5. Performance comparison of mainstream detection algorithmsmodel parameter number/106 mAP@0.50/% mAP@0.50~0.95/% frame rate/s-1 model size/Mbit faster R-CNN 137.10 66.1 45.2 151 108.0 SSD 62.75 60.6 41.4 64 94.6 YOLOv3-tiny 8.70 53.3 27.1 333 17.5 YOLOv5s 7.06 67.9 44.5 149 14.4 YOLO8n 3.01 67.9 47.0 244 6.2 YOLOv7-tiny 6.05 69.1 45.8 244 12.3 ours 4.82 70.3 49.1 294 10.0 根据表 5可知,改进模型YOLOv7-ghost(ours)在数据集上表现良好,参数量为4.82×106,mAP@0.50和mAP@0.50~0.95分别为70.3%和49.1%,帧率值为294/s,模型大小为10.0 Mbit,改进后的算法相比faster R-CNN、SSD、YOLOv3-tiny、YOLOv5s、YOLOv7-tiny,有着极小的参数量和模型大小,模型参数量只有faster R-CNN的3%左右,模型大小约只有其1/11,每秒钟处理的图片比其多143帧,精度mAP@0.50和mAP@0.50~0.95分别比其高4.2%和3.9%。YOLOv8n作为当前主流的性能更优、检测精度更高的目标检测算法,本文中改进的模型与其相比,尽管改进后的模型有着比YOLOv8n稍高的参数量和模型大小,但却有着更高的检测精度,模型精度mAP@0.50和mAP@0.50~0.95相比YOLOv8n分别提升了2.4%和2.1%。
综上所述,改进后的YOLOv7-Ghost算法相比于原始网络和其它主流的目标检测算法轻量化效果明显,相比YOLOv8n虽然模型参数量和模型大小略有增高,但具有更快的推理速度,并且模型精度mAP@0.50和mAP@0.50~0.95均优于原始网络和其它主流的目标检测算法,改进模型同时兼顾了模型精度和轻量化,充分展现了本文中改进算法的优越性。
2.7 改进算法检测效果验证
为进一步验证本文模型的检测性能,选取3组具有代表性的室内场景(依次是密集场景(见图 10a)、遮挡严重场景(见图 10b)以及强曝光场景(见图 10c))对YOLOv7-tiny、YOLOv8n以及改进模型进行可视化对比。从图 10可以看出,本文模型检测到的目标具有较高的检测精度,并且比YOLOv7-tiny、YOLOv8n模型检测到更多的瓶子,误检率更低。从图 10b可以看出,尽管目标(sofa)被人严重遮挡,但改进模型相比YOLOv7-tiny、YOLOv8n,检测精度更高,说明改进模型可以有效改善严重遮挡目标的检测效果。从图 10c可以看出,改进模型保持着更高的检测精度,说明本文中算法对室内场景具有很强的适应性。通过3组实验分析得出,本文算法拥有比原算法和YOLOv8n更好的检测性能,并且对室内场景具有很强的适应性,能更好满足室内场景目标检测实际应用中模型对参数量和精度的要求。
3. 结论
为了解决现有室内视觉辅助算法检测性能低、模型参数量大、不易部署于边缘设备等问题。在YOLOv7-tiny网络中引入GB模块对模型进行极大程度的压缩,并在此基础上设计了C2f-GAM和SPPF-GB模块,两模块能从网络感受野以及网络深度两方面增强模型对特征信息的高效学习。通过结合C2f-GAM、SPPF-GB模块和可变形卷积,模型不仅可以学习到更丰富的特征信息,而且不会占用过多的计算资源。实验结果表明,相比原始网络,改进模型参数量减少了20.33%,模型占用存储空间仅为10.0 Mbit,推理速度更快,并且模型检测精度最高,mAP@0.50和mAP@0.50~0.95分别达到70.3%和49.1%。与当前主流的目标检测算法faster R-CNN、SSD、YOLOv3-tiny、YOLO v5s以及原始的YOLOv7-tiny相比,改进算法有着极小的参数量和模型大小,虽然改进后的模型相比最新的YOLOv8n算法有着略高的参数量和模型大小,但改进后的模型实现了检测精度和轻量化的有效平衡,获得了最佳的检测性能,更利于部署到计算能力有限的室内嵌入式设备。在未来,将继续对模型进行轻量化改进,提升模型的检测性能,并实际部署到嵌入式设备或移动端,帮助视障人群更好地感知周围环境。
-
![]()
图 9 标准卷积和可变形卷积的采样示意图
Figure 9. Sampling diagram of standard and deformable convolution
表 1 实验平台
Table 1 Experimental platform
component configuration central processing unit AMD 3900X memory 32 Gbyte GPU NVIDIA GTX3090 CUDA software platform 11.1 operation system Ubuntu 20.04 Python version Python 3.8 Pytorch version Pytorch 1.8.1  下载: 导出CSV
下载: 导出CSV
表 2 SPPF-GB模块实验
Table 2 Experiment of SPPF-GB module
model parameter number/106 mAP@0.50/% mAP@0.50~0.95/% frame rate/s-1 SPP 5.85 68.7 44.5 294 SPPF 5.85 68.3 44.9 294 SPPCSPC 6.05 69.1 45.8 244 SPPF-GB 5.89 69.3 45.6 244
下载: 导出CSV
表 3 C2f-GAM模块设计实验
Table 3 Design experiment of C2f-GAM module
model parameter number/10-6 mAP@0.50/% mAP@0.50~0.95/% frame rate/s-1 baseline 3.82 67.4 44.5 294 SE 4.62 68.4 45.1 256 NAM 4.62 68.7 45.8 270 CA 4.63 68.1 45.4 238 MHSA 4.73 68.0 44.0 270 CBAM 4.62 68.7 45.4 244 GAM 4.87 69.1 46.7 244
下载: 导出CSV
表 4 消融实验
Table 4 Ablation experiment
plan GB C2f-GAM SPPF-GB DCN parameter number/106 mAP@0.50/% mAP@0.50~0.95/% frame rate/s-1 model size/Mbit 1 6.05 69.1 45.8 244 12.3 2 √ 3.82 67.4 44.5 294 7.9 3 √ √ 4.87 69.1 46.7 244 10.0 4 √ √ √ 4.71 69.4 47.1 294 9.7 5 √ √ √ √ 4.82 70.3 49.1 294 10.0
下载: 导出CSV
表 5 主流检测算法性能对比
Table 5 Performance comparison of mainstream detection algorithms
model parameter number/106 mAP@0.50/% mAP@0.50~0.95/% frame rate/s-1 model size/Mbit faster R-CNN 137.10 66.1 45.2 151 108.0 SSD 62.75 60.6 41.4 64 94.6 YOLOv3-tiny 8.70 53.3 27.1 333 17.5 YOLOv5s 7.06 67.9 44.5 149 14.4 YOLO8n 3.01 67.9 47.0 244 6.2 YOLOv7-tiny 6.05 69.1 45.8 244 12.3 ours 4.82 70.3 49.1 294 10.0
下载: 导出CSV
-
[1] ERDAW H B, TAYE Y G, LEMMA D T. A real-time obstacle detection and classification system for assisting blind and visually impaired people based on Yolo model[C]//2023 International Conference on Information and Communication Technology for Development for Africa (ICT4DA). New York, USA: IEEE Press, 2023: 79-84.
[2] DUMAN S, ELEWI A, YETGIN Z. Design and implementation of an embedded real-time system for guiding visually impaired individuals[C]//2019 International Artificial Intelligence and Data Processing Symposium (IDAP). New York, USA: IEEE Press, 2019: 1-5.
[3] ESPINACE P, KOLLAR T, SOTO A, et al. Indoor scene recognition through object detection[C]//2010 IEEE International Conference on Robotics and Automation. New York, USA: IEEE Press, 2010: 1406-1413.
[4] KIM J, LEE C H, YOUNGC, et al. Optical sensor based object detection for autonomous robots[C]//20118th International Conference on Ubiquitous Robots and Ambient Intelligence(URAI). New York, USA: IEEE Press, 2011: 746-754.
[5] 李维刚, 杨潮, 蒋林, 等. 基于改进YOLOv4算法的室内场景目标检测[J]. 激光与光电子学进展, 2022, 59(18): 1815003. LI W G, YANG Ch, JING L, et al. Indoor scene object detection based on improved YOLOv4 algorithm[J]. Laser & Optoelectronics Progress, 2022, 59(18): 1815003(in Chinese).
[6] GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE Press, 2014: 580-587.
[7] REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection[C]//Procee Dings of the IEEE Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE Press, 2016: 779-788.
[8] WU T H, WANG T W, LIU Y Q. Real-time vehicle and distance detection based on improved yolov5 network[C]//2021 3rd World Symposium on Artificial Intelligence (WSAI). New York, USA: IEEE Press, 2021: 24-28.
[9] JIANG L, NIE W, ZHU J, et al. Lightweight object detection network model suitable for indoor mobile robots[J]. Journal of Mechanical Science and Technology, 2022, 36(2): 907-920. DOI: 10.1007/s12206-022-0138-2
[10] LIU W, ANGUELOV D, ERHAN D, et al. SSD: Single shot multibox detector[C]//Computer Vision-ECCV 2016: 14th European Conference. New York, USA: Springer Press, 2016: 21-37.
[11] 薄景文, 张春堂. 基于YOLOv3的轻量化口罩佩戴检测算法[J]. 电子测量技术, 2021, 44(23): 105-110. BO J W, ZHANG Ch T. Lightweight mask wear detection algorithm based on YOLOv3[J]. Electronic Measurement Technology, 2021, 44(23): 105-110(in Chinese).
[12] MA N, ZHANG X, ZHENG H T, et al. Shufflenetv2: Practical guidelines for efficient CNN architecture design[C]//Proceedings of the European conference on computer vision (ECCV). New York, USA: IEEE Press, 2018: 116-131.
[13] 李成跃, 姚剑敏, 林志贤, 等. 基于改进YOLO轻量化网络的目标检测方法[J]. 激光与光电子学进展, 2020, 57(14): 141003. LI Ch Y, YAO J M, LIN Zh X, et al. Object detection method Based on improved YOLO lightweight network[J]. Laser & Optoelectronics Progress, 2019, 57(14): 141003(in Chinese).
[14] REDMON J, FARHADI A. Yolov3: An incremental improvement[C]//IEEE Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE Press, 2018: 45-48.
[15] 裴瑞景, 王硕, 王华英. 基于改进YOLOv4算法的水果识别检测研究[J]. 激光技术, 2023, 47(3): 400-406. DOI: 10.7510/jgjs.issn.1001-3806.2023.03.018 PEI R J, WANG Sh, WANG H Y. Research on fruit recognition detection algorithm based on improved YOLOv4[J]. Laser Technology, 2023, 47(3): 400-406(in Chinese). DOI: 10.7510/jgjs.issn.1001-3806.2023.03.018
[16] TANG H, LIANG S, YAO D, et al. A visual defect detection for optics lens based on the YOLOv5-C3CA-SPPF network model[J]. Optics Express, 2023, 31(2): 2628-2643. DOI: 10.1364/OE.480816
[17] WANG C Y, BOCHKOVSKIY A, LIAO H Y M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE Press, 2023: 7464-7475.
[18] HAN K, WANG Y, TIAN Q, et al. Ghostnet: More features from cheap operations[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE Press, 2020: 1580-1589.
[19] LOU H T, DUAN X H, GUO J M, et al. DC-YOLOv8: Small-size object detection algorithm based on camera sensor[J]. Electronics, 2023, 12(10): 2323. DOI: 10.3390/electronics12102323
[20] LIU Y, SHAO Z, HOFFMANN N. Global attention mechanism: Retain information to enhance channel-spatial interactions[EB/OL]. (2021-12-10)[2024-01-16]. https://arxiv.org/abs/2112.05561.
[21] DAI J, QI H, XIONG Y, et al. Deformable convolutional networks[C]//Proceedings of the IEEE International Conference on Computer Vision. New York, USA: IEEE Press, 2017: 764-773.
[22] ZHANG X Y, ZHOU X Y, LIN M X. ShuffleNet: an extremely effificient convolutional neural network for mobile devices[C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE Press, 2018: 00716.
[23] HOWARD A G, ZHU M, CHEN B, et al. Mobilenets: Efficient convolutional neural networks for mobile vision applications[EB/OL]. (2017-04-17)[2024-01-26]. https://arxiv.org/abs/1704.04861.
[24] HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE Press, 2016: 770-778.
[25] HE K, ZHANG X, REN S, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(9): 1904-1916. DOI: 10.1109/TPAMI.2015.2389824
[26] 杨文瀚, 廖苗. 融合注意力机制与残差可形变卷积的肝肿瘤分割方法[J]. 激光与光电子学进展, 2023, 60(12): 1210001. YANG W H, LIAO M. Fusion of dual attention and deform-able residual convolution for segmentation of liver tumor[J]. Laser & Optoelectronics Progress, 2023, 60(12): 1210001(in Chinese).
[27] 李子茂, 李嘉晖, 尹帆, 等. 基于可形变卷积与SimAM注意力的密集柑橘检测算法[J]. 中国农机化学报, 2023, 44(2): 156-162. LI Z M, LI J H, YIN F, et al. Dense citrus detection algorithm based on deformable convolution and SimAM attention[J]. Journal of Chinese Agricultural Mechanization, 2023, 44 (2): 156-162(in Chinese).
[28] SILBERMAN N, HOIEM D, KOHLI P, et al. Indoor segmentation and support inference from rgbd images[C]//Computer Vision-ECCV 2012: 12th European Conference on Computer Vision. New York, USA: Springer Press, 2012: 746-760.
[29] QUATTONI A, TORRALBA A. Recognizing indoor scenes[C]//2009 IEEE Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE Press, 2009: 413-420.
[30] XIAO J, HAYS J, EHINGER K A, et al. Sun database: Large-scale scene recognition from abbey to zoo[C]//2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE Press, 2010: 3485-3492.
[31] LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: Common objects in context[C]//Computer Vision-ECCV 2014: 13th European Conference. New York, USA: Springer Press, 2014: 740-755.
[32] HU J, SHEN L, SUN G. Squeeze-and-excitation networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE Press, 2018: 7132-7141.
[33] LIU Y, SHAO Z, TENG Y, et al. NAM: Normalization-based attention module[EB/OL]. (2021-11-24)[2024-01-26]. https://arxiv.org/abs/2111.12419.
[34] HOU Q, ZHOU D, FENG J. Coordinate attention for efficient mobile network design[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE Press, 2021: 13713-13722.
[35] SRINIVAS A, LIN T Y, PARMAR N, et al. Bottleneck transformers for visual recognition[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE Press, 2021: 16519-16529.
[36] WOO S Y, PARK J C, LEE J Y, et al. CBAM: Convolutional block attention module[C]//Proceedings of the European Conference on Computer Vision(ECCV). New York, USA: Springer Press, 2018: 3-19.
[37] REN S Q, HE K M, GIRSHICK R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149.




计量
- 文章访问数: 3
- HTML全文浏览量: 0
- PDF下载量: 1