 Map
Map

HTML
-
快速、无损且精准的花生品质检测在农业工程的发展中具有战略价值。作为一种营养和经济价值都非常高的植物,花生品种的品质在培育、种植、生产加工和销售等方面都有极其重要的作用。优良的花生品种具有更好的价值和市场竞争力,可以增强我国食用油的供应能力,保障我国粮食产量与质量安全[1]。所以,开发出高精度、稳定的花生分类鉴别模型是迫切且有重大意义的。
目前,高光谱成像(hyperspectral imaging,HSI)技术作为一项前沿的快速、无损且高效的检测方法,在地质检测[2]、食品安全检测[3]、农产品品种鉴别[4-6]、木材[7]及水果[8]等领域得到广泛应用。高光谱图像涵盖了特定波长的像素点分布信息和每个像素的光谱信息[9]。当物质分子发生振动或能级跃迁时,会产生具有独特光谱吸收峰的现象,但不同分子在物质中的组成和含量有差异,它们的光谱吸收峰在位置和强度上也存在区别。通过采集物体的高光谱图像,可以获取其光谱特征,进而实现对不同品种或物质的分类和识别。越来越多的机器学习算法与HSI结合使用,以对样本进行分类、回归等。2017年,LIANG等人[10]利用主成分分析法(principal components analysis,PCA)对小麦光谱数据降维,通过使用支持向量机(support vector machine,SVM)构建了基于敏感波段筛选的判别模型,区分了白粉病和条锈病,结果显示,该模型在病害区分上的精度达到92%,但该模型只识别了两种病害,且精度偏低。2022年,XUE等人[11]使用PCA降维,结合8种机器学习算法对5种玉米种子的近红外光谱数据建模识别,分类准确率在80.8%~98.4%之间,结果证明了不同判别算法建模效果有差异,可以对其进行优化和改进。2023年,ZHU等人[12]提出了一种融合合成少数类过采样技术(synthetic minority oversampling technique, SMOTE)、非信息变量消除法(uninformative variables elimination,UVE)和SVM的种子纯度高光谱检测模型,结果表明,5类小麦种子的平均准确率、精确率和负样本检出率分别达到95.98%、94.94%和89.32%,该模型减小了样本不均衡及波段信息冗余问题造成的纯度检测精度低的影响,但使用传统判别方法SVM建模,检测准确率偏低。光谱数据与待测成分通常呈现非线性关系,传统的线性建模方法难以充分反映二者之间的关联。
为了提高可见-近红外波段的花生高光谱图像分类的精度和减少分类检测时间,利用图像背景分割和Savitzky-Golag(SG)卷积平滑对原始光谱数据进行预处理,采用连续投影算法(successive projections algorithm,SPA)获取特征波长,同时使用粒子群优化(particle swarm optimization, PSO)算法寻找反向传播神经网络(back propagation neural network,BPNN)初始权值和阈值的最优解,基于反向传播(back propagation, BP)的最优建模参数结合SPA构建分类模型。选择BPNN、随机森林(random forest,RF)、径向基函数(radial basis function,RBF)及SVM共4种机器学习分类判别算法与本文中提出的SPA-PSO-BP算法作对比实验。结果表明,SPA-PSO-BP方法是5种方法中分类检测效果最好的。
-
SPA是一种基于连续投影原理的特征波长选择方法,通过将每个波长投影在其它波段上计算出投影向量的值,选择具有最低冗余信息和最小共线性的特征波长[13-14],从而减少运算时间,并提高模型分类精度。
设光谱矩阵为Xmn,其中m为样本数,n为列向量波长数。任选Xmn的一列向量xj记为xk(n)。算法实现步骤如下。
(a) 确定N为选择的波长数,N={j, j∈{k(0), …, k(n-1)}};
(b) 确定S为未被选的波长数,S={j, j∉{k(0), …, k(n-1)}};
(c) 根据下式计算xj对S的向量投影Pxj;
(d) 根据下式筛选出最大Pxj的波长序号:
(e) 令xj=Pxj,n=n+1,当n<N,返回步骤(b)继续计算,否则算法结束;
(f) 最后得到所选波长序列为{k(n)=0, 1, 2, …, N-1}。
SPA通过上述步骤提取出所选中的波长序列{k(n)=0, 1, 2, …, N-1},对确定的每一对k(0)和N波长变量子集,通过多元线性回归构建的模型进行交叉验证获取均方根误差值(root mean square error,RMSE),选择最小的RMSE值所对应的波长变量组合就是SPA的最优选择结果。
-
BPNN是一种基于误差反向传播算法的监督学习算法。它由输入层、隐藏层和输出层组成,被广泛应用于分类识别[15]、质量检测[16]等任务。网络的训练过程分为前向传播和反向传播两个阶段。在前向传播中,输入信号经过每一层的神经元处理,传递到输出层产生模型的预测结果。然后,通过比较预测结果与实际输出,计算误差。反向传播阶段利用这一误差信息,沿着网络的反方向调整连接权重,以减小误差,实现网络的学习和优化。网络的每个节点都接收一组输入信号,对这些输入信号进行加权和求和,并通过一个激活函数(例如sigmoid函数)进行非线性变换,生成节点的输出。合理增加隐藏层的数量能有效拟合非线性函数,并处理复杂的输出问题。
本文中采用的BPNN为3层,输入层对应选定的特征波长数,即25个输入节点;输出层对应类别数,有7个节点。为了有效应对梯度消失问题,加速网络的收敛,选择修正线性单元(rectified linear unit, ReLU)函数作为隐藏层的激活函数。同时,为了将输出映射为概率分布以表示各个类别的概率,输出层的激活函数确定为softmax函数。设置网络训练参数:学习率为0.01;目标误差为10-5;训练次数为500次。最后调试模型确定网络结构为25(输入层)-6 (隐藏层)-7(输出层)进行预测,其网络结构如图 1所示。
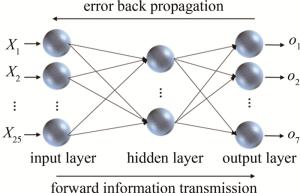
Figure 1. BPNN structure diagram
输入层的样本为Xi,隐藏层的节点输入为Bj:
式中:Hij和θj分别为输入层与隐藏层第j个神经元的连接权值和阈值;M为输入层的节点数。
输出层的节点输入Ck为:
式中:Skj和αk分别为输出层与隐藏层第k个神经元的连接权值和阈值;bj为Bj在隐藏层神经元中经激励函数运算后的输出;L为隐藏层节点数。
-
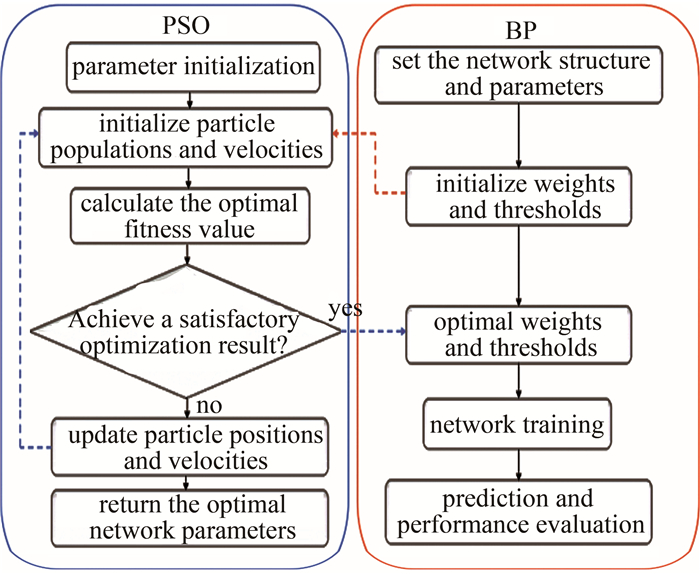
PSO选择合适的参数是一个不断试验和调整的复杂、优化问题,它具有精度高、收敛快的特点,已广泛应用在质量预测[17]、目标跟踪[18]、参数辨识[19]等领域。应用PSO优化BP神经网络时,主要任务是搜索BPNN的全局最优初始权重和阈值,如图 2所示。
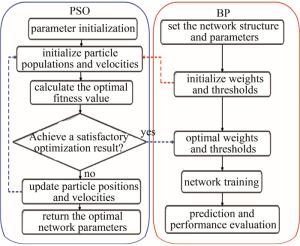
Figure 2. Steps of BPNN optimization by PSO
PSO通过迭代的方式逐渐优化解的质量,种群规模越大搜索范围也越大,有利于探索到全局最优解,但数量过多也会消耗计算资源,通常将种群规模设置在10~50之间,本文中设置为30;为了避免粒子速度增长过快或过慢,设置vmax和vmin为速度的上、下界,取值在[-1, 1]之间;为了确保解在粒子位置合理的范围内,避免越界,设置zmax和zmin为位置的上、下界,取值在[-2, 2]之间。PSO优化BPNN的步骤见下。
(a) 首先初始化n个粒子组成的种群z=(z1, z2, …, zn),种群z中的每一项代表1个粒子。粒子的位置表示BP的参数(权重和偏置),第i个粒子在D维度空间的位置向量为zi=(zi, 1, zi, 2, …, zi, D)T,(i=1, 2, …, n),其速度向量为 vi=(vi, 1, vi, 2, …, vi, D)T。
(b) 使用数据集训练BP神经网络,并选择目标函数(例如均方误差)作为粒子的适应度值。1个粒子在D维空间中所能发现的最佳位置记为Fi=(Fi, 1, Fi, 2, …, Fi, D)T,种群全局在D维空间中的最佳位置记为Fg=(Fg, 1, Fg, 2, …, Fg, D)T。
(c) 粒子的速度和位置在迭代时会更新,根据Fi和Fg按照以下公式进行更新:
式中:上标t代表当前为第t次迭代,在每一次迭代中,粒子群会更新速度和位置,寻找更好的解,为保证连续迭代达到收敛状态,本文中t取50;j=1, 2, …, D;ω为惯性权重,本文中选用自适应调整的线性递减惯性权重,经典惯性权重值一般ωmax=0.9,ωmin=0.4,本文中取初始ω=0.8;c1表示个体学习因子,c2表示社会学习因子,用于调整粒子速度更新,c1、c2在取值0和4两端时,迭代次数较大,通常取值在区间[0, 4], 本文中取c1=c2=2;r1、r2为分布在区间[0, 1]的随机数。
1.1. SPA
1.2. BPNN
1.3. PSO对BP的优化
-
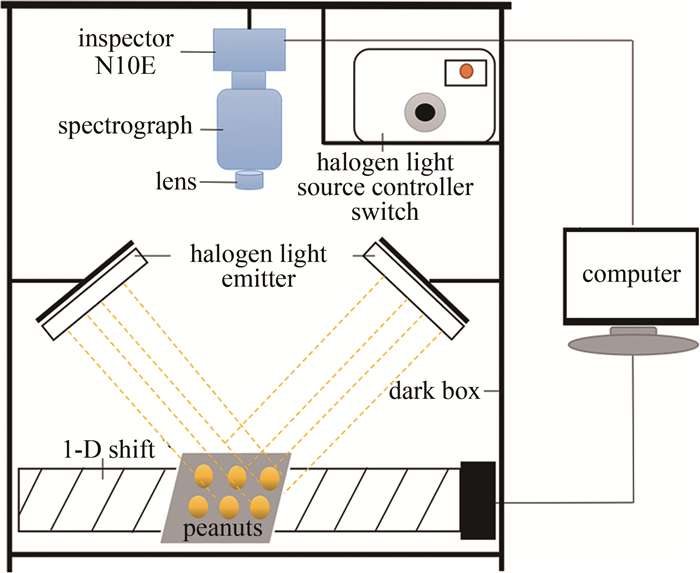
实验中选择正常良好的华一罗汉、鲁花一号、双冠白沙、优品红沙、冀花五号、黑花生和彩衣仙子共7个品种,每种100粒,共700粒花生样本。数据采集时,将样本分为7组,每组为同一品种的100粒样本,整齐排列在位移台上按照系统设置参数进行拍摄。此高光谱成像系统的主要组成有线扫描光谱仪(ImSpector N10E,400 nm~1000 nm)、14 bits的1600 pixel×1200 pixel的电荷耦合器件(charge-conpled device, CCD)相机、双侧150 W卤素灯线性光源(IT3900)、1维位移台(IRCP-0076-400)等。该系统的光谱分辨率为5 nm,图像分辨率为696 pixel×520 pixel。采集前,调整光学系统的物距、曝光时间、焦距和移动速度,保证采集到的花生图像形状清晰准确。经过多次实验,设定参数为:镜头焦距调整到30 cm~40 cm时,得到实际的采集线宽10 cm~13 cm;曝光时间为10 ms;平台移动速率为7 mm/s时,满足拍摄要求。高光谱成像系统组成如图 3所示。

Figure 3. Composition of hyperspectral imaging system
在采集图像过程中,要获取黑白噪声进行黑白校正,以减少或消除采集过程中高光谱摄像头中存在的暗电流、杂散光和电荷耦合器件的噪声干扰等影响[20]。校正公式为:
式中:R为校正后图像;Iraw为原始光谱图像;Iwhite为标准白板图像;Idark为暗场图像。
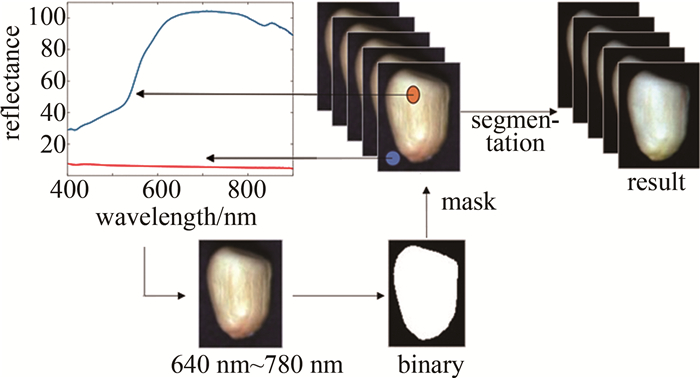
完成黑白校正后,利用阈值分割将高光谱图像划分成不同的区域集合,使每个区域具有相似的特征或属性,具有提高目标识别的准确性,降低背景干扰和噪声等效果。对图像在370.38 nm~930.23 nm之间的反射值分析,看到背景光谱与样本光谱反射值差异在641.25 nm~780.47 nm波长范围内最大,因此,使用这个波长范围的方差图进行阈值分割生成二值图像,然后将二值图像作为掩模应用于高光谱图像进行背景分割,分割后的图像背景光谱反射值则为0。由于成像系统获得的高光谱数据是通过光源照射到样本再反射到相机的反射值,所以可以把光谱数据值称为光谱反射值。单粒花生样本的背景分割过程如图 4所示。
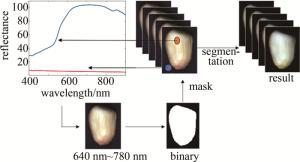
Figure 4. Process of segmentation in hyperspectral image
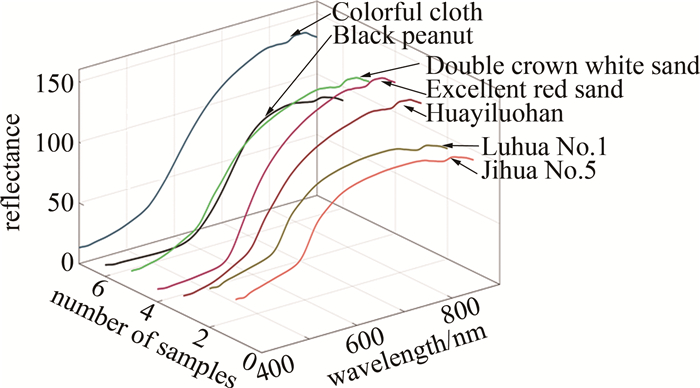
完成分割后,使用软件对图像感兴趣区域内的有效光谱信息进行提取。该成像系统的图像分辨率为696 pixel×520 pixel,故获得了样本在370.38 nm~930.23 nm波长范围内的共有700行和520列的高光谱图像数据矩阵。矩阵的行代表样本数,列代表光谱波长值及对应的特征。去除370.38 nm~399.81 nm和901.36 nm~930.23 nm这两个波长范围内的受噪声和杂散光影响较大的57列波长数据后,整合剩下在400.83 nm~900.25 nm范围内的光谱波长数据为一个700行463列的新矩阵,得到7种样本光谱平均反射值,如图 5所示。
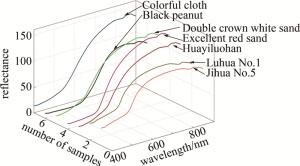
Figure 5. Spectral reflectance of seven peanut samples
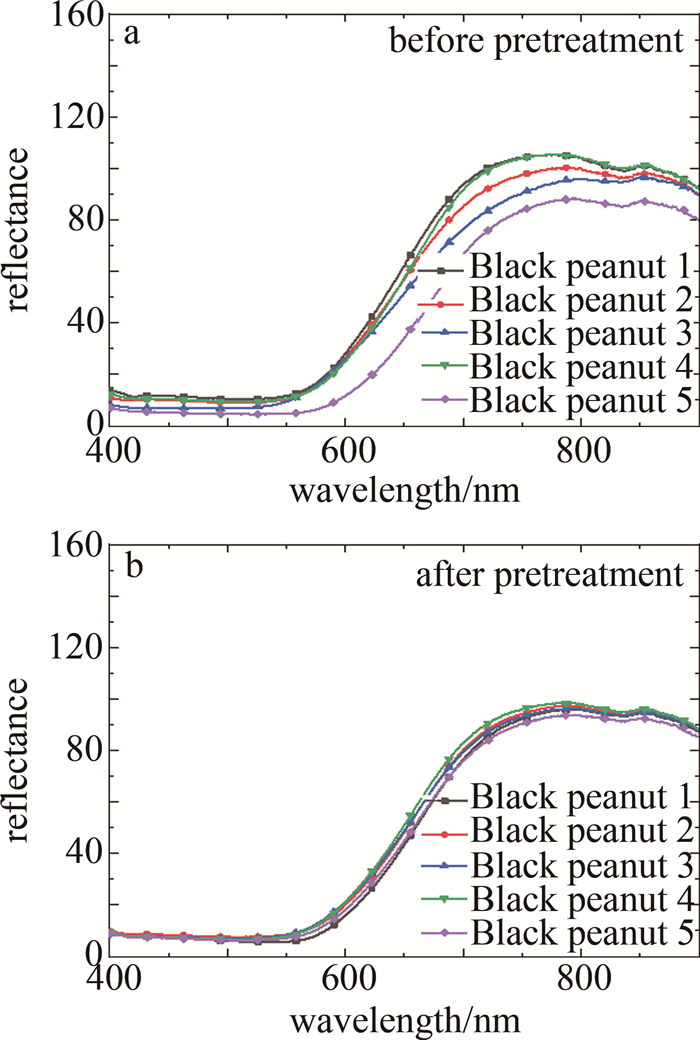
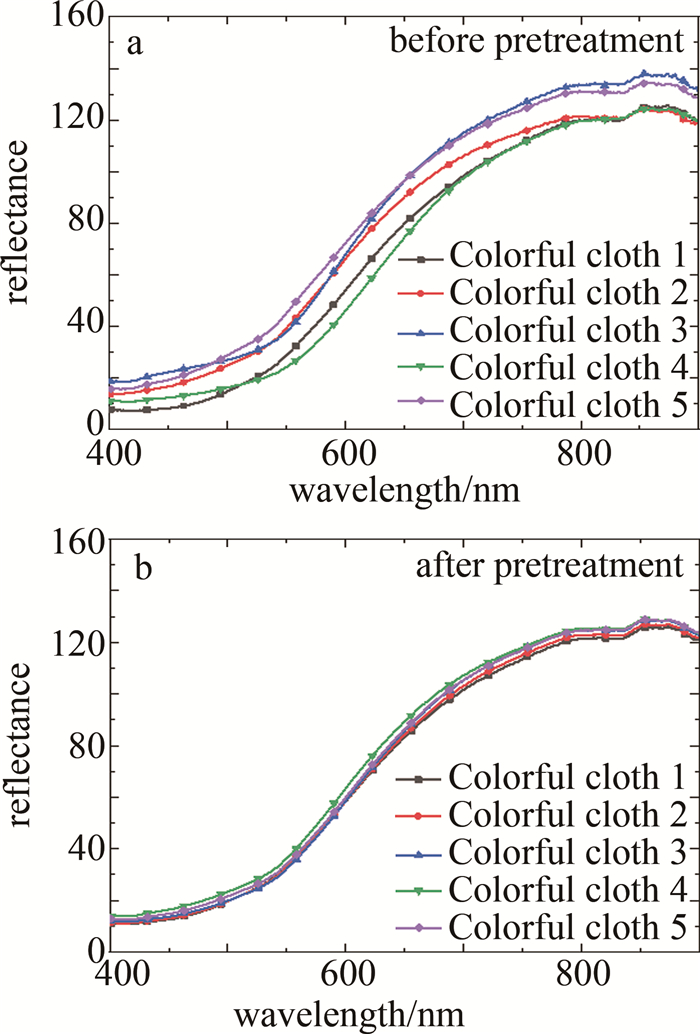
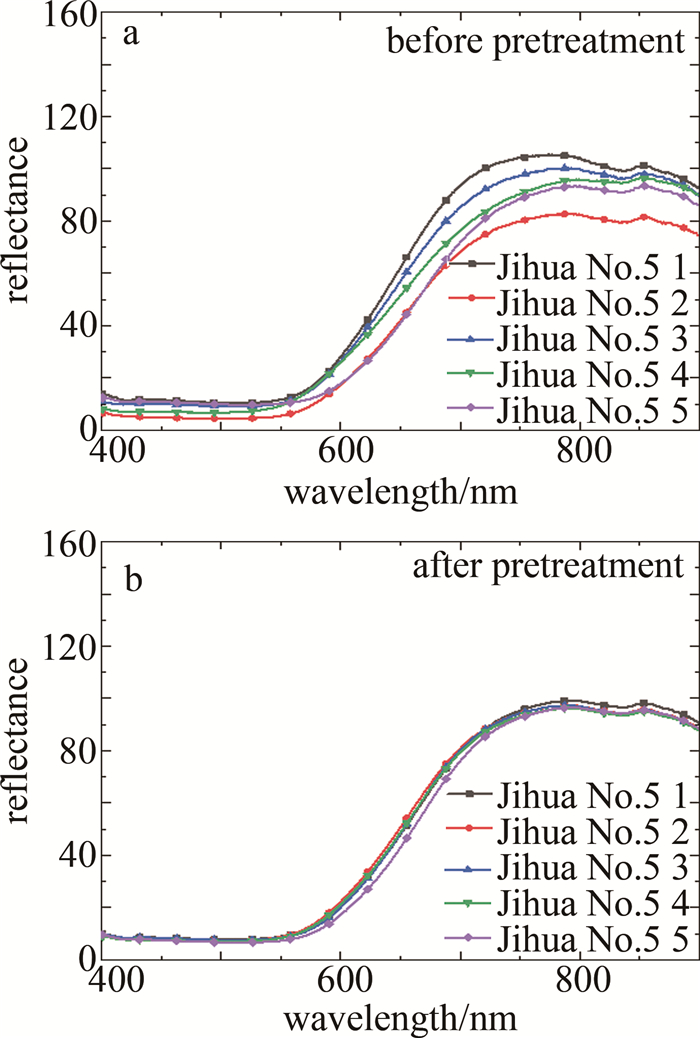
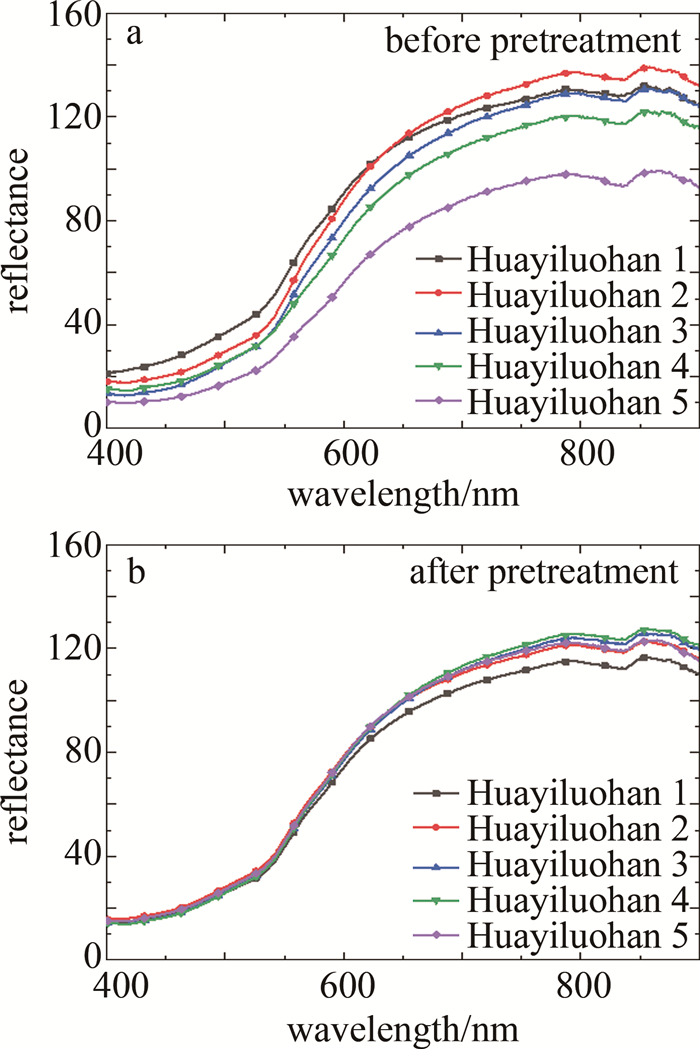
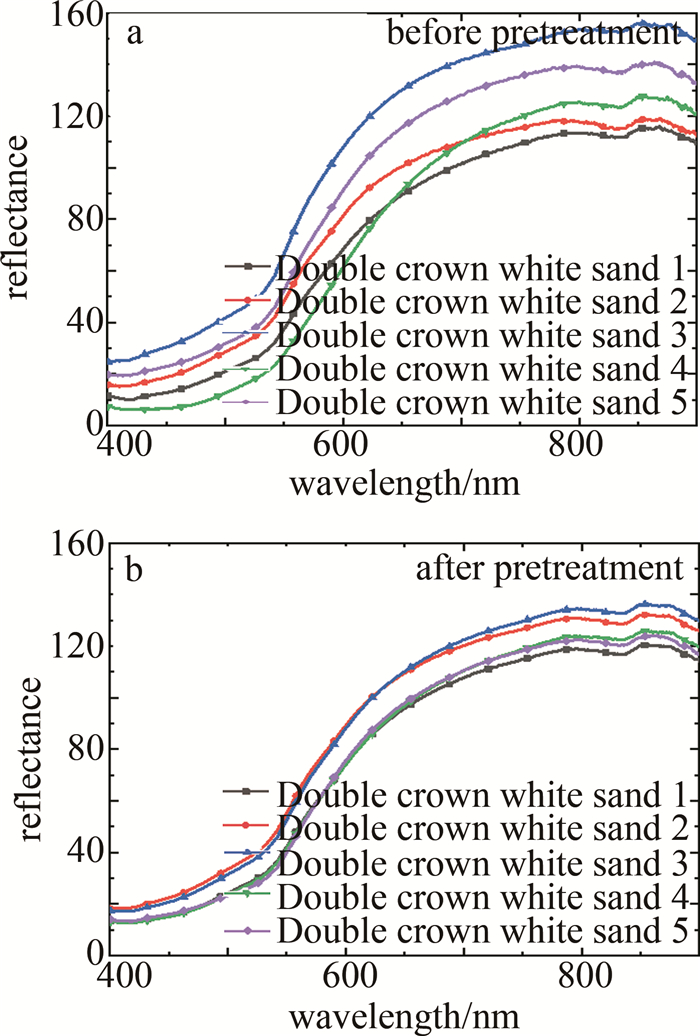
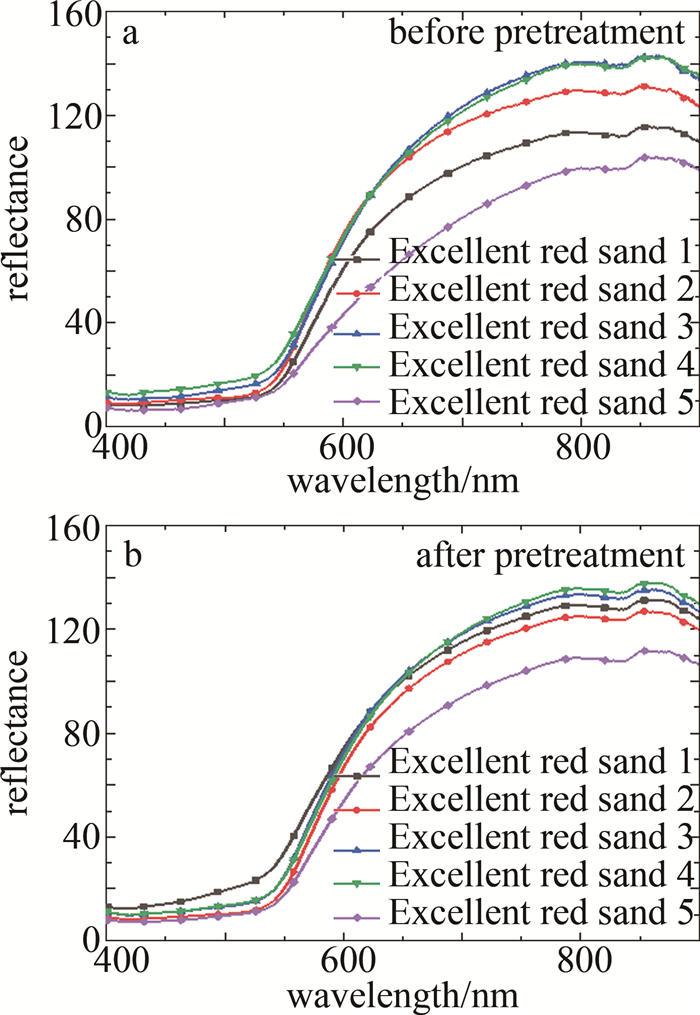
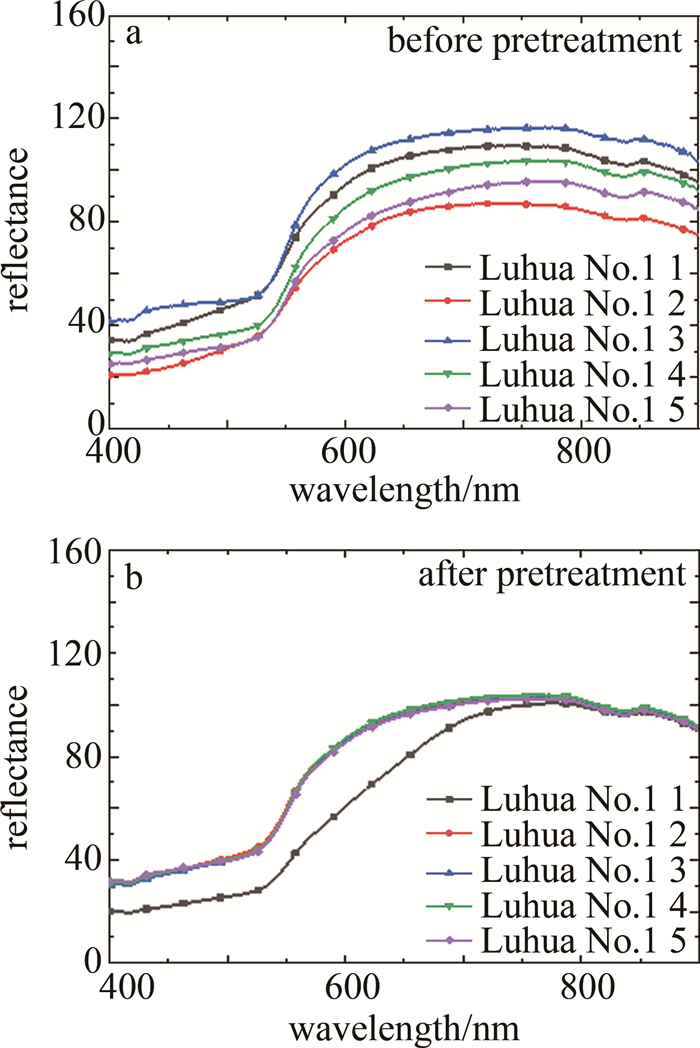
在利用光谱矩阵构建模型前,采用SG算法拟合局部数据点的多项式来去除数据中的高频噪声和干扰信号,在不破坏原有特征的情况下对光谱数据进行平滑处理,可有效提高数据的信噪比,增强模型的鲁棒性及分类精度。SG算法多项式阶数的取值范围在[0, 4]之间,本文中取2;拟合的窗口长度应根据数据的特征和噪声水平进行选择,窗口长度应该足够大以覆盖数据中的特征,并且可以平滑噪声的影响,同时也避免过度平滑导致信号变得模糊,本文中取13。对所有图像数据进行SG预处理后,选取每个品种的5个典型样本的光谱曲线展示,如图 6~图 12所示。图 6~图 12分别为黑花生、彩衣仙子、冀花5号、华一罗汉、双冠白沙、优品红沙以及鲁花1号共7种花生样品预处理前后的曲线。
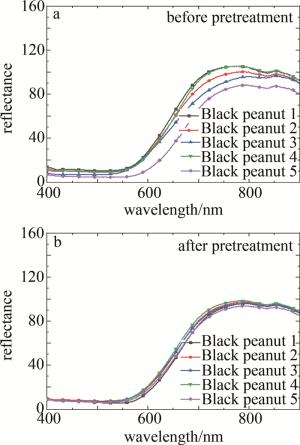
Figure 6. Spectral curves of Black peanut samples before and after pretreatment
Figure 7. Spectral curves of Colorful cloth peanut samples before and after pretreatment
Figure 8. Spectral curves of Jihua No.5 peanut samples before and after pretreatment
Figure 9. Spectral curves of Huayiluohan peanut samples before and after pretreatment
Figure 10. Spectral curves of Double crown white sand peanut samples before and after pretreatment
Figure 11. Spectral curves of Excellent red peanut samples before and after pretreatment
Figure 12. Spectral curves of Luhua No.1 peanut samples before and after pretreatment
结合图 5和图 6~图 12可知,品种为冀花五号的样本在波长范围400.83 nm~650.82nm之间反射值较高,品种为彩衣仙子的样本在波长范围687.97 nm~900.25 nm之间反射值最高,与其它品种花生的光谱曲线差异较为明显,这些差异主要是由于花生中的蛋白质、脂肪、叶绿素和水的成分含量不同而在光谱的不同波长区间的反射值不同造成的。
-
原始光谱数据庞大,在光谱波长之间存在共线性和冗余,会使模型运算时间变长、分类准确度降低。为解决这些问题,使用SPA来选择最具信息性、最少冗余和最小共线性的特征波长。在SPA应用中,波长数选择范围设定为5~40,同时进行数据缩放,可得到预测集的RMSE值(见图 13a)以及特征波长的索引位置分布(见图 13b)。
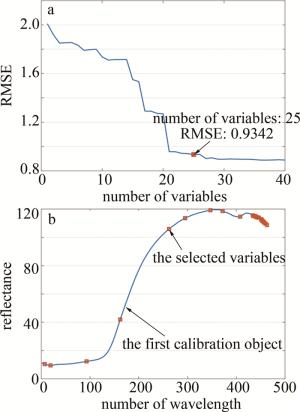
Figure 13. Characteristic wavelengths selected based on SPA
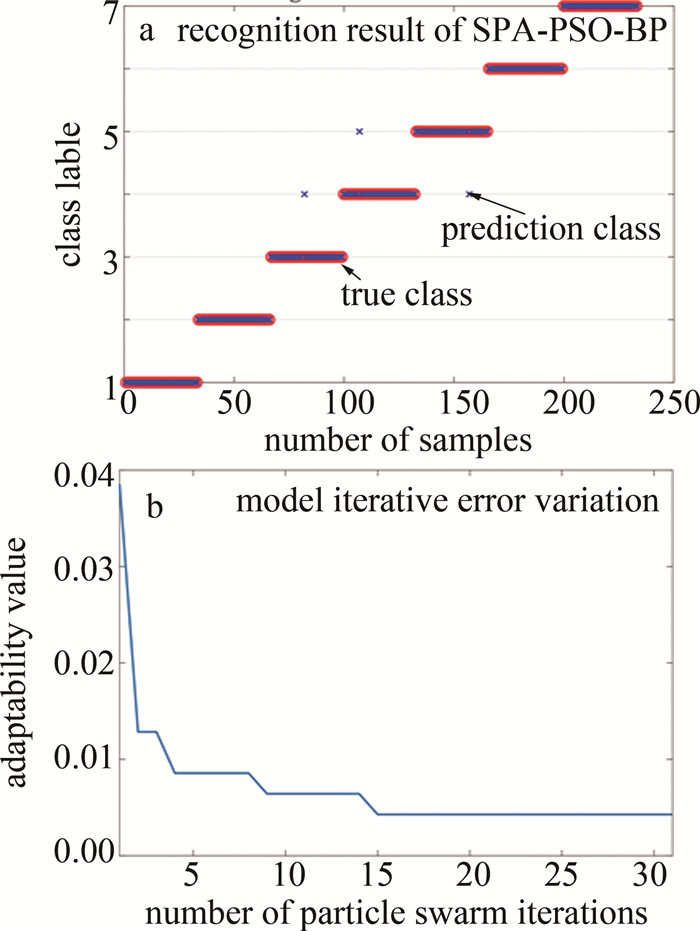
由图 13a可知,当选择的特征波长数为25时,对应的RMSE取得最佳值为0.9342。特征波长的位置分布如图 13b所示。这些特征波长值从400.83 nm~900.25 nm,主要集中在828.10 nm~899.14 nm范围之间。在模型开发之前,为了使模型减少过拟合的风险,增强泛化能力,也同时避免样本差异带来影响,把7个品种的700粒花生样本数据集打乱,按照比例为2∶1随机划分为两组,训练集为467粒,测试集为233粒。采用SPA-PSO-BP方法建模识别的结果如图 14所示。图 14a为模型识别准确率;图 14b为模型迭代误差变化。
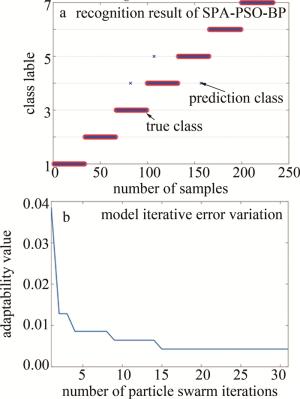
Figure 14. Discriminant results based on SPA-PSO-BP
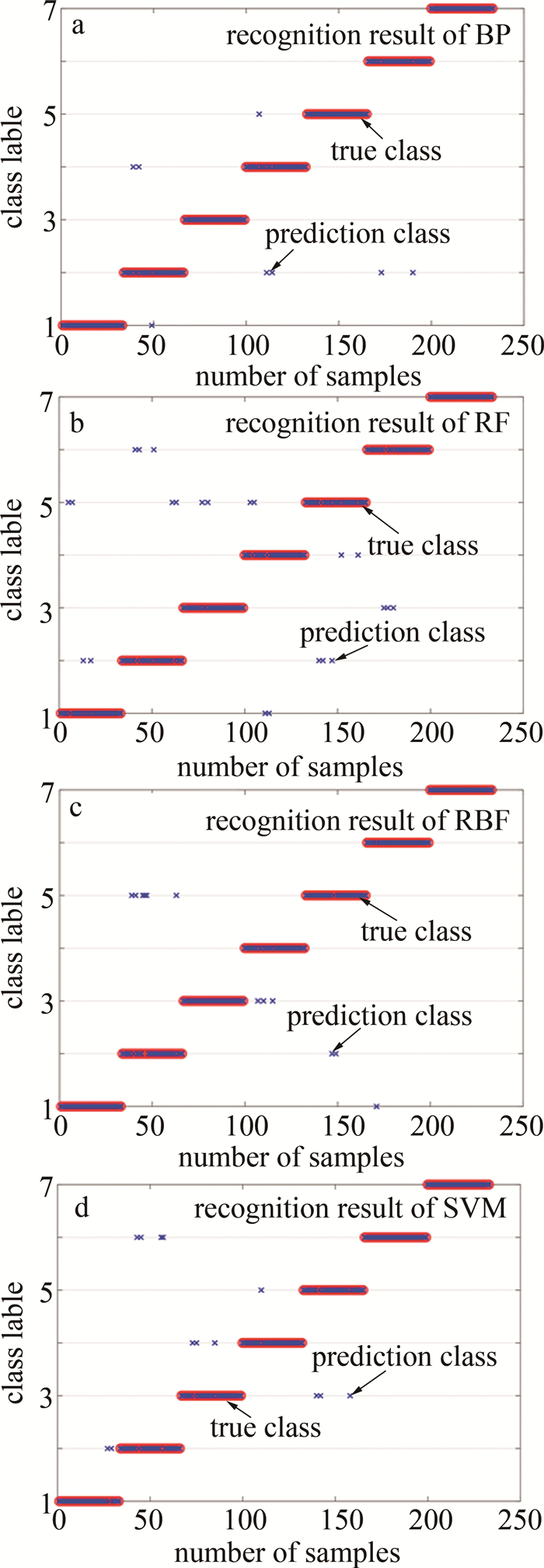
由图 14b可观察到,在模型训练的过程中,当粒子群迭代次数增加时,BPNN的适应度值(即错误率)逐渐减少,并且当迭代次数达到15时,模型实现收敛,适应度值为0.004,足够小,代表BP也完成了优化迭代求解,最终在预测集上达到了准确率为98.7%,kappa系数为0.98,遗漏误差为3的结果。RF可以处理大规模、不平衡的数据集,但对于线性模型解释困难;SVM适用于小样本和高维数据,但模型容易过拟合且对于参数调节比较敏感;RBF神经网络优点是能够处理非线性问题,模型具有较好的泛化能力。但是缺点比较明显:需要调节的超参数较多、对参数敏感、训练时间长等。基于SPA-PSO-BP方法构建模型的25个特征波长,与4种对比判别算法识别的结果如图 15所示。
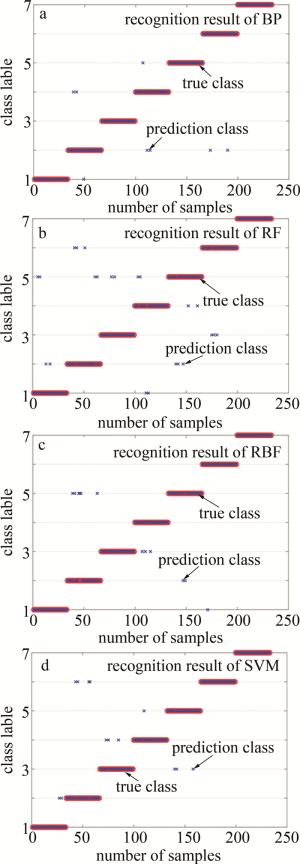
Figure 15. Results of four contrast discriminant algorithms
由图 15a可知,经典BP算法的识别检测准确率为96.6%,比基于PSO-BP方法的识别准确率低2.1%,且RF、RBF和SVM分类判别算法的识别准确率也分别比PSO-BP低了8.6%、3.9%和4.3%。结果证实了经PSO对BP的初始权值和阈值优化后,基于SPA-PSO-BP方法对于有差异、复杂的样本能很好地进行分类判别,且精度更高,模型泛化能力强。本文中使用准确率、kappa系数及遗漏误差作为模型结果评价指标,kappa系数公式定义为:
式中:po是每一类正确分类的样本数量之和除以总样本数,即为观察到的精确度;pe为期望的精确度。κ的取值范围为[-1, 1],取值越接近1代表评估性能越好。对4种对比判别算法的评价指标、预测结果和相关参数的设置如表 1所示。表中,c为SVM算法中的惩罚系数;kernel函数运用线性。
recognition algorithm parameter omission error prediction accuracy/% kappa coefficient BP hidden layer: 10 8 96.6 0.96 RF trees: 60 leaf: 3 23 90.1 0.89 RBF spread: 100 12 94.8 0.94 SVM c: 10 kernel function: linear 13 94.4 0.94 Table 1. Parameter settings, prediction results and kappa coefficients of four comparative discriminative algorithms
由表中数据可知,在4种对比判别算法中,BP的识别准确率最高为96.6%,但仍然比基于PSO-BP的识别准确率低2.1%,这代表PSO优化了BP的初始权重和阈值,增强了其对于高光谱图像的分类能力,证实SPA可以减少或消除原始光谱数据波长间的冗余信息、共线性等问题,说明了基于SPA-PSO-BP方法构建的模型应用在可见光-近红外波长区间的高光谱图像分类具有很好的预测准确率和鲁棒性。
2.1. 高光谱图像采集、背景分割与预处理
2.2. 基于SPA-SPO-BP分类方法的建模

-
基于可见-近红外高光谱成像技术,对采集的7种花生样本的高光谱数据进行定性分析,构建基于特征波长的SPA-PSO-BP的分类检测模型。结果证明,去除受噪声和杂散光影响大的部分波段,使用SG卷积平滑和图像分割对400.83 nm~900.25 nm之间的光谱数据进行预处理,可以减少光谱数据中的干扰因素带来的影响。利用SPA从463个波长变量中选择25个特征波长,有效地减少了模型运算时间,降低了检测模型的复杂度。利用PSO对BP的初始权重和阈值优化来寻找最优解,可以提高SPA-PSO-BP模型的分类性能,增强模型鲁棒性。最后预测集的模型准确率、kappa系数与遗漏误差分别为98.7%、0.98和3,相较4种对比分类判别模型也验证了SPA-PSO-BP分类模型的高精度和稳定性。综上所述,基于可见-近红外光谱结合SPA-PSO-BP可以实现不同花生品种的快速、无损及高精度的分类鉴别,为花生品质检测的进一步研究提供方法和参考依据。
 DownLoad:
DownLoad: