 Map
Map

HTML
-
目标识别技术在计算机视觉领域扮演关键角色,这项技术不仅提升了智能监控系统的性能,还推动了自动驾驶车辆的创新发展,同时在工业和智能家庭领域中发挥着实际作用。红外图像由于具有穿透迷雾、烟雾和低光环境的特点,在军事和安全侦察[1]以及监测方面非常有用。尽管在具体场景下,红外图像拥有较长的红外波长,但在相同成像条件下,红外图像的空间分辨率通常较低。与可见光图像不同,红外图像是通过探测器捕捉物体表面的热辐射来完成成像的。这种热辐射受到外部环境和气候等多种因素的影响,目标的探测和识别在这种情境下变得更加具有挑战性。
目标检测算法可分为传统和机器学习两大类。主流的传统方法在红外图像目标检测中运用了边缘检测、模板匹配以及霍夫变换等相关技术。一些算法利用边缘、轮廓[2]和纹理进行目标检测,例如使用方向梯度直方图(histogram of oriented gradient,HOG)[3]特征进行行人检测。然而,这些传统方法需要手动提取图像特征,依赖先验知识且表达能力有限,从而限制了准确性。
近些年,将深度学习应用于目标检测算法中已取得显著的成果。2014年,GIRSHICK等人提出了第1个基于深度学习的目标检测算法区域卷积神经网络(regional convolutional neural network,R-CNN)[4],该算法将图像分割成多个感兴趣区域(region of interest,ROI),对每个ROI执行卷积神经网络,并使用支持向量机(support vector machine,SVM)进行分类。为了提高速度,2015年,GIRSHICK等人提出了fast R-CNN算法[5],在整个图像上执行卷积神经网络,然后使用ROI池化对每个感兴趣的区域进行处理。相比之前的两阶段目标检测算法,一阶段方法如单次多边框检测(single shot multibox detector, SSD)和RetinaNet, 在速度上有较大提升[6]。2016年,REDMON等人提出了你只需看一次(you only look once, YOLO)算法[7],利用单个卷积神经网络同时进行边界框和类别的预测,对整个图像进行处理,实时运行。尽管初始版本的YOLO在准确率和对小目标的检测能力上存在一些不足[8],但经过改进,目前在工业领域得到广泛应用[9]。
与基于候选区域的方法相比,YOLOv1利用全局图像信息来预测边界框和类别[10],消除了候选区域的问题。同时,YOLOv1采用单一网络,在端到端的训练中同时学习检测和分类任务。YOLOv2引入了批量归一化来减少协变量的偏移[11],并使用锚框来处理不同大小的目标,它采用高分辨率的特征图进行检测,以最小化物体检测定位误差。YOLOv3使用特征金字塔网络(feature pyramid networks, FPN)来实现多尺度目标检测,FPN通过顶层向底层进行边界融合, 构建一个由大到小尺度的特征金字塔;基于这个特征金字塔, YOLOv3采用统一大小的全卷积网络头进行预测, 以检测不同尺寸的目标,这种设计融合了不同语义级别的特征, 增强了对小目标的检测效果。此外,YOLOv3对训练数据进行了增强,如随机旋转、裁剪等操作,以更好地适应不同的场景。YOLOv4使用了空间金字塔池化和路径聚合网络等技术来实现多尺度特征融合[12],并通过替换原来的损失函数为Mish激活函数,YOLOv4增强模型的非线性化能力和稳定性水平,引入了一系列改进策略,包括在输入端应用Mosaic数据增强技术和DropBlock正则化等。
本文作者希望是在红外图像对比度低、成像模糊,且目标尺寸小的情况下,通过深度学习方法实现高性能的红外目标技术同时控制模型参数,以适应嵌入式设备的部署。为了实现这一目标,在YOLOv5s的基础上,采用迁移学习进行训练,并通过引入坐标注意力(coordinate attention,CA)机制模块、添加额外的预测层来提升小目标的检测能力,同时修改特征融合网络和损失函数。
-
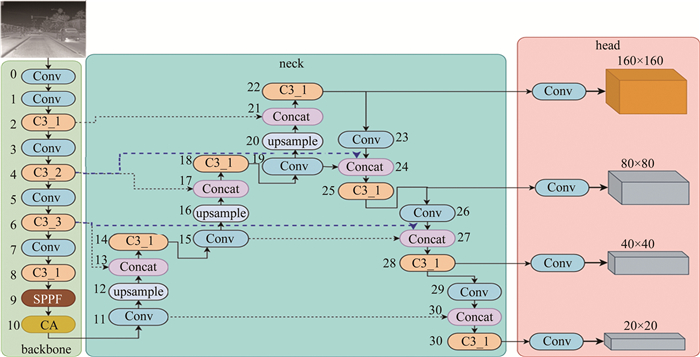
YOLOv5是目前广泛采用的主流一阶段目标检测算法,通过灵活控制模型的宽度和深度来管理参数量和计算量。此外,YOLOv5通过调整深度和宽度,构建了多个网络结构,如YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x。其中,YOLOv5s适用于嵌入式部署,成为改进的基准模型。整体而言,YOLOv5的架构包括输入端、主干特征提取网络、特征融合网络、检测头。输入端主要进行一系列图像预处理操作,包括将图像缩放到指定尺寸、使用Mosaic数据增强技术、自适应锚框计算等[13]。
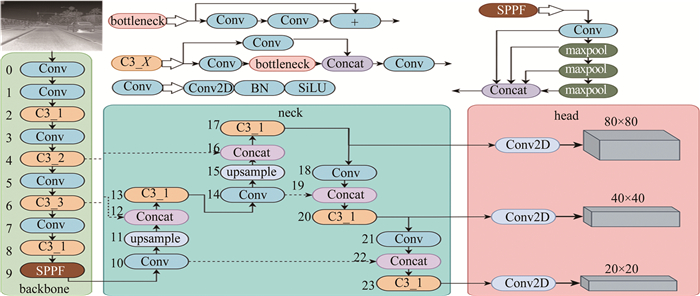
YOLOv5的主干特征提取网络采用了跨阶段局部网络(cross stage partial network,CSPN),是一种高效的卷积神经网络结构;CSPN的基本单元是CSP模块,也即是C3模块,每个CSP模块包含两个卷积层和一个残差块;YOLOv5主干网络包含卷积(convolution, Conv)模块、C3模块和快速空间金字塔池化(spatial pgramid poolring fast, SPPF)模块,如图 1所示。图中,Concat(concatenate)表示拼接,BN(batch normalization)表示批归一化,SiLU(sigmoid linear unit)激活函数是修正线性单元(rectified linear unit,ReLU)激活函数的改进版。Conv模块对图像提取特征的同时也对图像进行了下采样,下采样相对于输入图像的倍数分别为: {2, 4, 8, 16, 32};C3模块不对图像进行下采样,C3模块通过堆叠卷积层和残差连接来增加深度,并增加通道数以增强特征表示能力。C3后缀_1, _2表示其中bottleneck的个数。SPPF可以有效地提取图像特征,并且能够适应不同尺度和长宽比的目标。
Figure 1. YOLOv5s structure diagram
YOLOv5采用了路径聚合网络(path aggregation network, PAN),与FPN类似,它也是一种特征金字塔结构。PAN采用路径聚合机制处理多尺度和遮挡问题。它包括特征金字塔网络和动态路径聚合模块,通过整合不同感受层的信息提高了模型对复杂场景的性能,可用于目标检测和实例分割任务[14]。
原始YOLOv5拥有3个预测特征层,每个预测层的输出结构为(b, na×(nc+4+1), S, S), b为输入批次的大小;na为每个网格的边界框数量;nc为预测的类别数;4为每个锚框预测的坐标点值(x, y, w, h)信息,w为宽度,h为高度;1为预测的类别置信度,用于分类不同类别;YOLOv5检测头将图像划分成S×S个网格进行目标检测,对每个网格使用na个锚框进行预测。
-
在YOLOv5s的初始网络中, 通过逐步递增下采样率, 分别对输入图像进行8倍、16倍和32倍下采样, 得到了3个不同尺寸的预测特征层, 其大小依次为80×80、40×40和20×20。这种多尺度的设计可以检测不同尺寸的目标。因为大特征图往往包含很多的上下文特征信息,所以利用大特征图检测小目标、小特征图检测大目标,以实现更全面的特征捕捉。对于FLIR数据集中有许多小目标,YOlOv5s使用多层下采样操作来减小特征图的尺寸,从而提高算法的检测速度。但是,过度的下采样可能会对模型的精度产生负面影响。当下采样的程度过大时,物体在特征图中的表示将变得模糊,这会导致模型在检测小目标或者密集目标时出现误判。此外,由于下采样会压缩原始图像信息,因此在下采样之后再进行上采样或反卷积操作时,由于丢失了部分信息,很难还原到原始图像中,从而降低了定位精度。因此,添加了一个160×160大小的特征预测层[15],该层是对输入图像进行4倍下采样,相对于直接增加输入图像的大小,增加额外的预测层可以一定程度减少计算量,同时能保持大目标尺寸不变,如图 2所示。
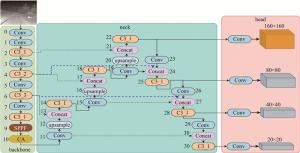
Figure 2. Improved YOLOv5s structure diagram
-
注意力机制是指一种可以动态地将模型关注的重点集中于输入数据的某个部分的技术。它是通过深度神经网络来实现的,旨在提高模型的准确性和效率。因此,相对于原始YOLOv5s在主干网络的末端添加了CA机制模块,来捕获不同位置的特征信息,本文作者更加关注特征图的重点区域,如图 2主干网络所示。
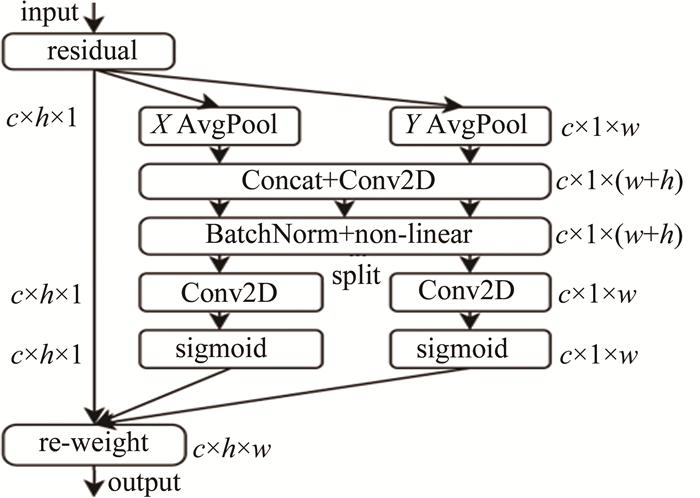
CA机制[16]与通道注意力机制[17]存在着差异。后者将经过注意力模块的特征图转换为单个特征向量,CA机制则采用了一种不同的方法,它通过在通道维度上对经过注意力机制模块的特征信息进行分解,利用两个独立的1维特征编码过程来汇聚坐标特征。相较于通道注意力机制,这种方法的优势在于能够捕捉不同维度的特征依赖关系,从而提升了所关注对象的表示能力。
现有的注意力机制[17-18]在计算通道注意力时通常采用全局最大平均池化处理通道,但这种方法会导致物体的空间信息丢失。为了解决这个问题,CA机制将位置信息嵌入到通道注意力中。CA机制的实现包括两个并行阶段:首先对特征图进行在两个方向进行了全局平均池化操作,分别得到代表宽度和高度方向的特征图。假设输入特征图形状为[c,h,w],则宽度方向的特征图形状为[c,h,1],高度方向的特征图形状为[c,1,w]。接着,将这两个特征图合并,经过宽度和高度维度的转置后堆叠在一起,形成形状为[c,1,h+w]的特征图。通过卷积、归一化和激活函数对该特征图进行进一步处理,以获取更丰富的特征表示。在第二阶段中,第一阶段获得的特征图被分成代表宽度和高度方向的两个并行流。每个流都被转置为代表宽度和高度方向的两个特征图[c,h,1]和[c,1,w]。应用1×1卷积来调整通道数量,并使用sigmoid函数获得宽度和高度方向的注意图。这些注意图与原始特征图相乘,使用CA机制获得最终的关注特征图,如图 3所示。图中,c表示通道尺寸,w表示宽度,h表示高度,AvgPool(average pool)表示平均池化。
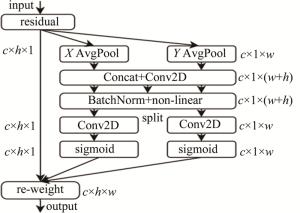
Figure 3. CA mechanism
总体而言,将CA机制嵌入到YOLOv5可以在捕获不同空间方向上的依赖关系的同时,将位置信息编码到通道注意力中,从而产生更全面的对象表示。
-
在2维目标视觉检测任务中,受物体尺寸、角度、姿态等因素影响,同一物体可能在不同尺度和感知层次上呈现出多样的特征表达。因此,为了提高模型在多尺度信息上的感知能力和特征表达能力,特征融合网络成为了目标检测领域中重要的研究方向之一。
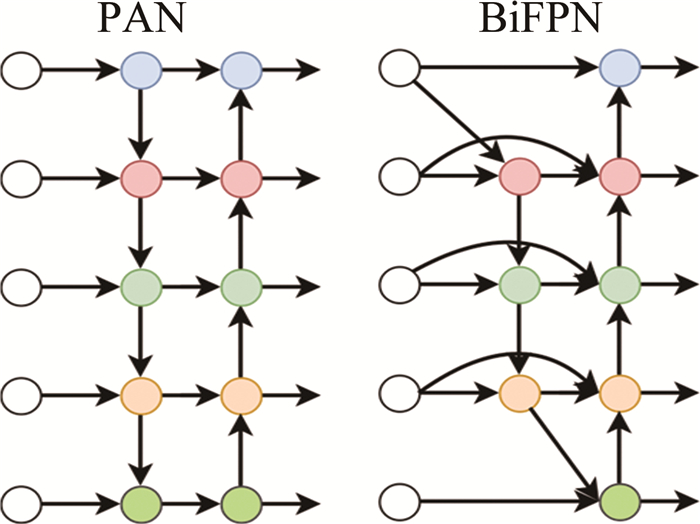
YOLOv5将PANet作为模型的特征融合网络,在不同的层次上提取到的特征图被分别传递到更高层级的特征图中进行融合,从而使得模型可以利用多层次、多尺度的特征信息来进行目标检测。这种特征融合方式相比于FPN和初始网络结构搜索(neural architecture search feature pyramid network, NAS-FPN)虽然提升了检测精度,但是仍然具有较多的冗余参数和较多的参数量。因此将双向特征金字塔(bidirectional FPN,BiFPN)[19]网络作为了YOLOv5的特征融网络,不仅能够有效提高模型的感知能力和表达能力,还能够降低计算量和存储空间的需求,同时具有一定的通用性和灵活性,适用于各种不同的目标检测场景和模型架构。
PAN和BiFPN结构如图 4所示。相对于PAN,BiFPN通过删除仅有单个输入边的节点来减少网络模型中冗余参数的数量,因为这些单个输入边的节点对特征融合贡献少。此外,如果原始输入和输出节点位于同一层,BiFPN会添加额外的边来实现更大范围的特征融合,而不增加过多的计算成本。BiFPN通过双向特征传播结构,在高低层特征图之间进行多轮上下采样和融合,使低层高分辨率特征与高层语义信息结合,其跨尺度连接让不同尺度特征图更好融合互补,小目标特征可通过顶层语义信息补充增强。BiFPN重复多轮特征聚合,持续强化和补充小目标特征,而原始YOLOv5的PAN一次特征聚合对小目标影响有限。
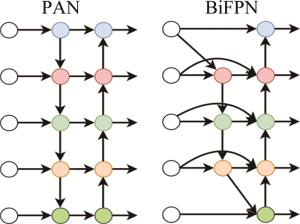
Figure 4. Schematic diagram of PAN and BiFPN
为了更高效地融合来自不同层的特征表示信息,采用了一种双向多尺度特征金字塔融合网络,替代YOLOv5中颈部的特征融合网络。通过引入双向结构、跨尺度直接连接以及多轮特征聚合等设计,更有效地捕捉和利用了红外图像中小目标的特征信息。这项研究为解决目标尺度变小的挑战提供了一种新的视角,并在特征融合方面取得了显著的改进。此外,引入BiFPN技术也有助于实际工程应用方面的优化,因为它能够减少计算量并缩小模型大小,使得红外目标检测算法更适合在实际场景中使用。
-
损失函数的作用是衡量模型预测值和实际标签值之间的区别,通过调整模型参数以最小化损失函数的过程。YOLOv5的损失函数由3个损失函数组成:定位损失Lloc、置信度损失Lobj、分类损失Lcls,YOLOv5的总损失为3个损失的加权和,即L=a×Lloc+b×Lobj+c×Lcls。本文中仅对定位损失进行优化,早期的目标检测中定位损失使用ln直接对边界框的4个x, y, w, h参数进行回归,而ln损失函数并没有考虑到边界框的交并比(intersection over union,IOU),后来人们提出了基于IOU的损失函数,从而辅助训练出更好的目标检测器。虽然IOU损失函数考虑了交并比,但是当两个边界框不重叠时,IOU会出现梯度消失的问题,导致模型收敛很慢、平均精度均值变低。
在IOU的基础上引入了外接最小矩形框,随后发展出了总交并比(generalized IOU, GIOU)损失函数,以解决当预测框与真实标签框无重叠时导致梯度消失的问题。进一步,距离交并比(distance IOU, DIOU)损失函数的提出解决了GIOU损失函数在存在包含关系时回退到IOU损失以及收敛速度较慢的问题。这一演进在目标检测任务中有效地克服了不同情景下的梯度问题,提高了模型的训练鲁棒性。
YOLOv5s选用完全交并比(complete IOU, CIOU)损失函数作为其定位损失函数,CIOU在DIOU的基础上进行了改进,特别是加入了对检测框尺度、长宽比等方面的损失,从而更全面地优化了预测框的准确性。这一选择旨在更好地平衡模型对目标尺度和形状的敏感性,为模型在目标检测任务中的性能提供了更为精细的调整。
具体计算公式如下所示:
式中:b和b′为预测框和真实标签框的中心点;ρ(·)为两个中心点变量的欧氏距离;c为预测框和标签框外包最小矩形的对角线长度;w和h为预测边界框的宽和高;w′和h′为真实边界框的宽和高。
对比于GIOU和DIOU,CIOU增加了检测尺度和纵横比的损失,收敛速度和检测的准确率有大幅提升。尽管纵横比可以用来描述物体宽高之间的相对关系,但由于其存在相对性和未考虑难易样本平衡问题等因素,可能会产生一定程度的模糊性和偏差。因此在LCIOU的基础上,引入焦点(focal)有效交并比(efficient IOU, EIOU)损失函数[20]作为YOLOv5的定位损失函数,其原理如下所示:
式中:γ是一个控制异常值抑制程度的超参数;w″和h″是预测框和标签框外包最小矩形的宽和高。EIOU的损失函数由三部分组成:LIOU是IOU损失;Ldis是距离损失;Lasp是边长损失。
focal-EIOU损失函数是基于经典的focal损失函数和EIOU损失函数进行改进得到的。具体来说,focal损失函数专注于缓解类别不平衡问题,而EIOU损失函数则可以有效地优化目标框的回归精度和匹配程度。在focal-EIOU损失函数中,融合了这两种损失函数的优势,通过引入γ系数和IOU指标,进一步提升了模型训练和预测的效果。在focal-EIOU损失函数中,增加了一个参数γ,它的作用是使得损失随着IOU的增加而变化。这表明,随着目标与预测框之间的IOU减小,损失增大,从而鼓励模型更有效地回归目标框,以提升回归的准确性。引入focal损失函数能够有效应对边界框回归任务中存在的样本不平衡问题。通过减缓对那些与目标框重叠较少的大量锚框的影响,特别在高质量锚框上,显著提升了模型的性能表现。这一方法有助于更好地应对训练数据中的样本不平衡,使模型更专注于关键区域,从而进一步提高边界框回归任务的准确性。
综上所述,EIOU损失函数相比于之前的IOU损失函数,可以更加明确预测框和目标框在重叠面积、中心点位置以及边长尺寸上的差异。基于EIOU损失函数, 进一步引入focal思想来处理样本不平衡问题:利用目标框和预测框的IOU来重新加权EIOU损失函数, 高IOU的高质量样本被赋予更大的权重, 低IOU的低质量样本被抑制, 让模型更加关注对定位质量有正面贡献的样本,实现更加鲁棒和准确的目标检测,提高模型对目标的检测能力。综上所述,本文中引入focal-EIOU损失函数作为YOlOv5的定位损失函数。
2.1. 增加额外的预测层
2.2. 坐标注意力机制
2.3. 双向特征金字塔网络
2.4. 损失函数的改进
-
本文中进行了如下参数的优化:采用Adam优化器,参数β1设定为0.98,学习率的初始值为0.001,同时设置权重衰减系数为0.0005, 批处理大小选取为64。所有的输入图像的尺寸为640×640,训练的轮次数是200次,为了增加每个样本的上下文信息,训练中启用了Mosaic数据增强技术。训练平台配置如表 1所示。
name configuration information CPU(central processing unit) Intel(R)Core i9-10900X GPU(graphics processing unit) NVIDIA RTX 3090 ×2 framework Pytorch 1.12.1 environments CUDA11.6 CUDNN8.3.2 Table 1. Training platform configuration
-
使用的FLIR数据集特点是真实性高、多样性强,具有较高的挑战性。FLIR热图像数据集的训练数据集有10742张红外图像,验证数据集有1144张红外图像。原始数据集包含的标签种类有人、汽车、自行车、摩托车、公交车、狗等15类目标,挑选了目标数目最多的两类人和汽车,目标数量分别为50478和73623。
-
为了对训练出来的模型进行性能评估,进而优化算法、提高准确率和泛化能力,需要对训练模型进行多方面评估。真正例(true positive,TP)T表示实际为红外目标正例且被模型准确地预测为红外目标正例的次数;假正例F则是指模型错误地将实际为红外图像非正例(false posifive, FP)的目标预测为正例的次数;假负例(false negative,FN)表示为N。
精确率是衡量预测为正类别的样本中有多少是真正的正类别,其计算公式为:
召回率反映正确识别出的正样本占所有正样本的比例, 直观地反映模型的覆盖面,其计算公式为:
平均精确率(average precision,AP)PAP主要用于衡量预测框和真实框之间的匹配程度。在目标检测任务中,通常通过计算精确率-召回率曲线下的面积来评估模型性能。该曲线展示了在不同的置信度阈值下,精确率和召回率之间的关系,其计算公式为:
全类别平均精确率(mean average precision, MAP)PMAP是一个相对综合的指标,同时考虑了模型在不同类别上的表现。通常情况下,MAP越高表示模型的性能越好。对每个类别(i=1, …, m)的AP取平均即可得到MAP,其计算公式为:
-
为了验证改进算法对红外目标的有效性,进行了一系列消融实验,结果如表 2所示。在这些实验中,实验以YOLOv5s作为基准算法,并使用MAP两个评价指标来评估实验效果。表中,“√”表示针对原始算法进行的改进点,以下IOU阈值均大于0.5。分别进行了A、B、C、D 4组消融实验。
model +head BiFPN CA EIOU MAP/% YOLOv5s 81.1 A √ 83.9 B √ √ 84.5 C √ √ √ 84.8 D √ √ √ √ 85.4 Table 2. Improved Yolov5 ablation experimental data
由表 2可以看出,A组实验添加了一个额外的检测层,虽然增加了算法的计算量,但是增加了一个额外的预测层,MAP相比于原始的算法提升了2.8%,额外检测层增加了对小目标的检测能力。B组实验在A组实验的基础上,替换了原始YOLOv5s算法的特征融合网络使用了BiFPN,模型的MAP比A组实验提升了0.6%,BiFPN可以更好地处理多尺度目标检测问题,同时提高检测精度。C组实验在前两组实验的基础上增加了CA模块,MAP相比C组实验提升了0.3%。D组实验在C组实验的基础上修改了损失函数,实验表明:该改进方法比C组方案的MAP提升了0.6%。
总体来讲,每项算法的优化对最终的结果都是正向促进作用,4项算法的组合改动同时应用使该算法的MAP达到最优。
-
为评估在FLIR数据集上的性能,本文中对当前主流的一阶段和二阶段网络模型进行了训练和测试。全面考虑了精确度P、召回率R、MAP、模型参数量、模型大小、模型计算量(亿浮点计算数)(billion floating point operation, BFLOP)以及检测速率等指标,以验证不同模型的可行性。实验结果如表 3所示,选用了faster R-CNN、SSD、YOLOv3-tiny、YOLOv4、YOLOv5s、YOLOv5s-p2和本文作者改进的YOLOv5s进行对比实验。faster R-CNN是最为典型的两阶段目标检测模型,在对比实验中无论是参数量还是计算量都是最多的,MAP高于SSD、YOLOv3-tiny和YOLOv4。由于SSD对小目标的检测效果并不理想,MAP并不是很高,同时参数量和计算量也很高。YOLOv3-tiny是上述实验中单张检测速度最快的,在NVIDIA RTX 3090上检测速率是205 frame/s,但是模型的MAP是最低的。改进YOLOv5s模型的MAP比YOLOv3-tiny高26.4%。如表 3所示,相比于原始的YOLOv5s以及添加了额外的小目标预测层的YOLOv5s-p2,虽然改进YOLOv5s的检测速度和计算量有所损失,但其MAP分别提升了4.2%和3.4%。改进的YOLOv5s权衡了模型的检测速度、参数量和计算量,提高了模型MAP,为其在嵌入式设备上部署提供了可能性。
model P/% R/% MAP/% parameter/106 size/Mbyte speed/(frame·s-1) BFLOP faster R-CNN 63.9 53.7 80.4 99.2 330.6 33 440.3 SSD 71.8 34.7 71.8 91.7 182.2 64 190.7 YOLOv3-tiny 72.1 52.4 58.9 8.6 17.4 205 12.9 YOLOv4 79.3 66.5 74.9 9.1 18.7 101 20.6 YOLOv5s 82.6 71.0 81.1 7.0 14.4 116 15.8 YOLOv5s-p2 85.3 72.8 81.9 7.1 15.5 113 18.6 our 86.9 74.4 85.3 7.2 15.8 106 19.0 Table 3. Comparison of detection performance of different models
为了评估改进后的YOLOv5s在小目标检测方面的性能,本文中按目标尺度划分数据集为小、中、大3类。小目标被定义为像素小于32 pixel×32 pixel的目标,大目标则为尺寸大于96 pixel×96 pixel的目标,而介于两者之间的目标被归为中目标。这分类策略有助于细致地检验模型在不同尺度目标上的表现。表 4中的实验结果验证了在添加额外的预测层、修改特征融合网络以及替换原始的损失函数后模型对于FLIR数据集中的小目标检测能力。从表 4可以看出,改进后模型相对于原始模型对小、中、大目标的MAP分别提高了8.5%、1.1%和0.8%,其中小目标的检测指标增幅最大,达到8.5%。
model MAP/% small medium large YOLOv5s 71.3 95.2 94.4 our method 79.8 96.3 95.2 Table 4. Comparison of detection indicators of different sizes
图 5是红外目标在4个不同的场景下的检测效果。由图 5a和图 5b的场景可以看出,改进后的模型能够检测出红外图像道路中小目标的行人目标;根据图 5c和图 5d检测效果图可以看出,当图像中的行人目标出现重叠、目标紧密连接或者车辆目标的特征信息不强时,原始模型会出现错检漏检的情况,而经过改进的YOLOv5s对遮挡目标以及尺寸小的目标都能很好地预测出它在图像中的位置,并准确分类出其类别,达到了在红外场景下进行准确的目标检测需求。

Figure 5. Comparison of YOLOv5s and improved YOLOv5s detection results
3.1. 实验平台与参数
3.2. 数据集
3.3. 评估指标
3.4. 相融实验
3.5. 不同目标检测算法的结果比较

-
本文作者针对红外图像特征少、尺度变化大的问题[21],提出了一种改进的YOLOv5s网络。首先增加了用于小目标的额外检测层,用于提高模型对红外小目标的检测能力;在主干网络增加了CA机制模块,让模型更好地关注重要的特征,抑制一些无关紧要的通道;然后使用BiFPBN替换原始YOLOv5s中使用的特征融合网络,减少冗余计算,大大提升模型的计算效率;最后使用了focal-EIOU损失函数。改进后的模型在红外图像数据集上测试,MAP相比于faster R-CNN、SSD、YOLOv5s以及YOLOv5s-p2分别提高了4.9%、13.5%、4.2%和3.4%。本文作者提出的红外目标检测算法,具有较强的实用价值和鲁棒性。
 DownLoad:
DownLoad: