
Research on laser speckle image recognition technology based on transfer learning
-
摘要: 为了解决激光散斑对高于20 ℃时的水温存在测量灵敏度下降等问题,提出了一种基于深度学习的激光散斑图像识别探测方法,构建了20.1 ℃、20.2 ℃及20.3 ℃的散斑图像数据集,采用一种多尺度卷积神经网络,结合适当的损失函数和数据增强技术,以优化激光散斑图像的特点; 通过深度学习模型在散斑数据集上的训练与测试实验,实现了水下温度信息散斑图像的高准确率识别,解决了对比度饱和测量灵敏度下降的问题。结果表明,与AlexNet、VGG、ResNet模型相比,GoogleNet模型对散斑图像的水下温度识别准确率达到了99%。该研究为深入了解温度场分布及其影响提供了理论支持,并为相关应用领域提供了有价值的参考。Abstract: In order to solve the problem that the measurement sensitivity of laser speckles decreases when the water temperature is higher than 20 ℃, a laser speckle image recognition and detection method based on depth learning is proposed. The speckle image data sets of 20.1 ℃, 20.2 ℃, and 20.3 ℃ were constructed. A multi-scale convolution neural network was used, combined with appropriate loss function and data enhancement technology, to optimize the characteristics of laser speckle images. Through the training and testing experiments of deep learning models on speckle datasets, high accuracy recognition of underwater temperature information speckle images was achieved, solving the problem of decreased sensitivity in contrast saturation measurement. The experimental results show that compared with AlexNet, VGG, and ResNet models, the accuracy of the GoogleNet model in underwater temperature recognition of speckle images reaches 99%. This study provides theoretical support for the in-depth understanding of temperature field distribution and its impact and provides valuable reference for related application fields.
-
Keywords:
- image processing /
- speckle images /
- deep learning /
- GoogleNet /
- classification recognition
-
0. 引言
利用遥感技术获取的高光谱图像,作为一个数据立方体,结合了用于表征物质反射特性的光谱信息以及用于刻画物质2维空间分布的图像信息[1]。凭借其强大的空间与光谱信息的表达能力,高光谱图像被广泛应用于物质分类[2]、环境监测、军事目标的检测与分析等[3]领域。高光谱图像在采集与处理过程中容易受到各种噪声的干扰[4],这对后续的高光谱图像的应用,如高光谱图像的分类[5]、目标检测[6]以及目标分割[7]等,都有一定的影响。因此,在有效去除噪声的基础上,恢复重建高分辨率的图像成为遥感图像领域研究的热点。
基于先验的去噪方法可以精确地表达出高光谱图像的空谱信息分布特点。依据空谱特征描述方式的不同,先验方法可以更为精确地划分为基于平滑的去噪方法[8]、基于全局自相似的去噪方法[8]、基于低秩的去噪方法[9]以及基于深度学习的去噪方法。本文作者[10]曾通过构建空谱平滑图正则的方式, 实现基于塔克分解的低秩模型算法的扩展,但现有的基于平滑的方法容易陷入过平滑造成的细节信息丢失。ZENG等人[11]通过张量分解(block term decomposition,BTD) 的手段深入探究相似立体补丁组的光谱局部联系与空间的全局相关性,但基于全局自相似的方法采用的块匹配方法往往涉及较大计算量,会造成运算成本加剧。WANG等人[12]构建了一个融合了空谱全变分的低秩塔克分解模型,可以充分利用高光谱图像的空谱全局与局部相关性并恢复出高质量的去噪图像。然而,基于矩阵模型的算法面临着立体结构信息被破坏的问题。XIONG等人[9]尝试将全局注意力机制模块引入到传统的U型网络(U-Net),可以实现同时捕获空间的全局与局部信息。上述基于监督学习的方法通常涉及大量的数据训练以及超参数,会导致计算负担的增加。
变换域的出现为高光谱图像的去噪研究开辟了一条全新的道路。图像经变换后, 主要信息会集中到低频部分,细节信息则在高频部分[13]。针对变换域的特点从张量秩[14]、平滑[15]、深度学习[16]等不同角度对去噪方法进行了探索。KONG等人[14]研究了基于紧框架的张量纤维秩以及对应的凸松弛来表达三模张量核范数,可以更好地刻画高光谱图像不同维度的低秩性。但总体来看,基于变换域的张量核范数方法由于涉及到大数据的奇异值分解计算,面临着计算复杂度过高的问题。XU等人[15]尝试通过非负矩阵分解得到丰度矩阵在曲线波域的稀疏特性,但基于变换域平滑的方法不能充分利用不同频段的图像特征信息。考虑到小波变换可以利用不同频段,实现高斯噪声与条带噪声的有效分离,PAN等人[16]设计了多层3维卷积低频网络和结合渐进式空谱混合卷积块的高频卷积神经网络,可以较好地学习变换域下图像不同频段的空谱潜在特征,然而基于变换域的深度学习模型仍存在着可解释性差以及网络复杂度高等问题。
为了克服上述问题,本文作者提出将基于变换域的正则与深度学习模型相结合,构建无监督学习的噪声去除模型。首先,对无监督去噪模型展开探索,规避了监督去噪模型缺乏大量高光谱训练数据的缺陷,同时通过增加传统高光谱图像的先验优化改善了基于深度图像先验涉及到的半拟合现象;然后通过构建端元矩阵与丰度矩阵在变换域中的稀疏正则实现空谱局部平滑;最后, 设计迭代算法求解模型得到高质量的恢复图像,同时加速网络学习并获得更好的性能。
1. 去噪模型
1.1 空谱深度图像先验去噪模型
假设F ∈ Rm×n×p表示高光谱立体图像,R表示实数集,利用矩阵分解可将高光谱立体数据F重塑为矩阵形式Y =[y1, …, yi, …, yc],其中yi∈ Rp被定义为第i个像素对应的光谱向量。由于纯高光谱数据可以利用线性混合模型分解为端元矩阵与丰度矩阵的乘积,则噪声扰动的退化模型可以定义为:
\boldsymbol{Y}=\boldsymbol{A} \boldsymbol{X}+\boldsymbol{S}+\boldsymbol{N} (1) 式中: A ∈ Rp×r表示包含r个端元和p个光谱波段的端元矩阵; X ∈ Rr×c是丰度矩阵; c=m×n代表空间像素数目,其每一列表示对应像素包含的r个端元的分布比例;S ∈ Rp×c表示稀疏噪声;N ∈ Rp×c代表高斯噪声或误差。
在高光谱图像退化模型式(1)的基础上,引入各变量的正则约束定义基于高斯噪声最小化的去噪模型:
\begin{gathered} \min _{{\boldsymbol{A}}, {\boldsymbol{X}}, {\boldsymbol{S}}} \frac{1}{2}{\|\boldsymbol{Y}-\boldsymbol{A} \boldsymbol{X}-\boldsymbol{S}\|_{\mathrm{F}}}^2+ \\ \lambda_A \theta_A(\boldsymbol{A})+\lambda_{\boldsymbol{X}} \theta_{\boldsymbol{X}}(\boldsymbol{X})+\lambda_S \theta_S(\boldsymbol{S}) \end{gathered} (2) 式中: ‖·‖F为Frobenius范数; λAθA(A)、λXθX(X)和λSθS(S)分别代表着端元矩阵、丰度矩阵以及稀疏噪声的正则项。利用深度图像先验分别学习端元矩阵与丰度矩阵的特征,得到空谱深度图像先验去噪模型:
\begin{aligned} & {\min _{f_{\xi_1}\left(\boldsymbol{Z}_1\right), f_{\xi_2}\left(\boldsymbol{Z}_2\right), \boldsymbol{S}} \frac{1}{2}\left\|\boldsymbol{Y}-f_{\xi_1}\left(\boldsymbol{Z}_1\right) f_{\xi_2}\left(\boldsymbol{Z}_2\right)-\boldsymbol{S}\right\|_{\mathrm{F}}}^2+ \\ & \lambda_{\boldsymbol{A }}\theta_{\boldsymbol{A}}\left(f_{\xi_1}\left(\boldsymbol{Z}_1\right)\right)+\lambda_{\boldsymbol{X}} \theta_{\boldsymbol{X}}\left(f_{\xi_2}\left(\boldsymbol{Z}_2\right)\right)+\lambda_{\boldsymbol{S}} \theta_{\boldsymbol{S}}(\boldsymbol{S}) \end{aligned} (3) 式中: fξ1(·)与fξ2(·)分别表示端元矩阵与丰度矩阵的深度图像先验神经网络;ξ1和ξ2代表对应的可学习网络权重;Z1∈ Rp×r及Z2∈ Rr×mn用于生成空谱矩阵的随机输入。
1.2 深度图像先验网络
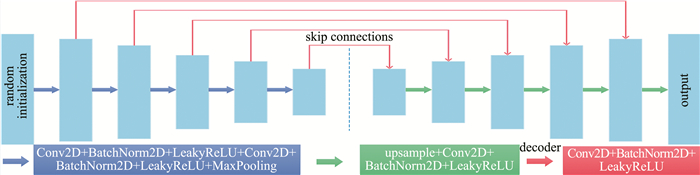
无监督深度图像先验是一个类似于U-Net的带有跳跃连接的沙漏类型卷积神经网络,将随机生成的张量视作网络输入,通过不断调整网络参数值实现图像特征信息的学习。它的特点是: 不需要训练网络用于训练,可以规避监督去噪模型缺乏大量高光谱训练数据的缺陷。基于此,本文作者采用深度图像先验分别学习丰度矩阵与端元矩阵的特征信息,具体的网络结构如图 1所示。图中,upsample是上采样;BatchNorm2D是深度学习中的一种层,用于进行批归一化操作;MaxPooling是最大池化。
设计的深度图像先验网络结构分别包括5层编码层、解码层以及跳跃链接。编码层的每层设计了两组相同的卷积、批标准化与激活模块,可以更好地提取图像的特征信息,其中2维卷积(convolution 2-D,Conv2D)采用大小为3、步长为1的卷积核,带泄露修正线性单元(leaky rectified linear unit,LeakyReLU)作为激活模块可以加速网络的学习过程;解码层通过一系列的上采样、卷积、批标准化与激活等操作,用于解析学习到的图像特征信息;跳跃连接采用大小为1、步长为1的Conv2D模块以及批标准化与激活模块建立相同层级间的编解码特征之间的联系,可以减少下采样操作所引起的信息损失。
2. 去噪算法求解
对于去噪模型式(3),如果仅使用空间与光谱深度图像先验去学习空谱特征,则会导致半拟合现象,造成去噪性能的下降。因此本文中对稀疏噪声施加L1范数正则用于增强其稀疏特性,对端元矩阵与丰度矩阵的局部相关性构建紧框架域平滑正则。综上所述,将去噪模型式重新定义为:
\begin{gathered} {\min _{f_{\xi_1}\left(\boldsymbol{Z}_1\right), f_{\xi_2}\left(\boldsymbol{Z}_2\right), \boldsymbol{S}} \frac{1}{2}\left\|\boldsymbol{Y}-f_{\xi_1}\left(\boldsymbol{Z}_1\right) f_{\xi_2}\left(\boldsymbol{Z}_2\right)-\boldsymbol{S}\right\|_{\mathrm{F}}}^2+ \\ \lambda_{\boldsymbol{A}}\left\|\boldsymbol{W} f_{\xi_1}\left(\boldsymbol{Z}_1\right)\right\|_1+ \\ \lambda_{\boldsymbol{X}}\left\|\boldsymbol{W} f_{\xi_2}\left(\boldsymbol{Z}_2\right)\right\|_1+\lambda_S\|\boldsymbol{S}\|_1 \end{gathered} (4) 式中: W表示紧框架变换矩阵,对于多网络结构优化问题,可以交替迭代ξ1和ξ2网络参数以及稀疏噪声S直到收敛。
用于生成端元矩阵与丰度矩阵的ξ1和ξ2神经网络优化子问题如下:
\begin{aligned} & {\min _{\xi_1, \xi_2, {\boldsymbol{S}}} \frac{1}{2}\left\|\boldsymbol{Y}-f_{\xi_1}\left(\boldsymbol{Z}_1\right) f_{\xi_2}\left(\boldsymbol{Z}_2\right)\right\|_{\mathrm{F}}}^2+ \\ & \lambda_{\boldsymbol{A}}\left\|\boldsymbol{W} f_{\xi_1}\left(\boldsymbol{Z}_1\right)\right\|_1+\lambda_{\boldsymbol{X}}\left\|\boldsymbol{W} f_{\xi_2}\left(\boldsymbol{Z}_2\right)\right\|_1 \end{aligned} (5) 其可以利用动量梯度下降算法求解。
\begin{gathered} \xi_1{ }^{(k+1)}=\xi_1{ }^{(k)}-\alpha^{(k)} \nabla_{\xi_1}\left(\frac{1}{2} \| \boldsymbol{Y}-f_{\xi_1}\left(\boldsymbol{Z}_1\right) f_{\xi_2{ }^{(k)}}\left(\boldsymbol{Z}_2\right)-\right. \\ \left.\boldsymbol{S}\left\|_{\mathrm{F}}{ }^2+\lambda_{\boldsymbol{A}}\right\| \boldsymbol{W} f_{\xi_1}\left(\boldsymbol{Z}_1\right) \|_1\right) \end{gathered} (6) \begin{gathered} \xi_2{ }^{(k+1)}=\xi_2{ }^{(k)}-\alpha^{(k)} \nabla_{\xi_2}\left(\frac{1}{2} \| \boldsymbol{Y}-f_{\xi_1}\left(\boldsymbol{Z}_1\right) f_{\xi_2{ }^{(k)}}\left(\boldsymbol{Z}_2\right)-\right. \\ \left.{\boldsymbol{S}}\left\|_{\mathrm{F}}{ }^2+\lambda_{\boldsymbol{A}}\right\| \boldsymbol{W} f_{\xi_2}\left(\boldsymbol{Z}_2\right) \|_1\right) \end{gathered} (7) 式中: ∇ξ1(·)与∇ξ2(·)分别表示运用反向传播算法计算得到的ξ1和ξ2梯度;α对应着通过自适应矩估计算法确定的步长;k是当前迭代的次数。由此,在更新了网络参数ξ1和ξ2的基础上,可以得到对应的网络输出fξ1(Z1)(k+1)与fξ2(Z2)(k+1)。
针对稀疏噪声S的优化子问题如下:
\begin{array}{c} \arg \min \limits_{\boldsymbol{S}} \frac{1}{2} \| \boldsymbol{Y}-f_{\xi_1(k+1)}\left(\boldsymbol{Z}_1\right) f_{\xi_2{ }^{(k+1)}}\left(\boldsymbol{Z}_2\right)- \\ {\boldsymbol{S}||_{\mathrm{F}}}^2+\lambda_{\boldsymbol{S}}|| \boldsymbol{S} ||_1 \end{array} (8) 其闭式解可以利用软阈值算子得到:
\begin{gathered} \boldsymbol{S}^{(k+1)}= \\ \operatorname{shrink}\left(\boldsymbol{Y}-f_{\xi_1{ }^{(k+1)}}\left(\boldsymbol{Z}_1\right) \boldsymbol{f}_{\xi_2{ }^{(k+1)}}\left(\boldsymbol{Z}_2\right), \lambda_{\boldsymbol{S}}\right) \end{gathered} (9) 本文作者所提出的基于空谱深度图像先验结合紧框架平滑与噪声稀疏先验(spatial spectral depth tight sparse,SSDTS)算法的迭代流程描述如下:
(a) 输入Y,λA,λX,λS;
(b) 随机初始化A(0)和X(0),S(0)=0,k=0;
(c) 当不满足迭代停止条件时,借助式(6)更新ξ1(k+1), 借助式(7)更新ξ2(k+1), 借助式(9)更新S(k+1), k=k+1;
(d) 判断收敛条件为‖ξ1(k+1)ξ2(k+1)-ξ1(k)ξ2(k)‖F2/ ‖ξ1(k)ξ2(k)‖F2≤0.001;
(e) 结束循环;
(f) 输出L =fξ1(Z1)fξ2(Z2)。
3. 实验仿真与性能分析
本文中采用模拟数据集和真实数据集测试和评估SSDTS算法对高光谱图像的去噪能力。在此基础上,选取4种广泛使用的算法作为对比算法,包括低秩矩阵恢复(low-rank matrix recovery,LRMR)[17]、全变分正则化的低秩矩阵分解(the TV-regularized low-rank matrix factorization,LRTV)[18]、利用子空间和深度图像先验的高光谱图像混合噪声去除方法(hyperspectral image mixed noise removal method using subspace representation and deep CNN image prior,HySuDeep)[19]和2维深度图像先验(deep image prior 2D,DIP2D)[20]。与此同时,为了准确可靠地评价图像重建性能,采用4个定量评价指标,分别为平均峰值信噪比(mean peak signal-to-noise ratio,MPSNR)、平均结构相似度(mean structural similarity index measure,MSSIM)、光谱角制图(spectral angle mapper,SAM)和相对无量纲全局误差(erreur relative globale adimensionnelle de synthèse,ERGAS)。另外,作为实验的预处理,将高光谱图像的灰度值归一化到[0, 1]区间。上述所有深度学习的实验结果均在GeForce GTX 2080 Ti处理器上使用Python环境的pytorch库产生。
3.1 模拟数据实验
对于模拟实验,本文作者设计了两个高光谱图像数据集作为参考。一个是Washington DC Mall的子图像,尺寸为120×256×256个像素; 另一个是Salinas数据集,包含192×192个空间像素和130个光谱波段。
3.1.1 噪声设置
方案Ⅰ(高斯噪声与椒盐噪声):采用分布比例为0.1的高斯噪声与椒盐噪声污染高光谱图像的所有波段。
方案Ⅱ(高斯噪声与条带噪声):对于受到与方案Ⅰ相同的高斯噪声污染的高光谱图像,随机选择波段添加条带噪声,其波段数量占所有波段数目的0.5,每个波段中条带的数量从5~15间随机变化。
方案Ⅲ(高斯噪声与截止噪声):包含与方案Ⅰ相同的高斯噪声和随机选择的波段上的截止噪声,其波段数量占所有波段数目的0.5。与此同时,截止噪声的宽度从1~3随机变化,每个波段存在的截止噪声总数在[6, 10]之间。
方案Ⅳ(高斯噪声与混合稀疏噪声):在每个高光谱图像波段中,添加与方案Ⅰ、方案Ⅱ和方案Ⅲ相同的高斯噪声、椒盐噪声、条带噪声和截止噪声。
3.1.2 去噪图像分析
如图 2所示,Washington DC Mall图像遭受到严重的高斯噪声与椒盐噪声的污染,LRTV和DIP2D算法生成的去噪图像仍残存着明显的噪声,LRMR和HySuDeep算法去除噪声效果较好,但存在着图像细节信息的丢失,本文中提出的SSDTS算法可以最大程度地消除噪声,并准确地描述图像的细节。对比图 3可以发现,本文中所提出的SSDTS算法还具有较为理想的去噪结果,LRMR、LRTV和DIP2D算法对于高斯噪声与多种稀疏噪声的混合具有较差的抑制性,HySuDeep算法对应的重构图像面临着过度平滑的现象。综上所述,SSDTS算法在各种复杂、严重的噪声干扰下均表现出较好的视觉恢复性能。
![图 2 Washington DC Mall数据集第100个波段在方案Ⅰ下的去噪图像]() 图 2 Washington DC Mall数据集第100个波段在方案Ⅰ下的去噪图像Figure 2. The denoised results of the 100th band in Washington DC Mall dataset under case Ⅰ
图 2 Washington DC Mall数据集第100个波段在方案Ⅰ下的去噪图像Figure 2. The denoised results of the 100th band in Washington DC Mall dataset under case Ⅰ![图 3 Salinas数据集第100个波段在方案Ⅳ下的去噪图像]() 图 3 Salinas数据集第100个波段在方案Ⅳ下的去噪图像Figure 3. The denoised results of the 100th band in Salinas dataset under case Ⅳ
图 3 Salinas数据集第100个波段在方案Ⅳ下的去噪图像Figure 3. The denoised results of the 100th band in Salinas dataset under case Ⅳ3.1.3 去噪指标分析
表 1和表 2中对比了SSDTS算法与4种算法在Washington DC Mall和Salinas数据集上产生的评价指标值。相对于其它算法,SSDTS算法产生的平均峰值信噪比值提高了1 dB以上,对应的ERGAS值至少降低了10%。这说明本文中提出的方法在严重的高斯噪声或稀疏噪声的污染下,依然能获得更为理想的重构图像。从整体结果来看,SSDTS算法在几乎所有评价指标上都取得了令人满意的性能。
表 1 Washington DC Mall的去噪图像性能对比Table 1. Performance comparison of denoising images on Washington DC Mallcase index LRMR LRTV HySuDeep DIP2D proposed Ⅰ MPSNR/dB 32.63 27.63 29.43 26.97 33.31 MSSIM 0.926 0.859 0.907 0.849 0.938 SAM 0.0837 0.127 0.153 0.121 0.069 ERGAS 75.86 152.31 127.10 145.63 70.14 Ⅱ MPSNR/dB 32.93 32.12 29.72 27.59 33.81 MSSIM 0.934 0.928 0.913 0.844 0.948 SAM 0.082 0.094 0.150 0.129 0.065 ERGAS 73.46 90.12 125.68 140.33 66.39 Ⅲ MPSNR/dB 31.43 31.96 29.54 32.31 34.15 MSSIM 0.925 0.934 0.913 0.934 0.949 SAM 0.101 0.083 0.151 0.071 0.065 ERGAS 92.39 89.38 126.43 78.87 63.85 Ⅳ MPSNR/dB 30.24 26.42 28.92 25.04 32.73 MSSIM 0.906 0.829 0.901 0.789 0.931 SAM 0.114 0.166 0.156 0.154 0.075 ERGAS 103.71 181.25 136.37 187.67 74.83 表 2 Salinas的去噪图像性能对比Table 2. Performance comparison of denoising images on Salinasscase index LRMR LRTV HySuDeep DIP2D proposed Ⅰ MPSNR/dB 34.69 29.26 31.98 29.62 36.03 MSSIM 0.848 0.778 0.907 0.763 0.895 SAM 0.040 0.089 0.069 0.068 0.034 ERGAS 89.86 628.62 107.14 338.15 66.70 Ⅱ MPSNR/dB 34.35 33.95 32.22 32.01 35.86 MSSIM 0.857 0.880 0.917 0.823 0.894 SAM 0.043 0.068 0.069 0.053 0.035 ERGAS 186.45 583.89 112.05 271.69 65.24 Ⅲ MPSNR/dB 30.68 31.42 32.16 35.39 36.69 MSSIM 0.815 0.855 0.926 0.884 0.905 SAM 0.083 0.088 0.071 0.035 0.033 ERGAS 127.43 109.72 86.83 78.07 55.54 Ⅳ MPSNR/dB 29.19 26.40 31.04 27.92 35.20 MSSIM 0.767 0.715 0.884 0.728 0.881 SAM 0.090 0.127 0.074 0.093 0.036 ERGAS 197.29 961.37 154.44 583.71 91.20 3.1.4 去噪曲线分析
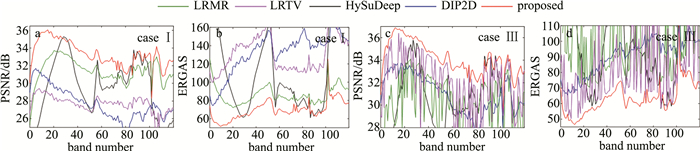
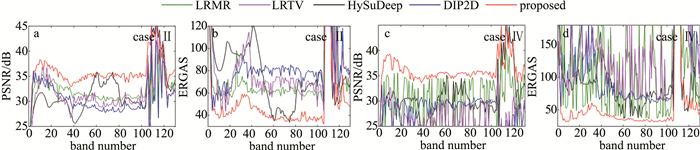
图 4和图 5中绘制了SSDTS算法与所有对比算法在受到不同噪声方案污染的Washington DC Mall和Salinas数据集上产生的峰值信噪比(peak signal-to-noise ratio,PSNR)和ERGAS曲线。值得注意的是,本文中提出的SSDTS算法产生的PSNR曲线优于由对比算法生成的其它曲线;而SSDTS算法对应的ERGAS曲线在绝大多数波段得到最低值。上述性能曲线变化情况表明,SSDTS去噪算法在大部分波段获得了最理想的结果。同时,也从侧面证明,不同于仅采用深度图像先验的DIP2D算法,本文中所提出的空谱深度图像先验结合紧框架域平滑正则在图像去噪领域中可以产生更加满意的结果。
![图 4 在方案Ⅰ与Ⅲ下Washington DC Mall数据集所有波段的PSNR与ERGAS值]() 图 4 在方案Ⅰ与Ⅲ下Washington DC Mall数据集所有波段的PSNR与ERGAS值Figure 4. PSNR and ERGAS values of all bands in Washington DC Mall dataset under case Ⅰ and Ⅲ
图 4 在方案Ⅰ与Ⅲ下Washington DC Mall数据集所有波段的PSNR与ERGAS值Figure 4. PSNR and ERGAS values of all bands in Washington DC Mall dataset under case Ⅰ and Ⅲ![图 5 在方案Ⅱ与Ⅳ下Salinas数据集所有波段的PSNR与ERGAS值]() 图 5 在方案Ⅱ与Ⅳ下Salinas数据集所有波段的PSNR与ERGAS值Figure 5. PSNR and ERGAS values of all bands in Salinas dataset under case Ⅱ and Ⅳ
图 5 在方案Ⅱ与Ⅳ下Salinas数据集所有波段的PSNR与ERGAS值Figure 5. PSNR and ERGAS values of all bands in Salinas dataset under case Ⅱ and Ⅳ3.2 真实数据实验
为了验证本文作者所提出的算法对于真实噪声的去除仍具有有效性,选取由传感器直接采集的WHU HongHu数据集,包含150个光谱波段和192×192个空间像素。图 6展示出经过所有去噪方法的优化处理后的WHU HongHu数据集在第2个波段的重构结果。可以明显观察到,HySuDeep与DIP2D算法对真实噪声的抑制效果有限。其它两个对比算法可以实现较好地去噪,但会造成图像局部特征信息的模糊。相比之下,由于深度图像先验模型与传统的变换域平滑先验的结合,本文作者提出的算法能够在最大限度地消除噪声的同时, 精确地保留图像细节信息。
![图 6 WHU HongHu数据集第2个波段的去噪结果]() 图 6 WHU HongHu数据集第2个波段的去噪结果Figure 6. The denoised results of the 2nd band in WHU HongHu dataset
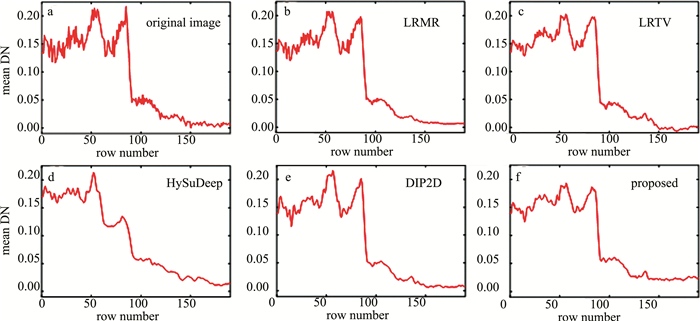
图 6 WHU HongHu数据集第2个波段的去噪结果Figure 6. The denoised results of the 2nd band in WHU HongHu dataset由于缺乏干净图像作为参考,采用水平均值剖面图作为图像质量评价指标,通过遥感影像平均像元亮度值(digital number,DN)记录地物的灰度值。仔细对比图 7中各个剖面图的变化趋势可知,由LRMR、LRTV、HySuDeep与DIP2D这4种对比算法产生的剖面图在局部位置仍存在明显的波动,这说明对应的去噪图像中存在着噪声残留。而本文作者提出的SSDTS算法对应的水平均值剖面图平滑效果最好。
![图 7 WHU HongHu数据集第2个波段的水平均值剖面图]() 图 7 WHU HongHu数据集第2个波段的水平均值剖面图Figure 7. Horizontal mean profile of the 2nd band in WHU HongHu dataset
图 7 WHU HongHu数据集第2个波段的水平均值剖面图Figure 7. Horizontal mean profile of the 2nd band in WHU HongHu dataset3.3 参数讨论
图 8反映了方案Ⅱ下的模拟数据集的MPSNR与λA、λX、λS和端元数目r的关系。由图可知,当λA的值设为0.1、λX的值设为0.2、λS值设为0.1、r选择为5时,在Washington DC Mall与Salinas数据集上产生的MPSNR值均达到了最优性能的近似值。
3.4 收敛性分析
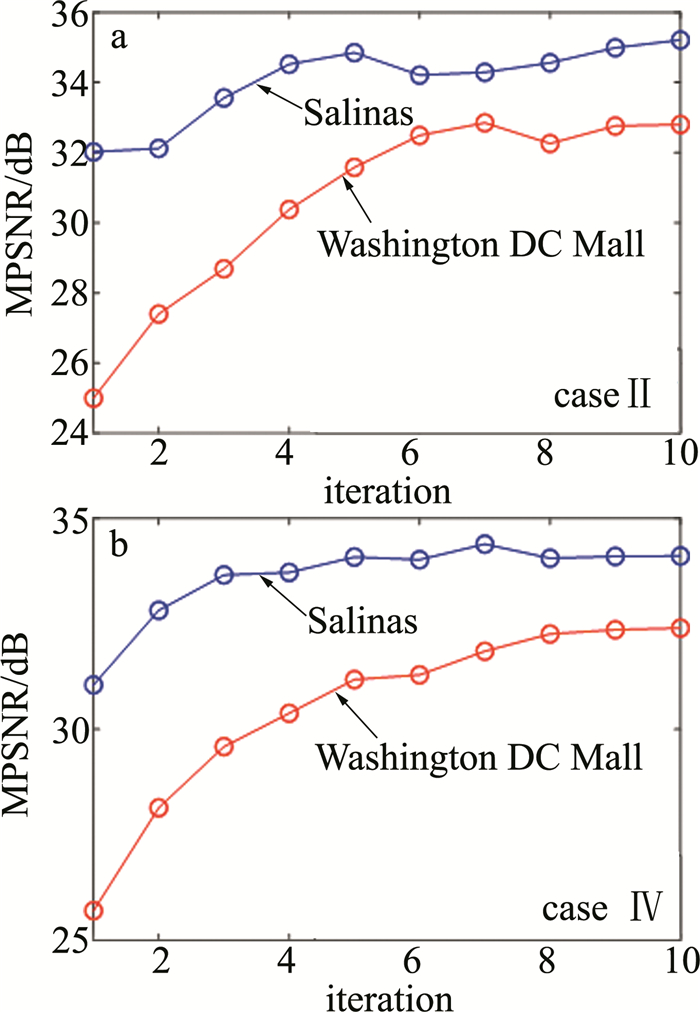
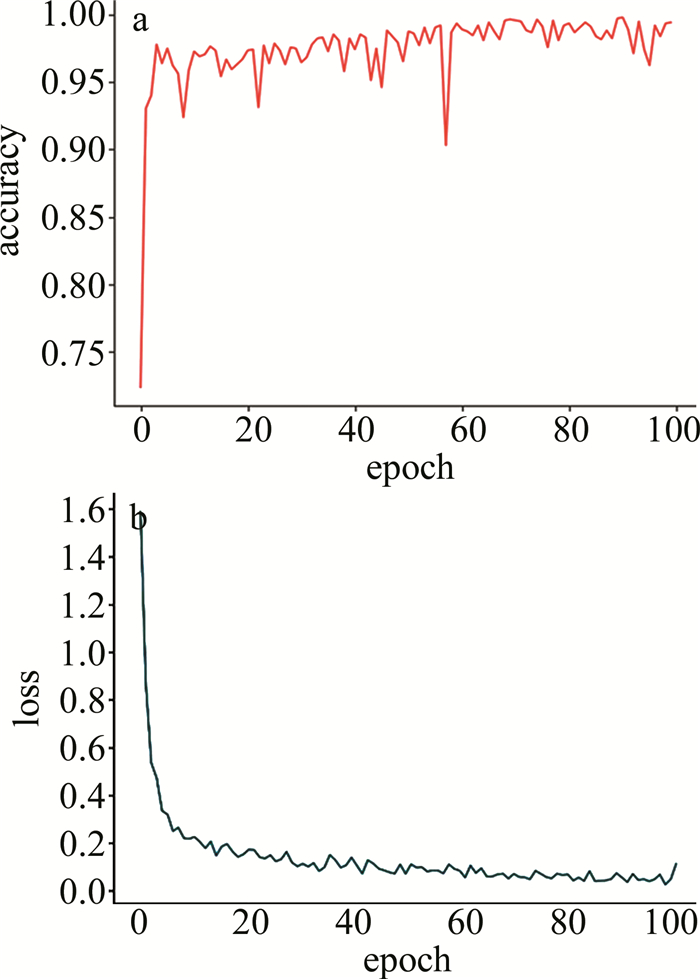
从图 9中可以明显观察到,随着迭代次数的增加,MPSNR对应的曲线均逐渐趋向于平稳的理想结果,这表明本文作者提出的SSDTS算法具有理想的收敛性,同时也从侧面证明SSDTS算法中采用的噪声稀疏与变换域平滑正则项可以有效改善深度图像网络存在的半拟合问题,在充分学习图像特征达到最佳评价指标结果后, 没有产生继续学习噪声特征导致性能下降的现象。
![图 9 不同方案下MPSNR与迭代次数间的关系]() 图 9 不同方案下MPSNR与迭代次数间的关系Figure 9. Relationship between iteration number and MPSNR in different cases
图 9 不同方案下MPSNR与迭代次数间的关系Figure 9. Relationship between iteration number and MPSNR in different cases3.5 消融实验
为了验证本文作者提出的将深度学习与传统先验结合的有效性,设计了空谱深度图像先验(spatial spectral depth image prior,SSDIP)算法、空谱深度图像先验结合稀疏噪声正则(spatial spectral depth sparse noise,SSDSN) 算法、空谱深度图像先验结合紧框架平滑先验正则(spatial spectral depth frame smoothing,SSDFS)算法和提出的SSDTS算法的对比实验。从表 3可知,在受到不同程度混合噪声干扰下,相对于其它3种算法,本文作者提出的SSDTS算法均呈现出更加理想的去噪表现,这证明了本文中将空谱深度图像先验与紧框架平滑以及噪声稀疏先验相结合的合理性。
表 3 不同张量核范数方法的性能对比Table 3. Performance comparison of different tensor nuclear norm methoddata case method MPSNR/dB MSSIM SAM ERGAS Washington DC Mall Ⅱ SSDIP 31.69 0.931 0.087 86.25 SSDSN 32.41 0.935 0.071 78.03 SSDFS 31.90 0.926 0.096 89.81 proposed 33.81 0.948 0.065 66.39 Ⅳ SSDIP 26.53 0.849 0.124 157.01 SSDSN 31.89 0.925 0.075 82.64 SSDFS 27.21 0.850 0.124 155.91 proposed 33.11 0.939 0.070 71.68 Salinas Ⅱ SSDIP 33.87 0.863 0.054 537.44 SSDSN 35.37 0.894 0.036 67.93 SSDFS 34.38 0.869 0.048 196.51 proposed 36.18 0.901 0.035 67.72 Ⅳ SSDIP 28.78 0.777 0.083 499.51 SSDSN 34.63 0.870 0.042 95.88 SSDFS 29.22 0.787 0.082 511.01 proposed 35.20 0.881 0.036 91.20 3.6 运行时间对比实验
从表 4中的图像去噪运行时间来看,LRMR算法恢复图像最耗时,HySuDeen和本文作者所提出的算法运行时间很接近,两者相差非常小,这证明了本文作者提出的算法不止在客观评价指标和视觉恢复效果上有良好的表现,在运行时间上也具有一定的优势。
表 4 不同方法在4种方案下的平均运行时间对比/sTable 4. Comparison of average running times of different methods under four cases/sdata LRMR LRTV HySuDeep DIP2D proposed Washington DC Mall 74.56 55.69 29.12 59.91 28.82 Salinas 65.39 47.72 26.47 52.65 27.53 4. 结论
为解决深度图像的半拟合问题,改善矩阵分解对立体特征的破坏,本文作者利用特定的深度图像先验网络分别学习矩阵分解得到的更加明显的端元与丰度矩阵上特征信息;同时,构建端元与丰度矩阵上的紧框架平滑正则可以有效改善网络的半拟合现象并加速网络训练; 最后,设计了高效迭代算法来实现神经网络与优化问题相结合模型的高效求解。多组模拟高光谱图像数据实验结果表明,所提出的SSDTS算法可以实现MPSNR性能1 dB以上的提升,ERGAS性能有至少10%的降低,进一步验证了本文中算法在混合噪声去除方面具有优异的表现。
-
![]()
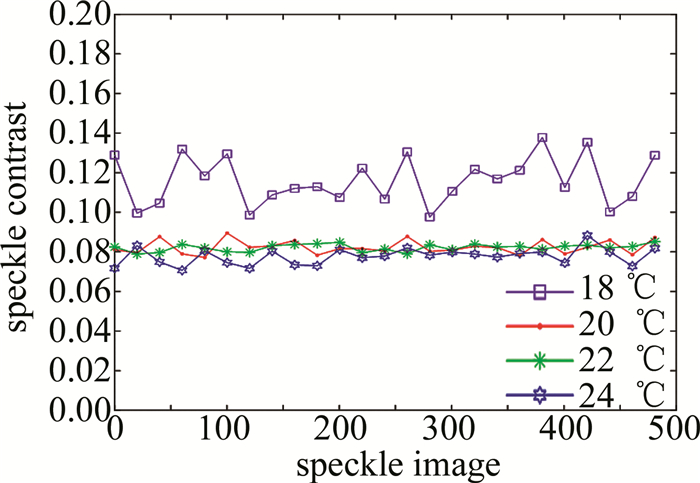
图 2 不同温度影响下的散斑对比度曲线
Figure 2. Speckle contrast curve under different temperature effects
![]()
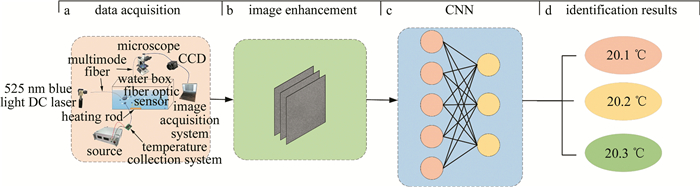
图 3 基于GoogleNet的水下温度信息散斑图像自动识别框架图
Figure 3. Framework diagram of automatic recognition of underwater temperature information speckle images based on GoogleNet
![]()
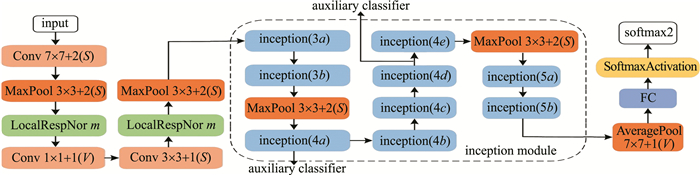
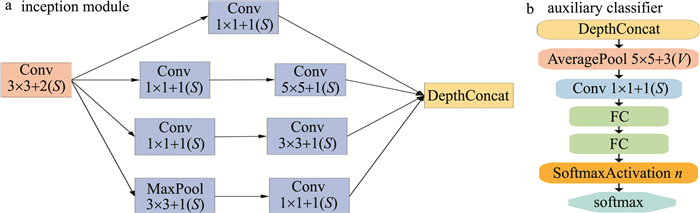
图 5 inception模块和辅助分类器结构图
Figure 5. Structure diagram of the Inception module and auxiliary classifier
表 1 数据集统计
Table 1 Dataset statistics
temperature category/℃ training set(fix) validation set(fix) 20.1 450 50 20.2 450 50 20.3 450 50  下载: 导出CSV
下载: 导出CSV
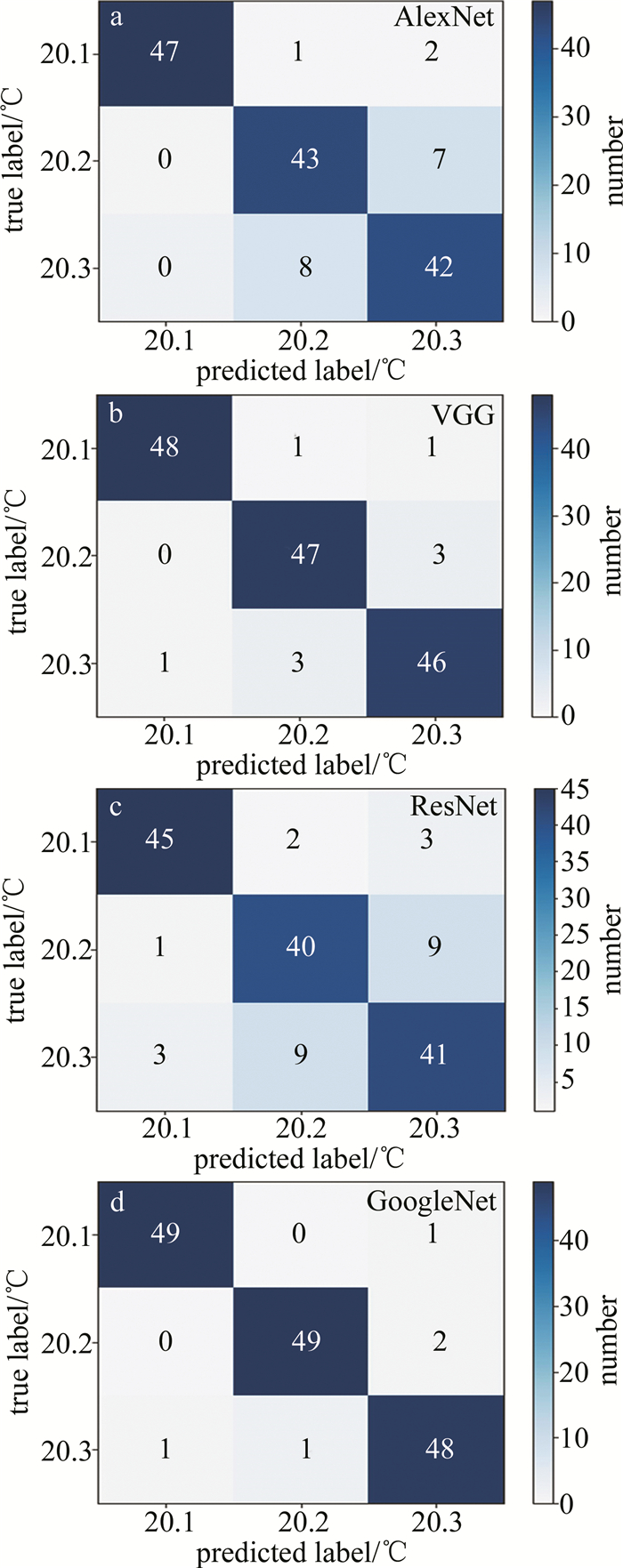
表 2 不同分类模型水下温度数据集上的性能对比
Table 2 Performance comparison of different classification models on underwater temperature datasets
model temperature/℃ precision/% recall/% accuracy/% AlexNet 20.1 100 94 88.0 20.2 82.69 86 20.3 82.35 84 VGG 20.1 97.96 96 94 20.2 92.16 94 20.3 92 92 GoogleNet 20.1 100 98 97.33 20.2 96.08 98 20.3 96 96 ResNet 20.1 97.83 90 84 20.2 78.43 80 20.3 77.36 82
下载: 导出CSV
-
[1] MAHLER S, ELIEZER Y, YLMAZ H, et al. Fast laser speckle suppression with an intracavity diffuser[J]. Nanophotonics, 2020, 10(1): 129-136. DOI: 10.1515/nanoph-2020-0390
[2] GUO Y, DENG J, LI J, et al. Static laser speckle suppression using liquid light guides[J]. Optics Express, 2021, 29(9): 14135-14150. DOI: 10.1364/OE.425587
[3] 黄艳, 陈怀熹. 激光投影显示中复合散斑抑制方法的研究[J]. 激光技术, 2024, 48(2): 274-280. DOI: 10.7510/jgjs.issn.1001-3806.2024.02.020 HUANG Y, CHEN H X. Research on composite speckle suppression methods in laser projection display[J]. Laser Technology, 2024, 48(2): 274-280(in Chinese). DOI: 10.7510/jgjs.issn.1001-3806.2024.02.020
[4] 郜魏柯, 杜小平, 王阳, 等. 激光散斑目标探测技术综述[J]. 中国光学, 2020, 13(6): 1182-1193. https://www.cnki.com.cn/Article/CJFDTOTAL-ZGGA202006002.htm GAO W K, DU X P, WANG Y, et al. Overview of laser speckle target detection technology[J]. China Optics, 2020, 13(6): 1182-1193(in Chinese). https://www.cnki.com.cn/Article/CJFDTOTAL-ZGGA202006002.htm
[5] ROWLEY L J, THAI T Q, JARRETT S R, et al. Correcting for digital image correlation speckle inversion at high temperature using color cameras[J]. Applied Optics, 2022, 61(27): 7948-7957. DOI: 10.1364/AO.463480
[6] 郜魏柯, 杜小平, 王阳, 等. 微粗糙表面参数对激光散斑场的影响规律分析[J]. Acta Optica Sinica, 2021, 41(11): 1103001. https://www.cnki.com.cn/Article/CJFDTOTAL-GXXB202111006.htm GAO W K, DU X P, WANG Y, et al. Analysis of the influence of micro rough surface parameters on laser speckle field[J]. Acta Optica Sinica, 2021, 41(11): 1103001(in Chinese). https://www.cnki.com.cn/Article/CJFDTOTAL-GXXB202111006.htm
[7] ADJABI I, OUAHABI A, BENZAOUI A, et al. Past, present, and future of face recognition: A review[J]. Electronics, 2020, 9(8): 1188-1239. DOI: 10.3390/electronics9081188
[8] KORTLI Y, JRIDI M, AL FALOU A, et al. Face recognition systems: A survey[J]. Sensors, 2020, 20(2): 342-377. DOI: 10.3390/s20020342
[9] GAO Q, TONG Z, MA Y, et al. Flexible and lightweight speckle noise suppression module based on generation of dynamic speckles with multimode fiber and macro fiber composite[J]. Optics and Laser Technology, 2020, 123: 105941. DOI: 10.1016/j.optlastec.2019.105941
[10] 贺锋涛, 曹金凤, 王晓琳, 等. 基于激光散斑的应力传感系统[J]. 红外与激光工程, 2015, 44(12): 3729-3733. DOI: 10.3969/j.issn.1007-2276.2015.12.039 HE F T, CAO J F, WANG X L, et al. Stress sensing system based on laser speckle[J]. Infrared and Laser Engineering, 2015, 44(12): 3729-3733(in Chinese). DOI: 10.3969/j.issn.1007-2276.2015.12.039
[11] VALENT E, SILBERBERG Y. Scatterer recognition via analysis of speckle patterns[J]. Optica, 2018, 5(2): 204-207. DOI: 10.1364/OPTICA.5.000204
[12] 苗希彩. 蓝绿激光海洋湍流及其下行信道传输特性研究[D]. 西安: 西安电子科技大学, 2017: 1-106. MIAO X C. Research on the characteristics of blue green laser ocean turbulence and its downstream channel transmission[D]. Xi'an: Xi'an University of Electronic Science and Technology, 2017: 1-106(in Chinese).
[13] WU Y, ZHANG Y, ZHU Y. Average intensity and directionality of partially coherent model beams propagating in turbulent ocean[J]. Journal of the Optical Society of America, 2016, A33(8): 1451-1458.
[14] BAYKAL Y. Scintillation index in strong oceanic turbulence[J]. Optics Communications, 2016, 375: 15-18. DOI: 10.1016/j.optcom.2016.05.002
[15] 贺锋涛, 李佳琪, 张建磊, 等. 海洋湍流下波长分集无线光通信系统性能分析[J]. 红外与激光工程, 2021, 50(12): 20210131. https://www.cnki.com.cn/Article/CJFDTOTAL-HWYJ202112043.htm HE F T, LI J Q, ZHANG J L, et al. Performance analysis of wavelength diversity wireless optical communication systems under ocean turbulence[J]. Infrared and Laser Engineering, 2021, 50(12): 20210131 (in Chinese). https://www.cnki.com.cn/Article/CJFDTOTAL-HWYJ202112043.htm
[16] YUAN Y, BI Y, SUN M Y, et al. Speckle evaluation in laser display: From speckle contrast to speckle influence degree[J]. Optics Communications, 2020, 454: 124405. DOI: 10.1016/j.optcom.2019.124405
[17] YUAN Y, BI Y, SUN M Y, et al. Quantification of the effects of time-varying speckle patterns on speckle images using a modified speckle influence degree method[J]. Optics Communications, 2020, 463: 125368. DOI: 10.1016/j.optcom.2020.125368
[18] LEE S G, SUNG Y, KIM Y G, et al. Variations of AlexNet and GoogLeNet to improve Korean character recognition performance[J]. Journal of Information Processing Systems, 2018, 14(1): 205-217.
[19] YANG N, ZHANG Z K, YANG J H, et al. A convolutional neural network of googlenet applied in mineral prospectivity prediction based on multi-source geoinformation[J]. Natural Resources Research, 2021, 30(6): 3905-3923. DOI: 10.1007/s11053-021-09934-1
[20] ZHONG Y, HUANG B, TANG C. Classification of cassava leaf disease based on a non-balanced dataset using transformer-embedded ResNet[J]. Agriculture, 2022, 12(9): 1360-1377. DOI: 10.3390/agriculture12091360
[21] LEE K S, JUNG S K, RYU J J, et al. Evaluation of transfer learning with deep convolutional neural networks for screening osteoporosis in dental panoramic radiographs[J]. Journal of Clinical Medicine, 2020, 9(2): 392-404. DOI: 10.3390/jcm9020392
[22] LI Z, LI F, ZHU L, et al. Vegetable recognition and classification based on improved VGG deep learning network model[J]. International Journal of Computational Intelligence Systems, 2020, 13(1): 559-564. DOI: 10.2991/ijcis.d.200425.001
[23] LI B, HE Y. An improved ResNet based on the adjustable shortcut connections[J]. IEEE Access, 2018, 6(99): 18967-18974.







计量
- 文章访问数: 10
- HTML全文浏览量: 0
- PDF下载量: 6