 网站地图
网站地图



-
内蒙古大草原作为最佳天然牧场之一,是我国草地分布最广的地区。但是由于牧区缺乏高效的羊群计数的方法,因此相关部门不能对放牧强度作出监管和指导,导致过度放牧。高效的羊群计数方法同时能提高牧民在养殖过程中的工作效率。
近年来研究人员提出了一些有关羊群计数任务的方法。例如传统的基于你只需一次运算(you only look once, YOLO)监测的方法[1],这种方法需要提取整张图片的特征,然后进行卷积运算和非极大值抑制处理,得到图片中羊的位置,最终计算出输入图片中羊的数量。这种方法虽然能对羊群进行计数,但是需要检测并框出图片中的每一只羊,因此当羊的密度较大时,由于羊群之间相互遮挡比较严重,所以计数效果较差。ZHANG等人提出了一种基于单片机和射频识别(radio frequency identification, RFID)技术的智能数羊器系统[2],该方法首先给每一只羊的耳朵打耳标,然后通过RFID模块对其进行计数,这种方法只适合在羊群入圈和出圈时使用,限制了羊群计数的场地。如果想对羊群进行计数, 必须设有一个让羊有序通过的通道,在羊有序通过的过程中由RFID模块进行计数。但由于通道中能同时通过的羊群是有限的,因此不能快速且高效地对羊群进行计数。
针对目标计数的传统方法有基于监测目标整体的方法[3],该类方法使用支持向量机、提升和随机森林等多种分类器结合哈尔小波[4]、方向梯度直方图(histogram of gradient, HOG)、小边[5]等特征,使得这种方法在行人、车辆计数等方面进行了初步的应用。后来学者提出了基于部分监测的方法来提高计数的准确度,这类方法主要通过检测目标的部分结构例如人的头部和肩部[6]来进行计数,无论是哪种基于检测的方法都无法规避目标之间相互遮挡的问题,研究人员提出了基于回归的方法[7-8],该类方法首先提取低级特征,然后利用回归模型学习低级特征与人群个数的映射关系,由于不需要检测每一个目标个体,因此与基于检测的方法相比较,计数准确率显著地提高。
近年来,在计算机视觉领域中,卷积神经网络表现出了巨大的优势,研究人员开始尝试在人群计数任务中使用卷积神经网络对高密度场景的人群进行计数[9-10]。ZHANG等人提出了一种带有不同尺度卷积核的多列卷积来应对密度差异的变化[11]。WU等人提出了具有不同感受野的两条平行体系结构[12],并在公开的数据集上取得了较好的结果。OORO-RUBIO等人使用金字塔图像来提取多个尺度的密度特征[13]。为了避免景深和遮挡的干扰,LEI提出了一种多模型融合的人群计数算法,并在人群计数任务方面取得了较好的效果[14]。TANG等人针对复杂开放环境下人群密度估计中的多尺度目标和小目标感知问题, 提出了一种基于特征图融合的多列卷积神经网络的人群密度估计算法[15]。WANG等人提出了一种带有注意力图的两分支融合模型,用于解决人群计数中比例尺度变化和复杂背景的问题[16]。WANG等人提出了一种上下文学习网络用于对高密度人群进行计数[17]。为了让模型适应不同人群密度的场景,WU等人提出了一种自适应场景发现框架,用于对密度不同的人群进行计数[18]。
使用卷积神经网络的方法在高密度人群计数任务中已经取得了理想的效果。但针对草原上羊群计数的任务,目前还没有相关报道。于是作者提出了一种基于视觉几何群(visual geometry group, VGG)16与空洞卷积(dialated convolution, DC)相结合的卷积神经网络(VGG-16+DC net, VDNet)的羊群计数算法来满足牧民和相关部门的需要。将无人机拍摄的无固定分辨率的彩色图片送入模型,生成对应的羊群分布图,然后对密度图进行像素积分得出图片中羊群的数量,此方法不需要像传统羊群计数方法一样检测并框出图片中的每一只羊,因此在高密度场景下提升了计数准确度。经过实验验证平均准确率为93%。
-
采用大疆御2Mavic2Pro无人机,在内蒙古锡林郭勒盟苏尼特左旗草原采集羊群视频,同时在互联网中爬取羊群图片做为数据来源。
数据预处理:先人工筛选无人机拍摄回来的羊群视频。再将视频裁剪成一张张的图片,并人工挑选适合标注的图片。然后用Python脚本将图片统一规范命名。最后将处理好的图片分成测试集、训练集,并进行人工标注。
采用MATLAB工具对羊群数据集进行手工标注,由于羊之间相互遮挡,在大多数时候看不到所有羊的头部,所以标注羊身体的中心位置。标注过程如图 1所示。羊中心带有红色"+"号表示已经被人工标注。

Figure 1. Picture annotaion
-
标注过程中只标注了每只羊的一个点, 但是直接使用标注的某个点作为训练标签进行训练非常困难,预测结果很差。由于在拥挤的场景中,每只羊的大小通常与相邻k只羊的中心距离有关,所以根据每只羊与其相邻的k只羊的平均距离来自适应地确定每只羊的传播参量, 采用高斯核回归的方式生成最终的训练标签。
采用几何自适应高斯核的方法来生成密度图[11]。假设在输入的图片中像素点xi处有一只羊,用δ(x-xi)来表示那只羊,则输入图片中的N只羊可用下式表示:
$ H(x) = \sum\limits_{i = 1}^N \delta \left( {x - {x_i}} \right) $
(1) 为了生成密度图F(x),用带有参量σi的高斯核滤波器函数Gσi(x)和H(x)做卷积:
$ F(x) = H(x) \times {G_{{\sigma _i}}}(x) $
(2) $ {G_{{\sigma _i}}}(x) = \frac{1}{{\sqrt {2{\rm{ \mathsf{ π} }}{\sigma _i}} }}\exp \left( { - \frac{{{x^2}}}{{2\sigma _i^2}}} \right) $
(3) 式中,σi=βdi, di表示xi处那只羊的中心位置与k只相邻羊中心位置的平均距离。在实验中,经验系数β设置为0.3、k选取3为最佳。
-
2维空洞卷积的定义如下[19]:
$ y(m, n) = \sum\limits_{i = 1}^M {\sum\limits_{j = 1}^N x } (m + r \times j, n + r \times j)w(i, j) $
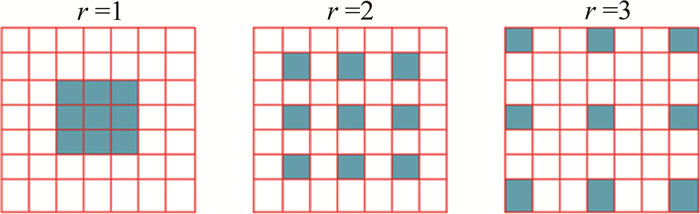
(4) 式中, r表示空洞率,w(i, j)是过滤器,x(m, n)是长和宽分别为m和n的输入图像的信息。空洞卷积能将k×k的卷积核扩张成为k+(k-1)(r-1)的卷积核,根据公式可知,当r=1时, 卷积核大小不变,相当于一个普通的卷积核; 当r=2时, 3×3卷积核被扩大为5×5;当r=3时, 3×3的卷积核被扩大为7×7。图 2中显示了3×3的卷积核,在r为1, 2, 3时的情况。
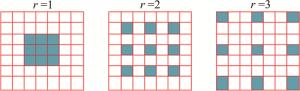
Figure 2. Dilated convolution
虽然传统的池化层(例如最大池化)常常用来保持不变性和控制过拟合,但是池化层的引入降低了空间分辨率,会导致丢失特征图的一些空间信息。而反卷积操作可以减少空间信息的丢失,但是会导致执行延迟和增加网络的复杂性。空洞卷积利用扩张后这种稀疏的卷积核在保持分辨率的同时扩大了感受野,代替池化操作,更加适合用来为高密度的羊群生成密度图。
-
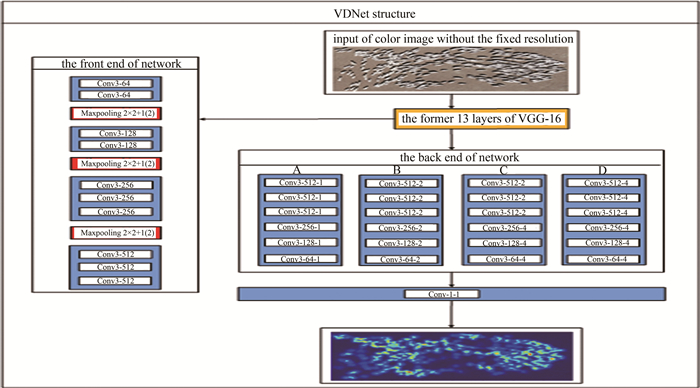
整个网络分为前端和后端两个部分,输入为任意尺寸大小的原始彩色羊群图片,经过网络的前端和后端,最后用1×1的卷积层形成密度图。
前端采用去除了全连接层的VGG-16[20]网络提取2-D特征,为了平衡准确性和资源开销,采用3层池化和10层卷积。前端网络全部采用3×3的卷积核,最大池化层的大小为2×2,步长为2,前端输出大小是原始输入大小的1/8,如果继续使用更多的卷积和池化操作,输出图像将进一步缩小,这将增加生成密度图的难度。所以本文中采用空洞卷积作为后端网络,空洞卷积能够在保持分辨率不变的同时扩大感受野,更加适合生成高质量的羊群分布密度图。由于VGG-16与空洞卷积相结合的网络(VDNet)输出的密度图是原始输入图像的1/8,因此选择倍数为8的双线性插值对图像进行缩放,确保模型的输出图像与输入图像具有相同的分辨率。VDNet网络结构如图 3所示。网络后端卷积层的参量依次表示为"卷积核大小-卷积核数量-空洞率"。

Figure 3. Network structure
-
本次实验中所采用的服务器操作系统为Ubuntu16.04,中央处理器为RTX 2080 Ti,采用MATLAB 2018a作为手动标注羊群数据集的工具,使用的Python版本为3.6,0.4.0 Pytorch版本框架,采用的CUDA版本为CUDA9.2 cuDNN7.4.1。
制作的数据集包括1400张羊群图片。其中有200张图片来自互联网,1200张图片来自锡林郭勒盟苏尼特左旗草原,单张图片羊的数量范围从10只~380只,经过人工标注后,使用随机算法随机给训练集分配840张,测试集分配560张。
-
将整个网络作为端到端的结构进行训练,模型的前13层使用训练好的VGG-16的参量进行初始化,其它各层使用标准差为0.01的高斯分布初始化,学习率为0.00006,优化算法为随机梯度下降, 并采用欧氏距离来计算图片中羊群真实数量与预测的密度图之间的距离。损失函数定义如下:
$ L(\theta ) = \frac{1}{{2N}}\sum\limits_{i = 1}^N {\left\| {Z\left( {{X_i}:\theta } \right) - Z{'_i}} \right\|_2^2} $
(5) 式中,‖·‖代表范数,N表示训练图像的总数量,Xi是第i张羊群图像,θ是权值参量,Z(Xi∶ θ)表示第i张图像的估计密度,Z′i表示第i张图像的真实密度。
研究人员都采用均方误差(mean square error,MSE)和平均绝对误差(mean absolute error,MAE)[21]来评估模型的性能。MSE表示模型的鲁棒性,MSE越小表示鲁棒性越高; MAE能反映出预测值的误差情况,MAE值越小准确度越高。
$ {E_{{\rm{MAE}}}} = \frac{1}{N}\sum\limits_{i = 1}^N {\left| {{C_i} - C{'_i}} \right|} $
(6) $ {E_{{\rm{MSE}}}} = \sqrt {\frac{1}{N}\sum\limits_{i = 1}^N {{{\left| {{C_i} - C{'_i}} \right|}^2}} } $
(7) 式中, Ci代表图片中羊的预测数量, C′i代表图片中羊的真实数量。Ci的值由下式计算:
$ {C_i} = \sum\limits_{l = 1}^L {\sum\limits_{w = 1}^W {{Z_{l, \omega }}} } $
(8) 式中,L表示密度图的长,W表示密度图的宽,Zl, w表示密度图在(l, w)处的像素点。
-
经过实验,作者的方法在此数据集上的MAE为2.51,MSE为3.74。图 4和图 5中提供了8组在不同密度区间羊群图片的实验结果。其中a列为输入的原始图像,b列为VDNet生成的密度图以及对生成的密度图像素积分后得出的羊群数量,c列为根据图片中羊的真实位置生成的真实羊群密度图及对密度图积分后羊的真实数量。图中横纵坐标仅表示2维图像中的间隔和范围,无具体单位。可以看出, 本文中的网络结构能够较为准确地反映输入图片中羊群的分布情况。

Figure 4. Experimental result from thm first image to the forth image

Figure 5. Experimental result from the fifth image of the eighth image
将本文中的方法与现有的人群计数方法进行对比。从表 1中可以看出,本文中提出的方法在羊群计数任务上取得了更好的实验结果。
Table 1. Experimental comparison
method MAE MSE old method 10.05 13.37 the method in this paper 2.51 3.74 -
为了更好地满足牧民和相关部门对羊群计数任务的需求,引入了空洞卷积对高密度羊群进行计数。网络的前端采用VGG-16的前13层,后端采用6层的空洞卷积,最后一层使用1×1的卷积层进行卷积输出密度图。此方法不需要像传统基于YOLO的羊群计数方法一样检测图片中的每一只羊,避免了羊群之间相互遮挡带来的计数准确率下降的问题。经过实验验证,本文中计数的方法平均绝对误差为2.51,均方误差为3.74,平均准确率为93%。
基于VDNet卷积神经网络的羊群计数
Herd counting based on VDNet convolutional neural network
-
摘要: 为了避免传统羊群计数任务中,羊只之间相互遮挡带来的干扰,提高羊群计数的准确度,采用了视觉几何群(VGG-16)与空洞卷积(DC)相结合的VDNet神经网络羊群计数方法。该方法在网络前端采用去除了全连接层的VGG-16网络提取2-D特征,后端采用6层具有不同空洞率的DC提取更多的高级特征;DC在保持分辨率不变的同时扩大了感受野,替代池化操作,降低了网络的复杂性;最后用一层卷积核大小为1×1的卷积层输出高质量的密度图,通过对密度图像素积分得出输入图片中羊的数量,并进行了理论分析和实验验证。结果表明,VDNet的平均绝对误差为2.51,均方误差为3.74,平均准确率为93%。这一结果对羊群计数任务是有帮助的。Abstract: In order to avoid the interference of mutual occlusion between sheep in the traditional flock counting task and improve the accuracy of flock counting, the VDNet(VGG-16+DC net) convolutional neural network flock counting method, combining visual geometry group(VGG) 16 and dialated convolution (DC) net, was adopted. VGG-16 with the fully connected layer removed was used at the front end of the network to extract 2-D features, 6 layers of DC with different dilated rates was used to extract more advanced features. DC expanded the receptive field, replaced the pooling operation, and decreased the complexity of the network while kept the resolution unchanged at the same time. The theoretical analysis and experimental verification were carried out. Finally, a convolutional layer with a convolution kernel size of 1×1 was used to output a high-quality density map, and then the number of sheep in the input image was obtained by integrating the pixels of the density map. The results show that the average absolute error of the counting method in this paper is 2.51, the mean square error is 3.74, and the average accuracy is 93%, respectively. This result is helpful for the task of counting sheep.
-
Key words:
- image processing /
- sheep count /
- dilated convolution /
- convolutional neural network
-
Figure 4. Experimental result from thm first image to the forth image
a—orginal image b—VDNet output result c—truth density map
Figure 5. Experimental result from the fifth image of the eighth image
a—orginal image b—VDNet output result c—truth density map
Table 1. Experimental comparison
method MAE MSE old method 10.05 13.37 the method in this paper 2.51 3.74  下载: 导出CSV
下载: 导出CSV
-
[1] TIAN L. Design of sheep number detection system[D]. Hohhot: Inner Mongolia University, 2019: 45-57(in Chinese). [2] ZHANG L, XU J, TIAN Z, et al. Research and implementation of intelligent counting sheep system in pastoral areas[J]. Telecom Power Technologies, 2017, 34(4): 165-166(in Chinese). [3] ENZWEILER M, GAVRILA D, GAVRILA D M. Monocular pedestrian detection: Survey and experiments[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2009, 31(12): 2179-2195. doi: 10.1109/TPAMI.2008.260 [4] JONES M J, SNOW D. Pedestrian detection using boosted features over many frames[C]// International Conference on Pattern Recognition. New York, USA: IEEE, 2008: 8-11. [5] WU B, NEVATIA R. Detection and tracking of multiple, partially occluded humans by bayesian combination of edgelet based part detectors[J]. International Journal of Computer Vision, 2007, 75(2): 247-266. [6] FELZENSZWALB P F, GIRSHICK R B, McALLESTER D, et al. Object detection with discriminatively trained part-based models[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2010, 32(9): 1627-1645. doi: 10.1109/TPAMI.2009.167 [7] LIU T, TAO D. On the robustness and generalization of cauchy regression[C]// 2014 4th IEEE International Conference on Information Science and Technology (ICIST). New York, USA: IEEE, 2014: 32-37. [8] ZHAI J Y, TU L Zh, ZHUANG Y. Saliency detection based on boundary prior and adaptive region merging[J]. Computer Engineering and Applications, 2018, 54(6): 178-182(in Chinese). [9] ZENG L, XU X, CAI B, et al. Multi-scale convolutional neural networks for crowd counting[C]// 2017 IEEE International Conference on Image Processing (ICIP). New York, USA: IEEE, 2017: 89-91. [10] HUANG S Y, LI X, CHENG Zh Q, et al. Stacked pooling: Improving crowd counting by boosting scale invariance[J]. Computer Vision and Pattern Recognition, 2018(22): 46-52. [11] ZHANG Y, ZHOU D, CHEN S, et al. Single-image crowd counting via multi-column convolutional neural network[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York, USA: IEEE, 2016: 98-103. [12] WU X, ZHENG Y, YE H, et al. Adaptive scenario discovery for crowd counting[J]. Computer Vision and Pattern Recognition, 2019(9): 12-16. [13] OORO-RUBIO D, LÓPEZ-SASTRE R J. Towards perspective-free object counting with deep learning[C]// European Conference on Computer Vision(ECCV) 2016. New York, USA: IEEE, 2016: 56-64. [14] LEI H L. Crowd counting algorithm based on multi model deep convolution network fusion[D]. Hohhot: Inner Mongolia University, 2020: 32-37(in Chinese). [15] TANG S Y, TAO Y, ZHANG L L, et al. A deep crowd counting algorithm based on multi-column feature map fusion. Journal of Zhengzhou University (Natural Science Edition), 2018, 50(2): 69-74(in Chinese). [16] WANG Y J, ZHANG W, LIU Y Y, et al. Two-branch fusion network with attention map for crowd counting[J]. Neurocomputing, 2020, 411: 1-8. doi: 10.1016/j.neucom.2020.06.034 [17] WANG S, LU Y, ZHOU T, et al. SCLNet: Spatial context learning network for congested crowd counting[J]. Neurocomputing, 2020, 404: 227-239. doi: 10.1016/j.neucom.2020.04.139 [18] WU X, ZHENG Y, YE H, et al. Counting crowds with varying densities via adaptive scenario discovery framework[J]. Neurocomputing. 2020, 397: 127-138. doi: 10.1016/j.neucom.2020.02.045 [19] LI Y, ZHANG X, CHEN D. CSRNet: Dilated convolutional neural networks for understanding the highly congested scenes[J]. Computer Vision and Pattern Recognition, 2018 (27): 31-39. [20] SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[J]. Computer Vision and Pattern Recognition, 2014(4): 19-25. [21] ZHANG C, LI H, WANG X, et al. Cross-scene crowd counting via deep convolutional neural networks[C]// 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York, USA: IEEE, 2015: 17-29. -
 点击查看大图
点击查看大图

图(5) / 表(1)
计量
- 文章访问数: 4176
- HTML全文浏览量: 3156
- PDF下载量: 22
- 被引次数: 0
