 网站地图
网站地图


-
不同品种的小麦在抗虫病害、质量、产量等方面表现出不同的特性,高品质的小麦种子在小麦产量和质量的提高中起着至关重要的作用,种子混杂时将给育种、种植和商品质量带来巨大的经济损失。随着现代种业中大量种子的不断流通,很可能造成不同品种小麦种子在运输、储存和生产过程中意外混合,必然会降低小麦品质和产量[1]。连续几年的中央一号文件都将种业发展提升到国家粮食战略上,在培育优质小麦种子的同时,对种子纯度进行鉴别成为了科研工作者迫切的任务,因此,种子纯度也成为了《农作物种子检验规程》的必检项目。
近10年来,随着具有快速、无损的高光谱成像技术的发展,越来越多的科研工作者将高光谱成像技术应用到农作物种子研究上,并取得了良好的成果[2-4]。但是, 当前基于高光谱成像技术对小麦种子进行纯度鉴别或分类的许多研究都是假设正负样本数量是一致的[1, 5-6],文中正样本指待检测出的所需品种小麦种子,负样本指混入的其它杂质品种小麦种子。然而当面临实际检测时,由于杂质负样本数量少于正样本数量的情况会导致利用传统算法时分类结果倾向于多数类,而使少数类的分类效果降低[7]。同时,相较于多光谱而言,高光谱图像含有的信息较多,相邻波段间的冗余信息高度相关,还有可能携带无助于判别的噪声信息,因此这也会在一定程度上影响模型纯度检测性能[8-9]。
为了减小样本不均衡造成的纯度检测精度低的影响,本文作者采用合成少数类过采样技术(synthetic minority oversampling technique, SMOTE)对小麦种子的杂质负样本进行扩充,使正负样本数量保持一致,为了消除波段间存在的冗余信息,进一步提高模型的检测精度,再采用非信息变量去除(uninformative variable elimination, UVE)进行波段选择,最后采用支持向量机(support vector machines, SVM)作为分类器。为了更好地比较模型性能,在波段选择算法上对比了连续投影算法(successive projections algorithm, SPA),在分类算法上分别对比了支持向量数据描述(support vector data description, SVDD)和k最近邻(k-nearest neighbor, KNN)算法,结果表明,所提方法在所有比较的方法中效果最好。
-
实验中采用由5个品种的小麦种子(中化现代农业有限公司,中国北京),分别为JM22(济麦22,山东)、JM44(济麦44,山东)、XM26(新麦26,河南)、BN4199(百农4199,河南)和ZM33(周麦33,河南)各1000粒,共5000粒。按照面筋数值划分可分为强筋和中筋,详细信息如表 1所示,杂交时的父本和母本在表中用亲缘关系表示。
表 1 5个品种小麦详细信息
Table 1. Details of 5 varieties of wheat
variety origin place kinship gluten value JM22 Shandong 935024/935106 medium gluten XM26 Henan Xinmai9408/Jinan17 strong gluten JM44 Shandong 954072/Jinan17 strong gluten BN4199 Henan Bainonggaoguang3709F2/BainongAK58 medium gluten ZM33 Henan Zhengmai366/BainongAK58 strong gluten -
实验中使用的高光谱采集系统主要由高光谱相机、载物台及其移动平台、光源组成。高光谱相机采集的光谱范围为400 nm~1000 nm、光谱分辨率为1.29 nm、波段间隔为0.64 nm,空间像素合并值设置为10,采用150 W的光纤卤素灯作为光源,其它参数等详细介绍见参考文献[10]。在进行图像采集时,设置高光谱相机的曝光时间设置为0.25 s,光源功率设置为60 W,图像采集采用线扫描的方式,所采集的高光谱图像合计扫描1000条线,每条线在2维平面上含有1392个像素点,每个像素点采集的是94个不同的光谱波段,因而所采集到的高光谱图像3维大小为[1000, 1392, 94]。由于黑色数粒板能够防止小麦种子移动过程中出现晃动以及对采集的图像进行预处理时易于分割的特点,因而在采集过程中将每个品种的小麦分为10个批次,每个批次100粒小麦种子样本放置在黑色数粒板上,这样5个品种的小麦将会得到50幅小麦种子的高光谱图像,实际上相机捕获的高光谱数据是通过光源照射到样本再反射到相机的反射率获得的,因而光谱数据也可以称为光谱反射率[11]。本文中选取了各品种小麦任一批次下的高光谱图像,并通过ENVI 4.3选择RGB对应的3个波段的数据组成的伪彩色图像,如图 1所示。从图像也可以看出,不同品种小麦的形状、外观等特征较为接近,几乎无法通过肉眼识别。

图 1 5个品种小麦的伪RGB图像
Figure 1. Pseudo RGB images of five wheat varieties
-
实验中采集的高光谱图像中除小麦种子样品有效的高光谱信息外,还有背景板信息以及电荷耦合器件(chang-coupled device, CCD)中含有的电流暗噪声等多种信息,尤其电流暗噪声信息会对结果分析产生较大影响,因而首先要对采集到的图像进行校正,校正公式如下:
$ I=\frac{I_{\text {raw }}-I_{\text {black }}}{I_{\text {white }}-I_{\text {black }}} $
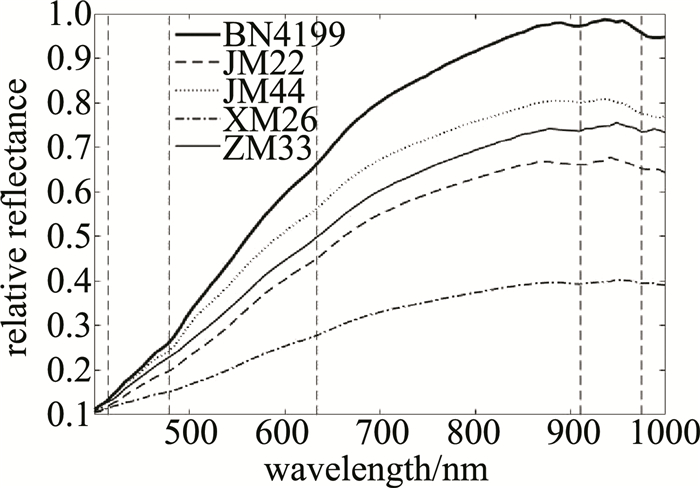
(1) 式中:Iraw、Iwhite、Iblack和I分别为通过相机采集到的原始高光谱图像、标准白板下的高光谱图像、标准黑板下的高光谱图像和校正后的图像。完成黑白板校正后,需要进一步提取小麦种子所在区域内(也称为感兴趣区域)的有效信息,该有效信息是利用阈值分割算法(阈值分割-腐蚀膨胀-计算均值光谱信息)进行提取的。完成上述步骤后,即可得到小麦种子的均值光谱信息,将每粒小麦种子的均值光谱作为模型的输入特征,各品种小麦种子中的平均光谱曲线(反射率)如图 2所示。图中垂直虚线所在位置为各品种小麦的吸收峰在波段的分布。表 2中给出了吸收峰所处的波段范围以及影响吸收峰的因素。结合图 2和表 2可知,品种为BN4199的小麦种子反射率较高,品种为XM26的小麦种子反射率较低,与其它品种小麦的光谱曲线差异较为明显,其余3类品种小麦种子的光谱曲线较为接近,这些差异主要是由于小麦种子中蛋白质、淀粉和水的成分含量不同造成的。

图 2 5个品种小麦的反射率
Figure 2. Reflectance of five wheat varieties
-
由于过采样技术只是对样本进行简单机械地复制,并不能引入新的有效信息,因而往往不会提升模型的分类效果,还可能造成过拟合的风险[15]。为了提升模型的分类效果并降低过采样技术中过拟合的风险,本文作者提出了将SMOTE应用到不均衡样本的小麦种子纯度检测中,使正负样本的数量一致。SMOTE合成样本的策略是对负样本所在类中的每一个样本m,从其邻近的若干样本中随机选择P个样本mi(i=1, 2, …, P),然后从m和每一个mi之间合成一个新的样本mnew,样本合成公式如下所示:
$ \begin{gather*} m_{\text {new }}=m+\operatorname{rand}(0, 1) \times\left(m_{i}-m\right), \\ (i=1, 2, \cdots, P) \end{gather*} $
(2) 式中:rand(0, 1)表示0~1范围内的随机数。
-
与多光谱图像相比,高光谱图像数据的波段数目较多,相邻波段信息高度相关,因而可能携带无助于判别的冗余信息[16-17]。为了消除波段间的冗余信息,并尽可能地提高模型的分类精度,本文中在对杂质负样本进行扩充后,对光谱波段进行选择。UVE的基本思想是通过建立偏最小二乘(partial least squares, PLS)模型去除与信息判别无关的波长,选出特征波长,被去除的波长也称为无信息变量[18],假设原始样本矩阵为样本矩阵,记为XM×N,样本标签记为yM×1,其中M为样本个数,N为波段数目,算法步骤见下。
(a) 以最低均方根误差预测(root-mean-square error of prediction,RMSEP)RRMSEP为准则[18]确定最优模型复杂度,如下式所示:
$ \begin{equation*} R_{\mathrm{RMSEP}}=\sqrt{\frac{\sum\limits_{i=1}^{M}\left(\hat{y}_{i}-y_{i}\right)^{2}}{M}} \end{equation*} $
(3) 式中:yi为样本标签; $ \hat{y}_{i}$为预测值; i=1, 2, 3, …, M。
(b) 生成M×N维噪声矩阵RM×N,将原始矩阵与噪声矩阵组成新的矩阵,记为SM×2N,SM×2N=[XM×N, RM×N]。
(c) 根据留一交叉验证确定回归系数矩阵AM×2N,将AM×2N中的元素记为aij,其中i=1, 2, 3, …, M; j=1, 2, 3, …, 2N。
(d) 确定各列向量平均值 aj、标准差s(aj)以及回归系数平均值与标准差的比值,记为cj,j=1, 2, 3, …, 2N。
$ \left\{\begin{array}{l} s\left(\bar{a}_{j}\right)=\sqrt{\frac{\sum\limits_{i=1}^{M}\left(a_{i j}-\bar{a}_{j}\right)^{2}}{M-1}} \\ c_{j}=\frac{\bar{a}_{j}}{s\left(\bar{a}_{j}\right)} \\ \bar{a}_{j}=\frac{\sum\limits_{i=1}^{M} a_{i j}}{M} \end{array}\right. $
(4) (e) 在XM×N中消除abs(cj)小于某一阈值的实验变量,j=1, 2, 3, …, 2N,得到新的矩阵Xnew,建立最终留一交叉验证模型,并对样本矩阵进行预测,得到新的RRMSEP,记为RRMSEPN。
(f) 分析RRMSEPN,若RRMSEPN>RRMSEP, 则重设噪声参数,进入步骤(b)循环,否则输出光谱特征变量。
-
本文中采用SVM作为分类器。线性SVM的基本原理为:寻求建立一个几何间隔最大的超球面, 使正样本数据尽可能地分布在该超球面内,而负样本数据分布在超球面外。然而, 当面临例如小麦种子纯度检测这类低维线性不可分的问题时,则无法通过线性SVM进行求解。CORTES等人[19]将核函数引入SVM中,通过非线性变换将该低维数据转变为高维数据,从而实现其线性可分。因而自其提出以来, 在许多领域受到了较为广泛的应用, 并取得了良好效果[20-22]。根据SVM的原理,构建的超平面应为:
$ {\boldsymbol{w}} \cdot {\boldsymbol{x}}+b=0 $
(5) 式中: w表示平面的法向量; b表示偏移量。为了使训练数据集{x|xi ∈ RN, i=1, 2, …, M}(其中xi是1×N维的向量,RN是实数集)和yi∈{+1, -1}能够正确分类,则应满足:
$ f(\boldsymbol{x})=\operatorname{sign}\left[\boldsymbol{w}^{\mathrm{T}} \varOmega(\boldsymbol{x})+b\right] $
(6) 式中: sign(·)是符号函数; Ω(x)为非线性映射。则最终构建的SVM优化函数及其约束条件为:
$ \begin{gather*} \min J\left(\boldsymbol{w}, e_{i}\right)=\min \left(\frac{1}{2}\|\boldsymbol{w}\|^{2}+\frac{1}{2} \gamma \sum\limits_{i}^{M} e_{i}^{2}\right), \\ \left(y_{i}\left[\boldsymbol{w}^{\mathrm{T}} \varphi\left(\boldsymbol{x}_{i}\right)+b\right]=1-e_{i}\right) \end{gather*} $
(7) 式中:J(w, ei)表示目标函数; ‖w‖表示w的F范数; φ(xi)表示非线性函数; ei为误差变量,i=1, 2, …, M;γ为惩罚因子, 其求解过程转化为朗格朗日的对偶问题,最终求得:
$ f(\boldsymbol{x})=\operatorname{sign}\left[\sum\limits_{i=1}^{M} \alpha_{i} y_{i} Q\left(\boldsymbol{x}, \boldsymbol{x}_{i}\right)+b\right] $
(8) 式中:αi是拉格朗日系数;Q(x, xi)为核函数,通常采用径向基核函数,其公式如下:
$ Q\left(\boldsymbol{x}, \boldsymbol{x}_{i}\right)=\exp \left(-\frac{\left\|\boldsymbol{x}-\boldsymbol{x}_{i}\right\|^{2}}{2 \sigma^{2}}\right) $
(9) 式中:σ2为方差。
-
本文中采用准确率、精确率以及负样本的检出率t作为分类模型的评价指标,将样品分为5类:真正(true positive,TP)tTP,假正(false positive,FP)tFP,假负(false negative,FN)tFN,真负(true negative)tTN和负(negative,NEG)tNEG, 则准确率、精确率和负样本检出率的计算公式如下所示。
准确率为:
$ A=\frac{t_{\mathrm{TP}}+t_{\mathrm{TN}}}{t_{\mathrm{TP}}+t_{\mathrm{FP}}+t_{\mathrm{FN}}+t_{\mathrm{TN}}} \times 100 \% $
(10) 精确率为:
$ P=\frac{t_{\mathrm{TP}}}{t_{\mathrm{TP}}+t_{\mathrm{FP}}} \times 100 \% $
(11) 负样本检出率(negative detection,ND)tND为:
$ t_{\mathrm{ND}}=\frac{t_{\mathrm{TN}}}{t_{\mathrm{NEG}}} \times 100 \% $
(12) -
实验中将上述5个品种的小麦种子分为5组。第1组(JM22):正样本为JM22,负样本为XM26、JM44、BN4199和ZM33;第2组(XM26):正样本为XM26,负样本为JM22、JM44、BN4199和ZM33;第3组(JM44):正样本为JM44,负样本为JM22、XM26、BN4199和ZM33;第4组(BN4199):正样本为BN4199,负样本为JM22、XM26、JM44和ZM33;第5组(ZM33):正样本为ZM33,负样本为JM22、XM26、JM44和BN4199。
为了更好地比较不均衡样本分类模型的性能,本文中采用SVDD、KNN和SVM进行对比实验。SVDD原理参见参考文献[23],为了使建立的超球体容错能力更强,在训练的过程中,允许模型训练过程中添加少量的负样本从而使超球体更加收敛[23]。因此SVDD在许多不均衡样本与异常识别等问题具有广泛的应用[24-25]。实际上根据KNN原理(参见参考文献[26]),KNN既能够应用于在不均衡样本分类中[27-28],也可以应用于均衡样本分类[26]。因而在实验过程中将SVDD用于不均衡样本识别,KNN分别用于不均衡样本、通过SMOTE扩充后的样本以及波段选择后的样本分类识别。
实验过程中从正样本所在类随机抽取800粒、负样本每类抽取20粒共80粒分别训练SVDD模型、KNN模型和SVM模型,SVDD和SVM均采用10折交叉验证和网格寻优,KNN采用10折交叉验证和自动超参数寻优,每组随机训练10次,取其平均准确率、精确率以及负样本检出率。再从剩下的样本中,抽取200粒正样本,随机抽取负样本每类25粒共100粒作为测试集。用第2.4节中的评价指标评估各模型下测试集的结果,如表 3所示。表中最后一行为5类小麦纯度检测结果的平均值。
表 3 不均衡样本下小麦种子纯度检测结果
Table 3. Results of wheat seed purity under unbalanced samples
positive samples SVDD KNN SVM A/% P/% tND/% A/% P/% tND/% A/% P/% tND/% JM22 64.00 79.11 67.00 84.03 81.35 52.40 93.07 90.68 79.20 XM26 64.33 83.45 77.00 79.20 76.74 37.70 89.80 87.01 70.20 JM44 56.33 74.13 63.00 81.40 78.83 45.10 92.23 89.65 76.90 BN4199 62.33 87.18 85.00 82.70 80.01 49.80 95.50 84.09 87.50 ZM33 60.00 76.32 64.00 82.33 80.13 51.60 89.87 87.38 70.70 average 61.40 80.04 71.20 81.93 79.41 47.32 92.09 87.76 76.90 由表 3可知,SVDD的准确率、精确率以及负样本的检出率都较低,表明SVDD在本文中研究的不均衡样本下的小麦种子纯度检测并不适用。KNN和SVM的平均准确率和精确率都在79.00%以上,而负样本的平均检出率分别只有47.32%和76.90%,这表明利用传统算法处理不均衡样本的分类问题时会使结果倾向于多数样本类,使少数样本类的分类效果降低,负样本检出率较低,表明模型将许多负样本识别为正样本,这在小麦种子纯度检测当中的影响将是巨大的。为此,在选择上述数据集的基础上,用SMOTE算法生成一些新的负样本,使训练集中正负样本的数量均为800,分别用KNN和SVM进行评估,结果如表 4所示。
表 4 SMOTE负样本扩充后小麦种子纯度检测结果
Table 4. Results of SMOTE seed purity after SMOTE sample extension
positive samples SMOTE-KNN SMOTE-SVM A/% P/% tND/% A/% P/% tND/% JM22 88.87 89.26 77.20 94.80 93.17 85.30 XM26 82.63 85.28 69.10 94.80 93.78 86.70 JM44 94.33 92.56 84.00 94.40 92.57 83.69 BN4199 88.57 89.74 78.60 96.53 95.49 90.60 ZM33 84.67 86.86 72.60 95.47 94.60 88.60 average 87.81 88.74 76.30 95.20 93.92 86.98 由表 4可知,在用SMOTE算法对不平衡样本数据集进行扩充以后,分类效果均有了显著提升,KNN模型下平均准确率从81.93%提升到了87.81%,精确率由79.41%提升到了88.74%,负样本检出率从47.32%提升到了76.30%;SVM模型下的平均准确率从92.09%提升到了95.20%,精确率由87.76%提升到了93.92%,负样本检出率从76.90%提升到了86.98%。模型在SMOTE对不平衡数据集进行扩充后负样本检测率有较大提升,这表明混有杂质品种小麦的样本被正确识别的可能性越来越大,通过SMOTE对本研究的数据集进行扩充提升分类效果是可行的。
为了尽可能地消除波段间的冗余信息,进一步提升模型的分类效果,在用SMOTE算法对数据进行扩充以后,采用UVE对波段进行选择,同时对比了SPA算法。SPA的原理参见参考文献[29]。表 5中统计了各个模型下的平均检测结果。表中最后一列是各品种小麦在SPA和UVE下的平均最佳波段数目。
表 5 5个品种小麦种子分别在4种模型中的平均检测结果
Table 5. Average results of 5 wheat varieties in 4 models
model A/% P/% tND/% number SMOTE-UVE-KNN 91.12 90.09 78.50 71.00 SMOTE-SPA-KNN 90.50 89.62 77.61 74.00 SMOTE-UVE-SVM 95.98 94.94 89.32 71.00 SMOTE-SPA-SVM 95.30 94.12 87.52 74.00 由表 5可知,在保证各项评价指标不降低的前提下,用SPA和UVE选择了各品种小麦的最优波段后,SVM模型和KNN模型的分类效果均有所提升,且UVE的波段选择效果优于SPA,表明了SMOTE-UVE-SVM方法在所有比较的方法中效果最佳。表 6中给出了各品种小麦在SMOTE-UVE-SVM模型下的检测结果。由表 6可知,各品种小麦的纯度检测结果相较于SVM在全波段范围内不均衡样本的小麦种子纯度检测有较大提升,且能够保证准确率、精确率均在93.00%以上的前提下,负样本的检出率均不低于85.00%。
表 6 5个品种小麦种子在SMOTE-UVE-SVM模型的检测结果
Table 6. Test results of 5 varieties of wheat seeds in SMOTE-UVE-SVM model
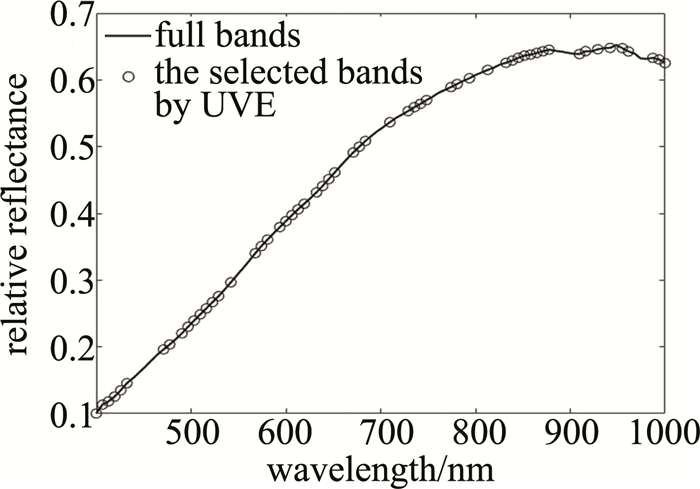
positive samples SMOTE-UVE-SVM A/% P/% tND/% number JM22 96.13 94.92 89.30 75.00 XM26 95.30 94.49 88.30 68.00 JM44 95.07 93.22 85.40 81.00 BN4199 97.23 96.46 92.70 72.00 ZM33 96.17 95.60 90.90 57.00 average 95.98 94.94 89.32 71.00 图 3中给出了UVE所选最优波段在全波段的分布。而由图 4可知,UVE所选波段除分布在除表 2所分析的吸收峰附近外,其余分布较为均匀。分析结果可知,UVE选择的波段可助于消除波段间携带的冗余信息,提升分类效果。同时本文作者选择了实验过程中以BN4199为正样本,其余品种小麦为负样本的预测结果,其准确率、精确率与负样本检出率分别为97.33%、96.60%与93.00%。图 4a和图 4b中分别给出了测试样本的标签与测试结果。
图 3 UVE选取的波段在全波段分布
Figure 3. Distribution of selected bands in the full bands by UVE
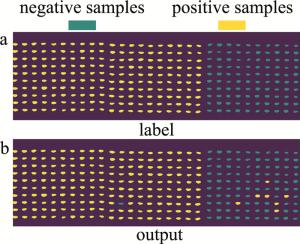
图 4 测试样本真实标签与预测值
Figure 4. True label and test values of the test samples
-
本文中研究了小麦种子杂质负样本不足导致纯度检测过程中模型性能偏低的问题。在运用高光谱成像技术的基础上,提出了一种基于SMOTE-UVE-SVM方法的纯度检测模型,该方法首先利用SMOTE算法对小麦种子中杂质负样本数据集扩充,使其与正样本数据的数量保持一致,再利用UVE进行波段选择,消除相同高光谱波段间可能存在的信息冗余和噪声,进一步提高小麦种子纯度检测的精度,最后用SVM进行分类。为了更好地比较模型的性能,实验过程中在均衡与不均衡样本的分类算法上分别对比了SVDD、KNN和SVM,在波段选择算法上分别对比了SPA和UVE。研究结果表明,SMOTE-UVE-SVM模型在所有比较的方法中效果最佳。由于当前仅研究了负样本中含有的4类小麦种子,在以后条件许可的情况下,应尽可能地增加负样本的类别,使模型更加具有通用性,以及能够识别出待测样本中出现未参与模型训练品种的小麦种子。
基于SMOTE-UVE-SVM的小麦种子纯度高光谱图像检测
Hyperspectral image detection of wheat seed purity based on SMOTE-UVE-SVM
-
摘要: 为了解决基于高光谱成像技术的小麦种子纯度检测过程中样本不均衡及波段信息冗余导致纯度检测模型性能下降的问题, 提出了一种融合合成少数类过采样技术(SMOTE)、非信息变量剔除(UVE)和支持向量机(SVM)的种子纯度高光谱检测模型。该模型利用SMOTE算法对小麦种子少数类(杂质)样本进行扩充, 改善样本的不均衡性; 同时利用UVE对高维的高光谱特征进行选择, 并构建SVM模型作为分类器, 以进一步提高分类的性能。结果表明, 5类小麦种子的平均准确率、精确率和负样本检出率分别达到95.98%、94.94%和89.32%, 较传统方法分别提高了3.89%、7.18%和12.42%。所提出的方法在基于高光谱成像技术的小麦种子纯度检测中具有较好的应用前景。
-
关键词:
- 光谱学 /
- 高光谱成像技术 /
- 合成少数类过采样技术 /
- 非信息变量剔除 /
- 种子纯度
Abstract: In order to solve the problem, the performance of the wheat seed purity detection model decreased due to sample imbalance and band information redundancy in the process of hyperspectral imaging. A seed purity hyperspectral detection model was proposed by combining the synthetic minority oversampling technique (SMOTE) with uninformative variables elimination (UVE) and support vector machine (SVM). In this model, the SMOTE was used to expand the minority class (impurity) samples of the wheat seeds to improve the sample imbalance. At the same time, the UVE was used to select the high-dimensional hyperspectral features, and the SVM model was constructed to further reduce the risk of model overfitting caused by feature redundancy. Results showed that: The average accuracy, precision, and negative sample detection rate of the five types of wheat seeds are 95.98%, 94.94%, and 89.32%, respectively, which are 3.89%, 7.18%, and 12.42% higher than the traditional methods, respectively. The proposed method has a good application prospect in the detection of wheat seed purity based on hyperspectral imaging technology. -
表 1 5个品种小麦详细信息
Table 1. Details of 5 varieties of wheat
variety origin place kinship gluten value JM22 Shandong 935024/935106 medium gluten XM26 Henan Xinmai9408/Jinan17 strong gluten JM44 Shandong 954072/Jinan17 strong gluten BN4199 Henan Bainonggaoguang3709F2/BainongAK58 medium gluten ZM33 Henan Zhengmai366/BainongAK58 strong gluten  下载: 导出CSV
下载: 导出CSV
表 2 吸收峰在小麦种子的分布范围及影响因素
Table 2. Distribution range and influencing factors of absorption peak in wheat seeds
下载: 导出CSV
表 3 不均衡样本下小麦种子纯度检测结果
Table 3. Results of wheat seed purity under unbalanced samples
positive samples SVDD KNN SVM A/% P/% tND/% A/% P/% tND/% A/% P/% tND/% JM22 64.00 79.11 67.00 84.03 81.35 52.40 93.07 90.68 79.20 XM26 64.33 83.45 77.00 79.20 76.74 37.70 89.80 87.01 70.20 JM44 56.33 74.13 63.00 81.40 78.83 45.10 92.23 89.65 76.90 BN4199 62.33 87.18 85.00 82.70 80.01 49.80 95.50 84.09 87.50 ZM33 60.00 76.32 64.00 82.33 80.13 51.60 89.87 87.38 70.70 average 61.40 80.04 71.20 81.93 79.41 47.32 92.09 87.76 76.90
下载: 导出CSV
表 4 SMOTE负样本扩充后小麦种子纯度检测结果
Table 4. Results of SMOTE seed purity after SMOTE sample extension
positive samples SMOTE-KNN SMOTE-SVM A/% P/% tND/% A/% P/% tND/% JM22 88.87 89.26 77.20 94.80 93.17 85.30 XM26 82.63 85.28 69.10 94.80 93.78 86.70 JM44 94.33 92.56 84.00 94.40 92.57 83.69 BN4199 88.57 89.74 78.60 96.53 95.49 90.60 ZM33 84.67 86.86 72.60 95.47 94.60 88.60 average 87.81 88.74 76.30 95.20 93.92 86.98
下载: 导出CSV
表 5 5个品种小麦种子分别在4种模型中的平均检测结果
Table 5. Average results of 5 wheat varieties in 4 models
model A/% P/% tND/% number SMOTE-UVE-KNN 91.12 90.09 78.50 71.00 SMOTE-SPA-KNN 90.50 89.62 77.61 74.00 SMOTE-UVE-SVM 95.98 94.94 89.32 71.00 SMOTE-SPA-SVM 95.30 94.12 87.52 74.00
下载: 导出CSV
表 6 5个品种小麦种子在SMOTE-UVE-SVM模型的检测结果
Table 6. Test results of 5 varieties of wheat seeds in SMOTE-UVE-SVM model
positive samples SMOTE-UVE-SVM A/% P/% tND/% number JM22 96.13 94.92 89.30 75.00 XM26 95.30 94.49 88.30 68.00 JM44 95.07 93.22 85.40 81.00 BN4199 97.23 96.46 92.70 72.00 ZM33 96.17 95.60 90.90 57.00 average 95.98 94.94 89.32 71.00
下载: 导出CSV
-
[1] BAO Y, MI C, WU N, et al. Rapid classification of wheat grain varieties using hyperspectral imaging and chemometrics[J]. Applied Sciences, 2019, 9(19): 4119. doi: 10.3390/app9194119 [2] FENG L, ZHU S, LIU F, et al. Hyperspectral imaging for seed quality and safety inspection: A review[J]. Plant Methods, 2019, 15(1): 1-25. doi: 10.1186/s13007-018-0385-5 [3] QIU Z, CHEN J, ZHAO Y, et al. Variety identification of single rice seed using hyperspectral imaging combined with convolutional neural network[J]. Applied Sciences, 2018, 8(2): 212. doi: 10.3390/app8020212 [4] YANG X, HONG H, YOU Z, et al. Spectral and image integrated analysis of hyperspectral data for waxy corn seed variety classification[J]. Sensors, 2015, 15(7): 15578-15594. doi: 10.3390/s150715578 [5] 黄敏, 夏超, 朱启兵, 等. 融合高光谱图像技术与MS-3DCNN的小麦种子品种识别模型[J]. 农业工程学报, 2021, 37(18): 153-160. doi: 10.11975/j.issn.1002-6819.2021.18.018 HUANG M, XIA Ch, ZHU Q B, et al. Recognizing wheat seed varieties using hyperspectral imaging technology combined with multi-scale 3D convolution neural network[J]. Transactions of the Chinese Society of Agricultural Engineering, 2021, 37(18): 153-160(in Chin-ese). doi: 10.11975/j.issn.1002-6819.2021.18.018 [6] SINGH P, NAYYAR A, SINGH S, et al. Classification of wheat seeds using image processing and fuzzy clustered random forest[J]. International Journal of Agricultural Resources, Governance and Eco-logy, 2020, 16(2): 123-156. doi: 10.1504/IJARGE.2020.109048 [7] 王和勇, 樊泓坤, 姚正安, 等. 不平衡数据集的分类方法研究[J]. 计算机应用研究, 2008, 25(5): 1301-1304. WANG H Y, FAN H K, YAO Zh A, et al. Research of imbalanced data classification[J]. Application Research of Computers, 2008, 25(5): 1301-1304(in Chinese). [8] 闫红梅, 何明一. 基于聚类和联合偏度与峰度指数的高光谱数据波段选择算法[J]. 信号处理, 2023, 39(1): 1-10. YAN H M, HE M Y. Hyperspectral data band selection based on clustering joint skewness-kurtosis index[J]. Journal of Signal Processing, 2023, 39(1): 1-10(in Chinese). [9] 路燕, 任月, 崔宾阁. 噪声鲁棒的高光谱图像波段选择方法[J]. 遥感学报, 2022, 26(11): 2382-2398. LU Y, REN Y, CUI B G. Noise robust band selection method for hyperspectral images[J]. National Remote Sensing Bulletin, 2022, 26(11): 2382-2398(in Chinese). [10] YANG S, ZHU Q B, HUANG M. Application of joint skewness algorithm to select optimal wavelengths of hyperspectral image for maize seed classification[J]. Spectroscopy and Spectral Analysis, 2017, 37(3): 990-996. [11] 刘璐, 邵慧, 孙龙, 等. 利用高光谱激光雷达检测木材的霉变与含水量[J]. 激光技术, 2023, 47(5): 620-626. LIU L, SHAO H, SUN L, et al. Detection of mildew and moisture content in timber by hyperspectral LiDAR[J]. Laser Technology, 2023, 47(5): 620-626(in Chinese). [12] HUANG M, HE C, ZHU Q, et al. Maize seed variety classification using the integration of spectral and image features combined with feature transformation based on hyperspectral imaging[J]. Applied Sciences, 2016, 6(6): 183. doi: 10.3390/app6060183 [13] BRUNING B, LIU H, BRIEN C, et al. The development of hyperspectral distribution maps to predict the content and distribution of nitrogen and water in wheat (Triticum aestivum)[J]. Frontiers in Plant Science, 2019, 10: 1380. doi: 10.3389/fpls.2019.01380 [14] SINGH C B, JAYAS D S, PALIWAL J, et al. Identification of insect-damaged wheat kernels using short-wave near-infrared hyperspectral and digital colour imaging[J]. Computers and Electronics in Agriculture, 2010, 73(2): 118-125. doi: 10.1016/j.compag.2010.06.001 [15] 童莹萍, 冯伟, 宋怡佳, 等. 面向不平衡高光谱遥感分类的SMOTE和旋转森林动态集成算法[J]. 遥感学报, 2022, 26(11): 2369-2381. TONG Y P, FENG W, SONG Y J, et al. Dynamic ensemble algorithm of SMOTE and rotation forest for imbalanced hyperspectral remote sensing classification[J]. National Remote Sensing Bulletin, 2022, 26(11): 2369-2381 (in Chinese). [16] DOU Z, GAO K, ZHANG X, et al. Band selection of hyperspectral images using attention-based autoencoders[J]. IEEE Geoscience and Remote Sensing Letters, 2020, 18(1): 147-151. [17] BAJCSY P, GROVES P. Methodology for hyperspectral band selection[J]. Photogrammetric Engineering & Remote Sensing, 2004, 70(7): 793-802. [18] CENTNER V, MASSART D L, DE NOORD O E, et al. Elimination of uninformative variables for multivariate calibration[J]. Analytical Chemistry, 1996, 68(21): 3851-3858. doi: 10.1021/ac960321m [19] CORTES C, VAPNIK V. Support vector machine[J]. Machine Learning, 1995, 20(3): 273-297. [20] 张政, 李世强. 基于AdaBoost改进随机森林和SVM的极化SAR地物分类[J]. 中国科学院大学学报, 2022, 39(6): 776-782. ZHANG Zh, LI Sh Q. Polarimetric SAR image classification based on AdaBoost improved random forest and SVM[J]. Journal of University of Chinese Academy of Sciences, 2022, 39(6): 776-782 (in Chinese). [21] 黄江, 李雨涵, 吴盛斌, 等. 基于多元特征参数与改进SVM算法的驾驶风格识别研究[J]. 重庆理工大学学报(自然科学版), 2022, 36(11): 8-19. HUANG J, LI Y H, WU Sh B, et al. Research on driving style re-cognition based on multivariate feature parameters and an improved SVM algorithm[J]. Journal of Chongqing University of Technology(Natural Science Edition), 2022, 36(11): 8-19 (in Chinese). [22] 杨丽, 高美婷. 基于LS-SVM测量生物组织光学参量的实验研究[J]. 激光技术, 2015, 39(3): 300-303. YANG L, GAO M T. Experimental study about measurement of optical parameters of biological tissue based on least square support vector machine[J]. Laser Technology, 2015, 39(3): 300-303(in Chinese). [23] TAX D M J, DUIN R P W. Support vector data description[J]. Machine Learning, 2004, 54(1): 45-66. doi: 10.1023/B:MACH.0000008084.60811.49 [24] 康颖, 赵治华, 吴灏, 等. 基于Deep SVDD的通信信号异常检测方法[J]. 系统工程与电子技术, 2022, 44(7): 2319-2328. KANG Y, ZHAO Zh H, WU H, et al. Deep SVDD-based anomaly detection method for communication signals[J]. Systems Engineering and Electronics, 2022, 44(7): 2319-2328 (in Chinese). [25] ZHAO Y, ZHANG X, SHANG Z, et al. A novel hybrid method for KPI anomaly detection based on VAE and SVDD[J]. Symmetry, 2021, 13(11): 2104. doi: 10.3390/sym13112104 [26] 蒋卫恒, 段耀星, 李明玉, 等. 一种基于维度加权盲K近邻算法的数字预失真技术[J]. 电子与信息学报, 2023, 45(2): 446-454. JIANG W H, DUAN Y X, LI M Y, et al. A digital predistortion technique based on the dimension weighted blind K-nearest neighbor algorithm[J]. Journal of Electronics & Information Technology, 2023, 45(2): 446-454 (in Chinese). [27] SYALIMAN K U. Enhance the accuracy of K-nearest neighbor (KNN) for unbalanced class data using synthetic minority oversampling technique (smote) and gain ratio (GR)[J]. INFOKUM, 2021, 10(1): 188-195. [28] 杜娟, 刘志刚, 衣治安. 一种适用于不均衡数据集分类的KNN算法[J]. 科学技术与工程, 2011, 11(12): 2680-2685. DU J, LIU Zh G, YI Zh A. A KNN algorithm for unbalanced data set[J]. Science Technology and Engineering, 2011, 11(12): 2680-2685 (in Chinese). [29] 张楠楠, 张晓, 王城坤, 等. 基于高光谱和连续投影算法的棉花叶面积指数估测[J]. 农业机械学报, 2022, 53(S1): 257-262. ZHANG N N, ZHANG X, WANG Ch K, et al. Cotton LAI estimation based on hyperspectral and successive projection algorithm[J]. Transactions of the Chinese Society for Agricultural Machinery, 2022, 53(S1): 257-262 (in Chinese). -
 点击查看大图
点击查看大图

计量
- 文章访问数: 1297
- HTML全文浏览量: 884
- PDF下载量: 9
- 被引次数: 0
