
Research on indoor visual aid algorithms for visually impaired people
-
摘要:
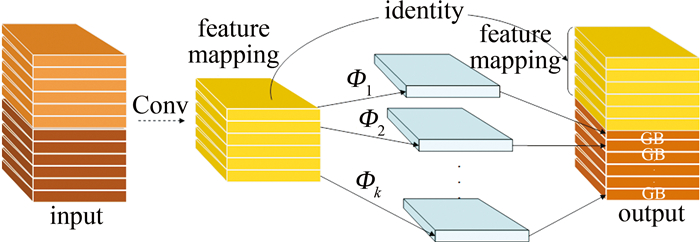
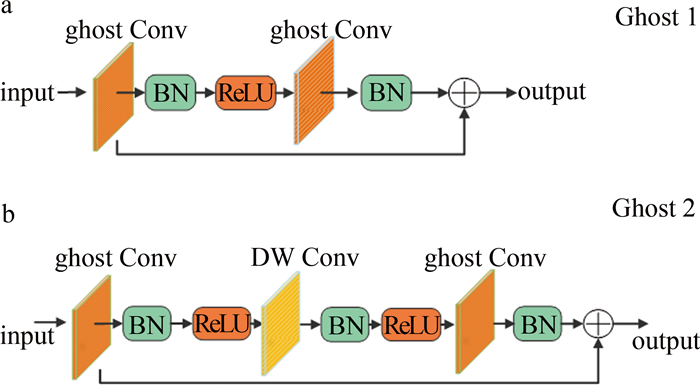
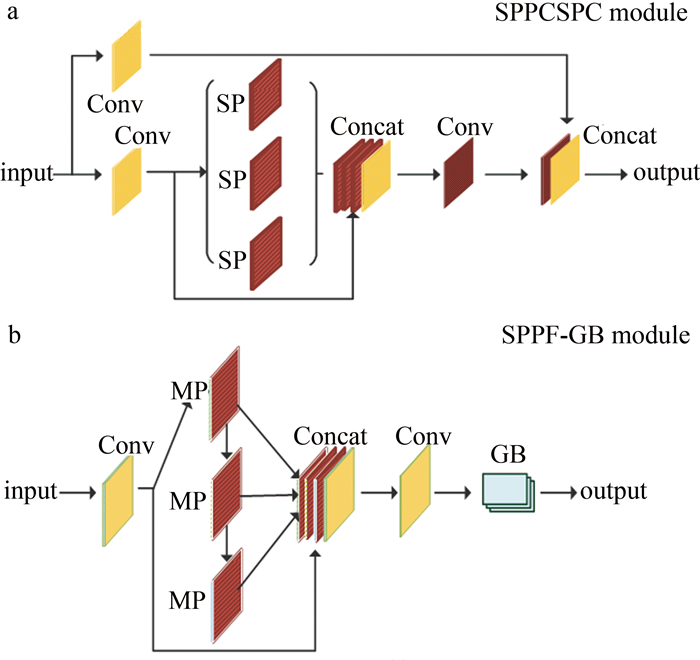
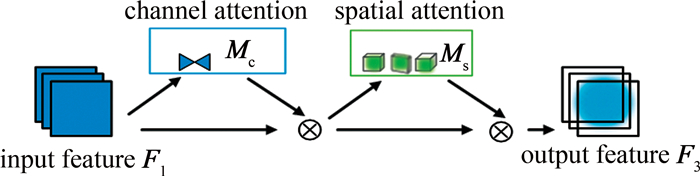
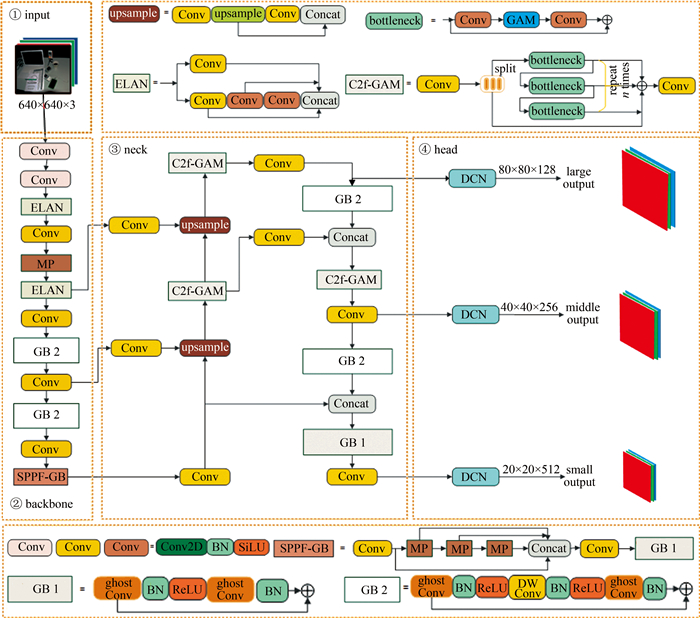
为了解决现有室内视觉辅助算法检测性能低、模型参数量大、不易部署于边缘设备等问题,对你只看一次(YOLO)网络YOLOv7-tiny进行改进,提出一种新的YOLOv7-ghost网络模型。针对模型参数量大的问题,引入幽灵瓶颈(GB)代替部分池化操作和高效层聚合网络(ELAN),大幅度降低模型参数量;构建了一个全新的高性能轻量化模块(即C2f-全局注意力模块),综合考虑全局和局部特征信息,更好地捕捉节点的上下文信息; 然后引入快速空间金字塔池化和幽灵瓶颈(SPPF-GB)模块,对特征进行重组和压缩,以融合不同尺度的特征信息、增强特征的表达能力;最后在头部引入可变形卷积(DCN),增强感受野的表达能力,以捕获目标周围更细粒度的目标结构和背景信息。结果表明,改进后的模型参数量下降了20.33%,模型大小下降了18.70%,平均精度mAP@0.50和mAP@0.50~0.95分别提升了1.2%和3.3%。该网络模型在保证轻量化的同时,检测精度得到了大幅度的提升,更利于室内场景目标检测算法实际应用的部署。
-
关键词:
- 图像处理 /
- 轻量化 /
- 幽灵瓶颈模块 /
- C2f-全局注意力模块 /
- 多尺度特征融合 /
- 可变形卷积 /
- YOLOv7-tiny网络模型
Abstract:In order to solve the problems of low detection performance, large number of model parameters and difficult deployment in edge devices of the existing indoor vision aided algorithm, the YOLOv7-tiny network was improved and a new YOLOv7-ghost network model was proposed. Firstly, aiming at the problem of large number of model parameters, ghost bottleneck (GB) was introduced to replace partial pooling operation and efficient layer aggregation network (ELAN) to significantly reduce the number of model parameters. Secondly, by constructing a new high-performance lightweight module(C2f-global attention module), the global and local feature information were comprehensively considered to better capture the context information of nodes. Then, spatial pyramid pooling-fast and ghost bottleneck (SPPF-GB) module were introduced to recombine and compress the features to fuse the feature information of different scales and enhance the expression ability of features. Finally, deformable convolution network(DCN) was introduced in the head part to enhance the expression ability of receptive field, so as to capture more fine-grained target structure and background information around the target. The results show that, the parameters of the improved model decrease by 20.33%, the model size decreases by 18.70%, and mean average accuracy mAP@0.50 and mAP@0.50~0.95 increases by 1.2% and 3.3%, respectively. The network model not only ensures lightweight, but also greatly improves the detection accuracy, which is more conducive to the deployment of indoor scene target detection algorithm.
-
0. 引言
激光测距、激光目标指示等应用都要求激光器兼具高单脉冲能量、高峰值功率、高光束质量。比如,脉冲激光测距机利用射向目标的激光脉冲,测量目标距离,根据脉冲测距机测距方程可知[1],在其它参量不变的情况下,要提高测距只能提高激光峰值功率、减小激光的发散角;再比如,激光半主动制导要求激光目标指示器要保证小的发散角和高的光束质量[2]等等。
传统的测距、目标指示等场景用1 μm激光器多采用氙灯抽运的方式,而氙灯的低光电转换效率会导致激光器运行时产生很多废热,使其不得不用体积大、功耗大的水冷方式冷却。因激光二极管(laser diode, LD)比氙灯的光电转换效率高一个数量级,采用LD抽运[3-4]产生的废热比采用氙灯抽运时少得多,无需水冷,只需用体积小、功耗小的风冷方式散热,这给测距、目标指示等场景用激光器提供了更好的选择[3]。
本文作者从稳定腔的模式理论出发,先使用软件模拟了望远镜腔中的基模高斯光束大小;然后从激光特性控制理论出发,利用望远镜腔的腔型设计和对磷酸二氘钾(potassium dideuterium phosphate, DKDP)晶体电光调Q分别对激光输出横模和脉宽进行了控制; 并选用风冷型LD侧面抽运模块作为激光器的抽运源,通过侧面抽运,最终获得重复频率10 Hz,单脉冲能量100 mJ、光束质量因子M2=1.31、脉宽10 ns、发散角0.6 mrad的1064 nm激光输出。
1. 激光器谐振腔腔型分析与设计
1.1 谐振腔腔型分析
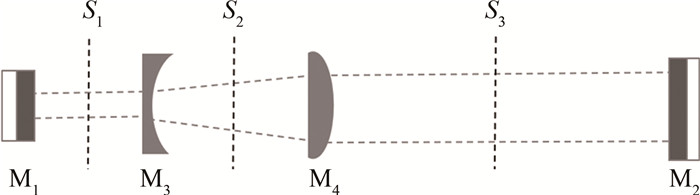
图 1为设计的望远镜腔示意图。定义如下: M1和M2为腔镜,曲率依次为R1和R2;f1和f2分别为腔内插入的伽利略望远镜的凹镜M3、凸镜M4的焦距;L1、L2和L3为M1到M3、M3到M4、M4到M2的距离;S1、S2和S3为设在M1和M3之间、M3和M4之间、M4和M2之间的参考面,设S1、S2、S3到M1的距离分别为x1,x2,x3。
利用稳定腔的模式理论,设从S1、S2和S3参考面出发傍轴光线在腔内的往返矩阵[5]分别为TS1、TS2、TS3,则有:
\begin{aligned} & \boldsymbol{T}_{S_1}=\left[\begin{array}{cc} A_{S_1} & B_{S_1} \\ C_{S_1} & D_{S_1} \end{array}\right]=\left[\begin{array}{cc} 1 & x_1 \\ 0 & 1 \end{array}\right] \times\left[\begin{array}{cc} 1 & 0 \\ -2 / R_1 & 1 \end{array}\right] \times\left[\begin{array}{cc} 1 & L_1 \\ 0 & 1 \end{array}\right] \times\left[\begin{array}{cc} 1 & 0 \\ -1 / f_1 & 1 \end{array}\right] \times\left[\begin{array}{cc} 1 & L_2 \\ 0 & 1 \end{array}\right] \times\left[\begin{array}{cc} 1 & 0 \\ -1 / f_2 & 1 \end{array}\right] \times \\ & {\left[\begin{array}{cc} 1 & L_3 \\ 0 & 1 \end{array}\right] \times\left[\begin{array}{cc} 1 & 0 \\ -2 / R_2 & 1 \end{array}\right] \times\left[\begin{array}{cc} 1 & L_3 \\ 0 & 1 \end{array}\right] \times\left[\begin{array}{cc} 1 & 0 \\ -1 / f_2 & 1 \end{array}\right] \times\left[\begin{array}{cc} 1 & L_2 \\ 0 & 1 \end{array}\right] \times\left[\begin{array}{cc} 1 & 0 \\ -1 / f_1 & 1 \end{array}\right] \times\left[\begin{array}{cc} 1 & L_1-x_1 \\ 0 & 1 \end{array}\right]} \end{aligned} (1) \begin{aligned} \boldsymbol{T}_{S_2}= & {\left[\begin{array}{cc} A_{S_2} & B_{S_2} \\ C_{S_2} & D_{S_2} \end{array}\right]=\left[\begin{array}{cc} 1 & x_2-L_1 \\ 0 & 1 \end{array}\right] \times\left[\begin{array}{cc} 1 & 0 \\ -1 / f_1 & 1 \end{array}\right] \times\left[\begin{array}{cc} 1 & L_1 \\ 0 & 1 \end{array}\right] \times\left[\begin{array}{cc} 1 & 0 \\ -2 / R_1 & 1 \end{array}\right] \times\left[\begin{array}{cc} 1 & L_1 \\ 0 & 1 \end{array}\right] \times\left[\begin{array}{cc} 1 & 0 \\ -1 / f_1 & 1 \end{array}\right] \times } \\ & {\left[\begin{array}{cc} 1 & L_2 \\ 0 & 1 \end{array}\right] \times\left[\begin{array}{cc} 1 & 0 \\ -1 / f_2 & 1 \end{array}\right] \times\left[\begin{array}{cc} 1 & L_3 \\ 0 & 1 \end{array}\right] \times\left[\begin{array}{cc} 1 & 0 \\ -2 / R_2 & 1 \end{array}\right] \times\left[\begin{array}{cc} 1 & L_3 \\ 0 & 1 \end{array}\right] \times\left[\begin{array}{cc} 1 & 0 \\ -1 / f_2 & 1 \end{array}\right] \times\left[\begin{array}{cc} 1 & L_2-x_2 \\ 0 & 1 \end{array}\right] } \end{aligned} (2) \begin{aligned} \boldsymbol{T}_{S_3}= & {\left[\begin{array}{cc} A_{S_3} & B_{S_3} \\ C_{S_3} & D_{S_3} \end{array}\right]=\left[\begin{array}{cc} 1 & x_3-L_2 \\ 0 & 1 \end{array}\right] \times\left[\begin{array}{cc} 1 & 0 \\ -1 / f_2 & 1 \end{array}\right] \times\left[\begin{array}{cc} 1 & L_2 \\ 0 & 1 \end{array}\right] \times\left[\begin{array}{cc} 1 & 0 \\ -1 / f_1 & 1 \end{array}\right] \times\left[\begin{array}{cc} 1 & L_1 \\ 0 & 1 \end{array}\right] \times\left[\begin{array}{cc} 1 & 0 \\ -2 / R_1 & 1 \end{array}\right] \times } \\ & {\left[\begin{array}{cc} 1 & L_1 \\ 0 & 1 \end{array}\right] \times\left[\begin{array}{cc} 1 & 0 \\ -1 / f_1 & 1 \end{array}\right] \times\left[\begin{array}{cc} 1 & L_2 \\ 0 & 1 \end{array}\right] \times\left[\begin{array}{cc} 1 & 0 \\ -1 / f_2 & 1 \end{array}\right] \times\left[\begin{array}{cc} 1 & L_3 \\ 0 & 1 \end{array}\right] \times\left[\begin{array}{cc} 1 & 0 \\ -2 / R_2 & 1 \end{array}\right] \times\left[\begin{array}{cc} 1 & L_3-x_3 \\ 0 & 1 \end{array}\right] } \end{aligned} (3) 根据稳定腔的模式理论,设腔内基模高斯光束在腔内S1、S2、S3参考面处的光斑尺寸分别为wS1,S2,S3[6],波长为λ, 则稳定腔中有:
w_{S_1, s_2, s_3}=\frac{(\mathit{λ} / \pi)^{1 / 2} \times\left|B_{S_1, s_2, s_3}\right|^{1 / 2}}{\left[1-\left(\frac{A_{S_1, s_2, s_3}+D_{s_1, s_2, s_3}}{2}\right)^2\right]^{1 / 4}} (4) 1.2 望远镜腔设计
分别设计了2倍、3倍、4倍望远镜腔。其中2倍望远镜腔腔参数R1=5 m,L1=0.02 m,f1=0.015 m,L2=0.015 m,f2=0.03 m,L3=0.1 m,R2=∞;3倍望远镜腔腔参数R1=5 m,L1=0.02 m,f1=0.015 m,L2=0.03 m,f2=0.045 m,L3=0.1 m,R2=∞; 4倍望远镜腔腔参数R1=5 m,L1=0.02 m,f1=0.015 m,L2=0.045 m,f2=0.06 m,L3=0.1 m,R2=∞。
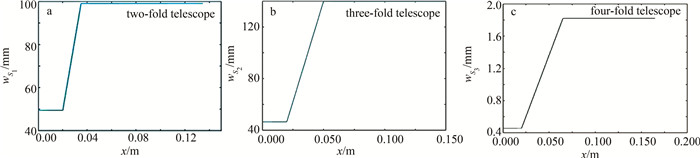
使用软件仿真模拟了wS1,S2,S3的大小[6], 单位为m。望远镜腔基模光斑半径随腔内位置的变化如图 2所示。图中, x定义为腔内基模光斑位置到M1位置的距离,单位为m。由理论模拟结果可知,腔内不插入望远镜,腔的基模束腰半径仅为0.5 mm左右。插入望远镜后,基模束腰半径随插入望远镜倍数被等倍放大到1.0 mm,1.4 mm,2.0 mm。
![图 2 望远镜腔基模光斑半径随腔内位置的变化]() 图 2 望远镜腔基模光斑半径随腔内位置的变化Figure 2. Radius of the spot in the fundamental mode of telescope cavity vs. position in the cavity
图 2 望远镜腔基模光斑半径随腔内位置的变化Figure 2. Radius of the spot in the fundamental mode of telescope cavity vs. position in the cavity2. 激光器的热分析和散热设计
2.1 LD模块产生的热量计算
激光的波长、单脉冲能量、频率分别为1064 nm、100 mJ和10 Hz时,产生的热量源于激光器所使用的LD侧面抽运模块在工作时产生热量,模块产生热量大小由其抽运功率决定, 模块的抽运功率大小由激光器的输出功率决定。先计算LD产生的总热量[7],激光器的波长、单脉冲能量、频率分别为1064 nm、100 mJ和10 Hz时, 1064 nm输出功率计算为1 W; 一般, LD侧面抽运模块光光转换效率为30%,光电转换效率为50%,则LD侧面模块的总抽运功率计算为3.3 W,故LD侧面抽运模块在工作时产生的总的最大热量计算为6.7 W。
LD侧面抽运激光器的散热方式分为水冷散热和风冷散热两种, 散热方式的选择主要取决于选择哪种LD侧面抽运模块。LD侧面抽运模块同样分为两种:一种为掺钕钇铝石榴石(Nd ∶YAG)水冷模块; 另一种为Nd ∶YAG风冷模块。水冷模块通常用于百赫兹到千赫兹、百毫焦到焦耳级别的1064 nm激光输出,而风冷模块通常用来输出几十赫兹、百毫焦以下。由于激光器无需水冷的缘故,LD侧面抽运模块选用传导冷却型侧面抽运模块[8]更合适,其相对的功耗更低、体积更小、更便于携带。模块为4组弧形分布的晶体棒分段模块,一侧为2组弧形分布的晶体棒抽运LD1和LD2,另一侧为铟焊的2根Nd ∶YAG激光晶体[9],其中晶体尺寸为3 mm × 24 mm,主发射波长为1064 nm,要求恒温工作,温度为25 ℃。激光器工作的最高环境温度设为40 ℃,即LD模块必须在环境温度达到40 ℃时仍能保持恒温工作。
2.2 散热系统结构和TEC产生的热量计算
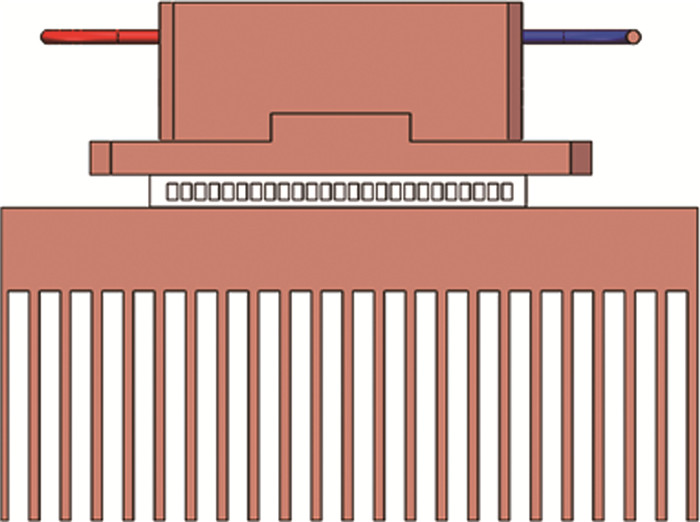
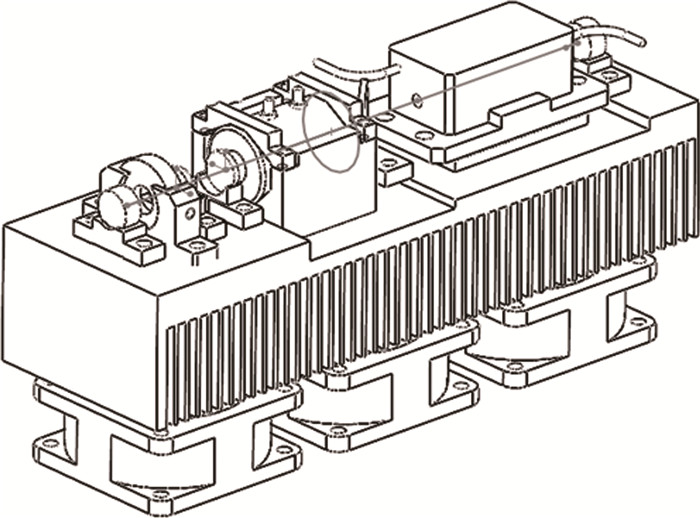
制冷方式采用半导体制冷[10-11], 散热结构如图 3所示。散热结构从上到下包括LD、半导体热电制冷片(thermo electric cooler, TEC)、散热器、风扇4个部分组成,且LD和TEC、TEC和翅片之间涂有导热硅脂以减少它们接触热阻,导热硅脂的接触热阻平均为0.000129 m2·K/W,模块底面约为80 mm×40 mm,则LD和TEC、TEC和翅片的接触热阻约为0.05 m2·K/W。散热系统需要散去的总热量包括LD的热量、TEC自身产生的热量。
下面计算TEC自身产生的热量[12]。设定TEC冷面的温度为Tc、热面的温度为Th, LD的工作温度要求恒温25 ℃工作,产生的总热量为6.7 W。根据热传导理论可知,热流量是热阻和温差的乘积,已知LD总的热量6.7 W、LD和TEC热阻为0.05 K/W, 则TEC冷面的温度为Tc≈25.3 ℃,TEC尺寸为29.8 mm×29.8 mm, 每片TEC的热面温度Th≈50 ℃,最大温差为83 ℃,当TEC冷热面温差为0 ℃时,最大制冷量为32 W、功耗为60 W。已知TEC冷面的温度Tc≈25.3 ℃,则TEC冷热面温差Th≈25 ℃,TEC的制冷量和功耗约为最大制冷量和功耗的30%,计算可知,TEC自身产生的热量约为18 W,再增加10%设计冗余,则TEC总的传热量约为27.6 W。设散热系统中散热器和风扇需要散热量为Qc,因稳态热传导过程,Qc和TEC总的传热量相当,则取Qc=28 W。
2.3 散热器和风扇的选型
已知TEC热面温度Th≈50 ℃, TEC和翅片的接触热阻约为0.05 m2·K/W, 散热器上表面温度为51.4 ℃,散热器材料为铝合金,导热系数为120 W/(m· K)。令散热器长度为L,宽度为w,底厚为l, 则L=100 mm,w=60 mm,l=5 mm,高度为30 mm,齿厚为1 mm,齿距为15 mm。
设散热器的热阻为R,其上下表面温差为ΔT,热流通过的面积为A1有:
A_1=L w (5) 利用参考文献[13]中的公式,计算可得:A1=0.006 m2、R=0.0069 K/W、ΔT=0.193 ℃,则散热器下表面温度为50.193 ℃。
已知激光器环境最高温度为40 ℃,且当环境温度为40 ℃时,空气密度ρ=1.131 kg/m3,空气比定压热容cp≈1 kJ/(kg·K),粘滞系数ν≈0.0000167 m2/s、普朗特数Pr≈0.7。设散热面积为A2、散热器数量为n、散热器和空气之间的平均表面传热系数为h,已知所需散热量Qc=28 W, 散热器和空气之间的最小温差约10 ℃,由下式:
A_2=n L h+L w (6) h=\frac{Q_{\mathrm{c}}}{10 A_2} (7) 可得:A2=0.036 m2,h=54 W/(m2·K), 选用风扇的风速u=9 m/s。
3. 实验
3.1 谐振腔类型和调Q方式的选择
谐振腔有折叠腔[14]、环形腔[15]、直腔[16],不同腔型的特点如下:(a)折叠腔。腔内一般有两个束腰,其中一个束腰位置放置激光晶体,另一个束腰位置用来放置倍频晶体,通常多应用在端面抽运腔内倍频激光器中; (b)环形腔。环形腔可以用来消除腔内的空间烧孔效应,多用于单纵模输出激光器中; (c)直腔。直腔结构简单,易于调试,适合直接输出基频光。相比下,实验中采用的直腔结构[17]更为合适,
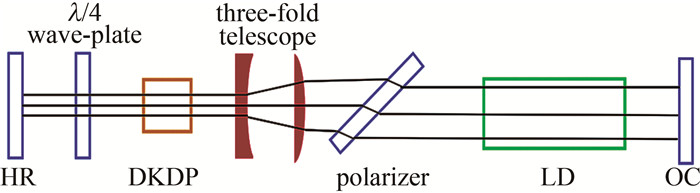
调Q方式按是否有源分为主动调Q和被动调Q,其中被动调Q多用于充当种子源的二极管端面抽运的低能量激光器,在高能量激光器中采用被动调Q方式获得的调Q激光一般稳定性很差[18], 且易于出现多脉冲,因此,为了获得稳定的脉冲激光输出且要脉宽足够窄,选择采用电光加压调Q方式对激光脉宽进行调制。望远镜腔电光调Q激光器实验光路如图 4所示。
![图 4 望远镜腔电光调Q激光器实验光路图]() 图 4 望远镜腔电光调Q激光器实验光路图Figure 4. Diagram of the experimental optical path of the electro-optical Q-switched laser in the telescope cavity
图 4 望远镜腔电光调Q激光器实验光路图Figure 4. Diagram of the experimental optical path of the electro-optical Q-switched laser in the telescope cavity图 4中, 高反(high reflectivity, HR)镜为曲率5 m的1064 nm全反镜, λ/4为真零级λ/4玻片, DKDP为电压3600 V的电光Q开关[19], LD为2400 W传导冷却脉冲模块, 输出耦合镜(output couple, OC)为透过率70%的平面镜。
3.2 实验结果
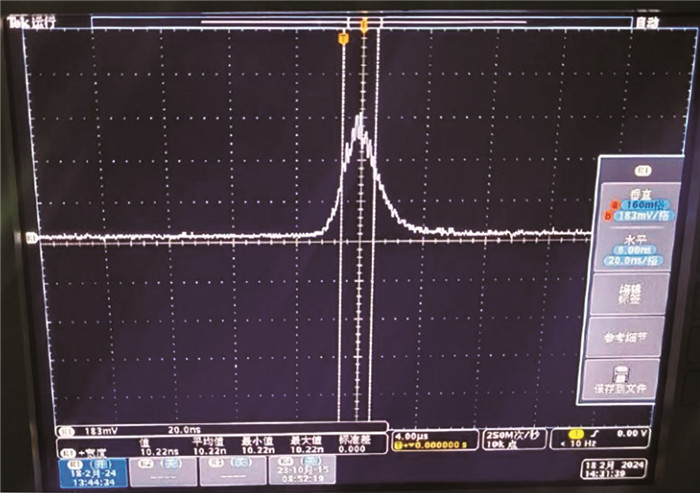
最大输出为100 Hz、480 mJ的808 nm脉冲抽运光。当抽运光输出为10 Hz、350 mJ时,输出1064 nm激光的单脉冲能量为100 mJ,输出激光近场光斑3 mm,2.5 m远场光斑4.5 mm, 发散角0.6 mrad, 激光脉宽约10 ns。激光光斑大小如图 5所示。
激光脉宽如图 6所示。
设激光出光口光斑半径为d、远场发散角全角为θ,根据激光原理可知[20],1064 nm多模高斯激光光束质量因子M2定义为:
M^2=\frac{d \theta}{0.688} (8) 由此可计算出实际输出激光的M2=1.31。
望远镜腔电光调Q激光器模型如图 7所示。
![图 7 望远镜腔电光调Q激光器模型图]() 图 7 望远镜腔电光调Q激光器模型图Figure 7. Telescope cavity electro-optical Q-switched laser model diagram
图 7 望远镜腔电光调Q激光器模型图Figure 7. Telescope cavity electro-optical Q-switched laser model diagram4. 结论
设计了一种风冷近基模小型固体电光调Q激光器,当频率10 Hz时,可输出单脉冲能量为100 mJ、光束质量因子为1.31、脉宽为10.22 ns、发散角为0.6 mrad的1064 nm激光。该激光器结构紧凑、抗形变能力强,可在环境温度40 ℃以下使用,适用于激光测距、激光测速、激光目标指示、激光雷达等多种应用场景。
-
![]()
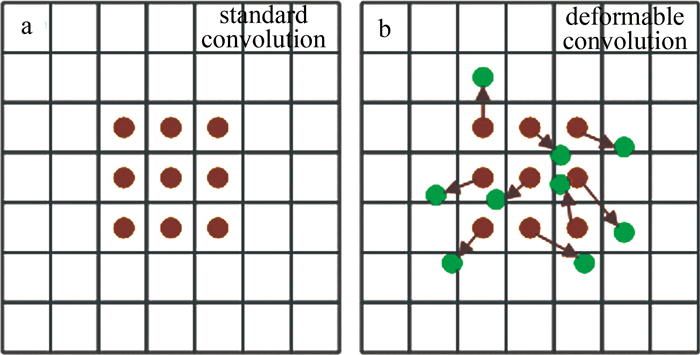
图 9 标准卷积和可变形卷积的采样示意图
Figure 9. Sampling diagram of standard and deformable convolution
表 1 实验平台
Table 1 Experimental platform
component configuration central processing unit AMD 3900X memory 32 Gbyte GPU NVIDIA GTX3090 CUDA software platform 11.1 operation system Ubuntu 20.04 Python version Python 3.8 Pytorch version Pytorch 1.8.1  下载: 导出CSV
下载: 导出CSV
表 2 SPPF-GB模块实验
Table 2 Experiment of SPPF-GB module
model parameter number/106 mAP@0.50/% mAP@0.50~0.95/% frame rate/s-1 SPP 5.85 68.7 44.5 294 SPPF 5.85 68.3 44.9 294 SPPCSPC 6.05 69.1 45.8 244 SPPF-GB 5.89 69.3 45.6 244
下载: 导出CSV
表 3 C2f-GAM模块设计实验
Table 3 Design experiment of C2f-GAM module
model parameter number/10-6 mAP@0.50/% mAP@0.50~0.95/% frame rate/s-1 baseline 3.82 67.4 44.5 294 SE 4.62 68.4 45.1 256 NAM 4.62 68.7 45.8 270 CA 4.63 68.1 45.4 238 MHSA 4.73 68.0 44.0 270 CBAM 4.62 68.7 45.4 244 GAM 4.87 69.1 46.7 244
下载: 导出CSV
表 4 消融实验
Table 4 Ablation experiment
plan GB C2f-GAM SPPF-GB DCN parameter number/106 mAP@0.50/% mAP@0.50~0.95/% frame rate/s-1 model size/Mbit 1 6.05 69.1 45.8 244 12.3 2 √ 3.82 67.4 44.5 294 7.9 3 √ √ 4.87 69.1 46.7 244 10.0 4 √ √ √ 4.71 69.4 47.1 294 9.7 5 √ √ √ √ 4.82 70.3 49.1 294 10.0
下载: 导出CSV
表 5 主流检测算法性能对比
Table 5 Performance comparison of mainstream detection algorithms
model parameter number/106 mAP@0.50/% mAP@0.50~0.95/% frame rate/s-1 model size/Mbit faster R-CNN 137.10 66.1 45.2 151 108.0 SSD 62.75 60.6 41.4 64 94.6 YOLOv3-tiny 8.70 53.3 27.1 333 17.5 YOLOv5s 7.06 67.9 44.5 149 14.4 YOLO8n 3.01 67.9 47.0 244 6.2 YOLOv7-tiny 6.05 69.1 45.8 244 12.3 ours 4.82 70.3 49.1 294 10.0
下载: 导出CSV
-
[1] ERDAW H B, TAYE Y G, LEMMA D T. A real-time obstacle detection and classification system for assisting blind and visually impaired people based on Yolo model[C]//2023 International Conference on Information and Communication Technology for Development for Africa (ICT4DA). New York, USA: IEEE Press, 2023: 79-84.
[2] DUMAN S, ELEWI A, YETGIN Z. Design and implementation of an embedded real-time system for guiding visually impaired individuals[C]//2019 International Artificial Intelligence and Data Processing Symposium (IDAP). New York, USA: IEEE Press, 2019: 1-5.
[3] ESPINACE P, KOLLAR T, SOTO A, et al. Indoor scene recognition through object detection[C]//2010 IEEE International Conference on Robotics and Automation. New York, USA: IEEE Press, 2010: 1406-1413.
[4] KIM J, LEE C H, YOUNGC, et al. Optical sensor based object detection for autonomous robots[C]//20118th International Conference on Ubiquitous Robots and Ambient Intelligence(URAI). New York, USA: IEEE Press, 2011: 746-754.
[5] 李维刚, 杨潮, 蒋林, 等. 基于改进YOLOv4算法的室内场景目标检测[J]. 激光与光电子学进展, 2022, 59(18): 1815003. LI W G, YANG Ch, JING L, et al. Indoor scene object detection based on improved YOLOv4 algorithm[J]. Laser & Optoelectronics Progress, 2022, 59(18): 1815003(in Chinese).
[6] GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE Press, 2014: 580-587.
[7] REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection[C]//Procee Dings of the IEEE Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE Press, 2016: 779-788.
[8] WU T H, WANG T W, LIU Y Q. Real-time vehicle and distance detection based on improved yolov5 network[C]//2021 3rd World Symposium on Artificial Intelligence (WSAI). New York, USA: IEEE Press, 2021: 24-28.
[9] JIANG L, NIE W, ZHU J, et al. Lightweight object detection network model suitable for indoor mobile robots[J]. Journal of Mechanical Science and Technology, 2022, 36(2): 907-920. DOI: 10.1007/s12206-022-0138-2
[10] LIU W, ANGUELOV D, ERHAN D, et al. SSD: Single shot multibox detector[C]//Computer Vision-ECCV 2016: 14th European Conference. New York, USA: Springer Press, 2016: 21-37.
[11] 薄景文, 张春堂. 基于YOLOv3的轻量化口罩佩戴检测算法[J]. 电子测量技术, 2021, 44(23): 105-110. BO J W, ZHANG Ch T. Lightweight mask wear detection algorithm based on YOLOv3[J]. Electronic Measurement Technology, 2021, 44(23): 105-110(in Chinese).
[12] MA N, ZHANG X, ZHENG H T, et al. Shufflenetv2: Practical guidelines for efficient CNN architecture design[C]//Proceedings of the European conference on computer vision (ECCV). New York, USA: IEEE Press, 2018: 116-131.
[13] 李成跃, 姚剑敏, 林志贤, 等. 基于改进YOLO轻量化网络的目标检测方法[J]. 激光与光电子学进展, 2020, 57(14): 141003. LI Ch Y, YAO J M, LIN Zh X, et al. Object detection method Based on improved YOLO lightweight network[J]. Laser & Optoelectronics Progress, 2019, 57(14): 141003(in Chinese).
[14] REDMON J, FARHADI A. Yolov3: An incremental improvement[C]//IEEE Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE Press, 2018: 45-48.
[15] 裴瑞景, 王硕, 王华英. 基于改进YOLOv4算法的水果识别检测研究[J]. 激光技术, 2023, 47(3): 400-406. DOI: 10.7510/jgjs.issn.1001-3806.2023.03.018 PEI R J, WANG Sh, WANG H Y. Research on fruit recognition detection algorithm based on improved YOLOv4[J]. Laser Technology, 2023, 47(3): 400-406(in Chinese). DOI: 10.7510/jgjs.issn.1001-3806.2023.03.018
[16] TANG H, LIANG S, YAO D, et al. A visual defect detection for optics lens based on the YOLOv5-C3CA-SPPF network model[J]. Optics Express, 2023, 31(2): 2628-2643. DOI: 10.1364/OE.480816
[17] WANG C Y, BOCHKOVSKIY A, LIAO H Y M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE Press, 2023: 7464-7475.
[18] HAN K, WANG Y, TIAN Q, et al. Ghostnet: More features from cheap operations[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE Press, 2020: 1580-1589.
[19] LOU H T, DUAN X H, GUO J M, et al. DC-YOLOv8: Small-size object detection algorithm based on camera sensor[J]. Electronics, 2023, 12(10): 2323. DOI: 10.3390/electronics12102323
[20] LIU Y, SHAO Z, HOFFMANN N. Global attention mechanism: Retain information to enhance channel-spatial interactions[EB/OL]. (2021-12-10)[2024-01-16]. https://arxiv.org/abs/2112.05561.
[21] DAI J, QI H, XIONG Y, et al. Deformable convolutional networks[C]//Proceedings of the IEEE International Conference on Computer Vision. New York, USA: IEEE Press, 2017: 764-773.
[22] ZHANG X Y, ZHOU X Y, LIN M X. ShuffleNet: an extremely effificient convolutional neural network for mobile devices[C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE Press, 2018: 00716.
[23] HOWARD A G, ZHU M, CHEN B, et al. Mobilenets: Efficient convolutional neural networks for mobile vision applications[EB/OL]. (2017-04-17)[2024-01-26]. https://arxiv.org/abs/1704.04861.
[24] HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE Press, 2016: 770-778.
[25] HE K, ZHANG X, REN S, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(9): 1904-1916. DOI: 10.1109/TPAMI.2015.2389824
[26] 杨文瀚, 廖苗. 融合注意力机制与残差可形变卷积的肝肿瘤分割方法[J]. 激光与光电子学进展, 2023, 60(12): 1210001. YANG W H, LIAO M. Fusion of dual attention and deform-able residual convolution for segmentation of liver tumor[J]. Laser & Optoelectronics Progress, 2023, 60(12): 1210001(in Chinese).
[27] 李子茂, 李嘉晖, 尹帆, 等. 基于可形变卷积与SimAM注意力的密集柑橘检测算法[J]. 中国农机化学报, 2023, 44(2): 156-162. LI Z M, LI J H, YIN F, et al. Dense citrus detection algorithm based on deformable convolution and SimAM attention[J]. Journal of Chinese Agricultural Mechanization, 2023, 44 (2): 156-162(in Chinese).
[28] SILBERMAN N, HOIEM D, KOHLI P, et al. Indoor segmentation and support inference from rgbd images[C]//Computer Vision-ECCV 2012: 12th European Conference on Computer Vision. New York, USA: Springer Press, 2012: 746-760.
[29] QUATTONI A, TORRALBA A. Recognizing indoor scenes[C]//2009 IEEE Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE Press, 2009: 413-420.
[30] XIAO J, HAYS J, EHINGER K A, et al. Sun database: Large-scale scene recognition from abbey to zoo[C]//2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE Press, 2010: 3485-3492.
[31] LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: Common objects in context[C]//Computer Vision-ECCV 2014: 13th European Conference. New York, USA: Springer Press, 2014: 740-755.
[32] HU J, SHEN L, SUN G. Squeeze-and-excitation networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE Press, 2018: 7132-7141.
[33] LIU Y, SHAO Z, TENG Y, et al. NAM: Normalization-based attention module[EB/OL]. (2021-11-24)[2024-01-26]. https://arxiv.org/abs/2111.12419.
[34] HOU Q, ZHOU D, FENG J. Coordinate attention for efficient mobile network design[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE Press, 2021: 13713-13722.
[35] SRINIVAS A, LIN T Y, PARMAR N, et al. Bottleneck transformers for visual recognition[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE Press, 2021: 16519-16529.
[36] WOO S Y, PARK J C, LEE J Y, et al. CBAM: Convolutional block attention module[C]//Proceedings of the European Conference on Computer Vision(ECCV). New York, USA: Springer Press, 2018: 3-19.
[37] REN S Q, HE K M, GIRSHICK R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149.





计量
- 文章访问数: 3
- HTML全文浏览量: 0
- PDF下载量: 1