 Map
Map


HTML
-
遥感影像分类[1-2]是遥感领域不可或缺的一部分,被广泛应用在土地资源管理、城市设计规划、气象观测、环境及自然灾害的变化监测等领域。为了反映地面复杂的空间结构,需要充分利用遥感图像中的丰富地理信息,但目前从遥感图像中精确提取有效信息并适度表达, 还面临诸多挑战[3]。
图像分类任务中如何提取图片特征至关重要,而且对于实验结果的影响不容忽略。中低层次上的方法提取图像语义特征,如视觉词袋模型(bag of visual words,BOVW)[4],在此基础上出现众多基于视觉词袋的模型,如改进的同心圆多尺度结构视觉词袋(concentric circle-structured multi-scale BOVW,CCM-BOVW)[5]模型,该模型利用特征组合描述视觉词的空间信息,但特征表达能力较弱,影响分类精度;共线性核以一种空间金字塔形式(spatial pyramid co-occurrence kernel,SPCK)[6],通过捕获单词的绝对和相对空间排列表征图像的光度和几何特征,但采用的是底层局部特征导致其分类结果不佳。大多数经典方法是基于人工或浅层学习的算法,而且提取的中低级语义特征在描述能力上受到限制,难以进一步提高分类准确性。
近些年,深度学习方法作为计算机视觉识别领域的主要方法已成功应用于目标识别,取得巨大成功,如空间卷积的显著性方法[7]检测物体、捷径卷积神经网络[8]识别人脸、改进马尔可夫模型[9]分割合成孔径雷达(synthetic aperture radar,SAR)图像,以及深度学习的方式用于遥感图像分类[10]等。但是,训练卷积神经网络(convolutional neural networks,CNN)处理图像分类任务时,大规模标签数据是前提。由于图像本身的信息较复杂,导致目前单一标签的图像数据较少,而人工标注又耗时间和精力,因此成为图像分类精度的一个影响因素。在此基础上,卷积神经网络及其一系列改进[11-12]用于解决上述问题,将多尺度图像[13]送到输入端,产生图像的丰富特征信息,然后用多种编码方式对特征编码,最后输入分类器分类。利用联合显著性算法与卷积神经网络结合的方法[14]对遥感图像采样,对于图像场景差异小的类别识别效率低。将微调和卷积神经网络模型结合提取图像特征[15]的方法有效解决了遥感图像场景分类的相同类内差异和不同类间相似性的问题,但同时局部信息的表达被减弱。LI等人[16]提出一种多尺度费舍尔编码方法来构建卷积深度特征的中层特征表示,通过主成分分析方法融合了从卷积层中提取的中层特征和全连通层的特征,但该方法着重于中层特征的表达,没有利用更高层次的特征。
为充分利用图像中包含的丰富场景信息,本文中提出一种用双通道深度密集网络提取特征并融合的分类方法。首先,改变深层密集卷积神经网络(dense convolutional network,DenseNet)的DenseNet-40网络结构,使其适应原遥感图像尺度大小,其次通过改进的DenseNet-40表征遥感图像的全局信息,原DenseNet-40表征遥感图像的局部信息,然后利用BOVW模型对深层局部特征进行重组编码,最后,利用局部特征和全局特征的互补性,将密集网络的各层特征加权融合,使融合后特征带有更深层次语义信息,利于改善分类准确率。
-
HUANG等人[17]联合提出的一种深层密集卷积神经网络DenseNet,其网络核心机制与残差网络(residual network,ResNet)相同,但DenseNet把网络中相邻两卷积层密集连接起来,即通过各卷积层特征在每个通道上的密集连接实现特征高效复用。上述特点使DenseNet既能够减少训练的参量,又有效改善了网络训练费时费力的问题。
DenseNet密集连接方式的前提是特征图尺寸相同。因此网络中采用密集块(dense block, DB)加过渡层(transition layer, TL)重复使用的结构。密集块每个层的特征层尺寸保持一致,内部的瓶颈层(bottleneck layer, BL)使计算量大大减少,分别有批次归一化(batch normalization,BN)、修正线性单元(rectified li-near unit,ReLU)和卷积层三部分,如图 1所示。而过渡层在相邻两个密集块之间起连接作用,并经池化降低特征图尺寸。此结构有效解决了梯度消失带来的影响。此外,DenseNet具有抑制过拟合的正则化效应。
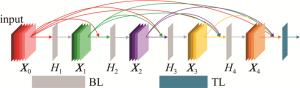
Figure 1. Dense block structure
设某卷积神经网络共有l层,传统CNN的第l层输入为其前一层的输出,计算公式为:
式中, Xl是第l层的输出,Hl()为第l个卷积中的复杂线性变换操作。不同的是,DenseNet中该层的输入为0~(l-1)层的输出特征图,计算公式为:
每个密集块经前面的卷积后得到特征图的数目一致,表示为k,k为一个超参量。一般情况下k取较小时可得到较好的结果。若取输入特征图个数为k0,则输入特征图的数量会随复合卷积的层数呈线性增加的状态。输入特征图的数量m计算公式为:
-
本文中选用通道一网络,即DenseNet-40网络提取图像的局部特征,用BOVW对末尾卷积层特征编码,得到低维词频分布直方图,从而降低特征维度,表达出图像的局部特征。在卷积中,特征图是由卷积层和卷积核进行卷积之后的结果,因此抽取卷积后的众多特征图上相同位置的元素,并将这些元素排列,可得到输入图像不同的局部抽象特征的表达,如图 2所示。假设第l层卷积层的输出特征图为dl×nl×nl,nl×nl表示单个特征图大小,dl表示特征图数目,fl, k为经卷积层l得到的第k(1≤k≤dl)个特征图,该图的某个元素(i行j列)为fl, k(i, j)(1≤i≤nl, 1≤j≤nl),则该卷积层的全部特征图在此位置的元素重组后,可获取一个新的特征向量,计算公式为:

Figure 2. Feature reorganization
式中, fPReLu表示激活函数,fl(i, j)表示dl维列向量。
本文中所用框架中有大量的训练参量,这意味着训练时间长,并且有过度训练的倾向。为了使训练更快并防止过度拟合,选择参量修正线性单元(parame-tric rectified linear unit,PReLU)作为激活函数[18],它在ReLU的基础上引入了极少数的参量,公式表示为:
式中, xi是第i个通道上非线性激活的输入,i是可学习的参量,ai用于确定负部分的斜率。更新i时,PReLU采用动量法,公式表示为:
式中, μ表示动量,lr表示学习率。因为i可能趋于0,因此i在更新状态下,考虑弃用权重衰减。ai=0.25用作初始值。尽管ReLU是一种有用的非线性函数,但它阻碍了反向传播,而PReLU使模型更快地收敛。
视觉词典可以实现将所获取的视觉词汇从高维降至低维,依据生成的视觉词典对视觉单词进行编码,编码后即表示出了图像中包含的信息。具体编码过程如下:计算某一任取视觉词汇与视觉词典中所有视觉单词的距离,并从结果中找到一个最小值,记录产生该距离最小值的视觉单词,代替当前的词汇,记录各视觉单词在其总数中所占比例,即生成其词频分布直方图。
-
算法设计的扩展DenseNet-40网络实现了对遥感图像全局信息的表征。由于一些含区分性的信息会存在于网络的某些层中,扩展DenseNet-40的全连接层(fully connected layers,FC)可以将这些局部信息整合,整合后的输出可用一个N维特征向量表示,即由N个1×1的特征图组成,公式表示为:
假设第l层卷积层的输出特征图为dl×nl×nl,nl×nl表示单个特征图大小,dl表示特征图数目,Y∈RN×1×1为输出特征向量,R表示实数域,N表示经全连接层整合后的特征图个数,X∈Rdl×nl×nl为输入特征图,W∈R(dl×nl×nl)×N为权重,b∈RdFC为偏置项,dFC表示全连接层的特征图个数。
-
整体算法结构如图 3所示。网络设计为以DenseNet为中心的双通道网络,分别将两种不同尺度的图像作为输入,捕获更全面的图像特征。预处理是通过将图像样本进行直方图均衡化,尺度变换和数据集的划分等操作,以节省训练时间同时去除图像的冗余信息。经过图像预处理操作后,得到两组图像集,分别是大小为32pixel×32pixel尺寸的图像集和大小为256pixel×256pixel尺寸的图像集,最后将图像集随机分为8:2的训练集和测试集,待双通道网络训练完成后,将网络最后提取的局部和全局特征进行线性加权融合,最后经softmax分类器分类输出结果。

Figure 3. Algorithm structure
具体步骤如下:(1)图像样本经预处理操作后获得尺寸分别为32pixel×32pixel和256pixel×256pixel的图像集,并随机将其划分为8:2,分别作为训练集和数据集;(2)将划分后的图像训练集输入通道1的DenseNet-40网络进行训练,各个DB模块均采用k=24,卷积层的数量为12,由于提取的局部和全局特征的维度不同,在经过DenseNet-40获取卷积层特征后,对这些特征重组并通过词袋模型编码,得到局部信息的分布直方图;同时输入通道2的扩展DenseNet-40网络进行训练,提取全局特征;(3)将上一步中的两部分特征矩阵以线性加权方式进行融合,得到融合特征矩阵;(4)融合特征矩阵经softmax分类器,得出验证结果,进行模型评估;(5)模型评估完成后用先前划分的测试集进行测试,得到最终分类结果。
1.1. 密集网络
1.2. 局部特征提取

1.3. 全局特征提取
1.4. 基于双通道深度密集特征融合算法

-
选取第1个公开数据集是UC Merced Land-Use,该数据集每一类分别有100张角度不同的遥感图片,共21类,图片总数量为2100张,每张大小为256pixel×256pixel,空间分辨率为0.3m/pixel,部分类别图像样本如图 4所示。样本均随机选取情况下,将该数据集中每类的80%当作训练集,其余20%当作测试集。

Figure 4. UC Merced Land-Use dataset image sample display
选取第2个公开数据集是NWPU-RESISC45,该数据集有沙漠、海港、岛屿等共45类场景,每类场景有700张遥感图片,每张图片大小为256pixel×256pixel,图片总数量为31500张,该数据集是由一些人从已有的常用数据集中挑选、组合而成的新数据集,大多数图像的空间分辨率在0.2m/pixel~30m/pixel,部分类别图像样本如图 5所示。该数据集上同样随机选取测试集和训练集为8:2的比例进行实验。

Figure 5. NWPU dataset image sample display
-
本文中的实验均是基于深度学习框架软件TENSORFLOW1.9的基础上完成,所用服务器硬件配置为DGX-1服务器,内含8块NVLink V100 GPU,每块32GB显存,共256GB,本地固态硬盘为7TB的固态驱动器(solid state disk,SSD),当采用深度学习方法或对计算性能要求较高时,一般应用该设备;实验操作系统为Linux4.15.0 -47-generic x86_64。
由于实验中所用数据集输入图片大小均为256pixel×256pixel,图片尺寸相对较大,因此在提取全局特征时需对密集网络进行扩展,网络详细参量设置信息见表 1。算法学习率为0.001,批量大小为20。将图片输入网络后,经第1次卷积(采用same方式),使输出与输入大小一致,保留了图像的边界信息;第1个池化方式采用最大池化,目的是减小偏移误差,解决了原始遥感图像部分纹理信息丢失的问题。
layers input size/pixel kernel size number of convolution kernels pool stride output size/pixel input convolution 256×256 3×3 72 — — 256×256 max pooling 256×256 1×1 — 2×2 2 128×128 dense block 1 128×128 3×3 360 — — 128×128 transition layer 1 128×128 1×1 360 2×2 2 64×64 dense block 2 64×64 3×3 648 — — 64×64 transition layer 2 64×64 1×1 648 2×2 2 32×32 dense block 3 32×32 3×3 936 — — 32×32 transition layer 3 32×32 1×1 936 2×2 2 16×16 dense block 4 16×16 3×3 1224 16×16 transition layer 4 16×16 1×1 1224 2×2 2 8×8 dense block 5 8×8 3×3 1512 — — 8×8 classification layer 1×1 1 1×1 Table 1. Extended DenseNet-40 structure
-
实验结果采用评价指标:分类准确率A、误分类率E和混淆矩阵。计算公式如下所示:
式中,T表示测试集中被正确分类的图片数;M表示测试集图像总数。
误分类率公式如下所示:
本文中方法在UC Merced Land-Use dataset上分类产生的混淆矩阵如图 6所示。由图中可看出, 场景中分类目标不单一,背景对象多导致分类精度较低;并且有些图像场景之间具有相似性,往往让网络认为是同一场景,如森林和中等密集住宅、中等密集住宅和密集住宅等;而对于场景单一、目标突出、特征明显的场景,分类精度较高,如茂密树丛、海港、跑道等。本文中的算法从整体来看分类效果较为理想,但很少数类别的分类结果未达到理想值,可能是场景之间的相似性,才导致误分率相对较高。
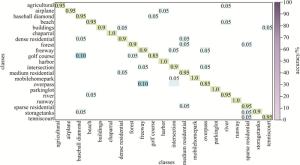
Figure 6. The confusion matrix obtained by our algorithm on the UC Merced Land-Use dataset
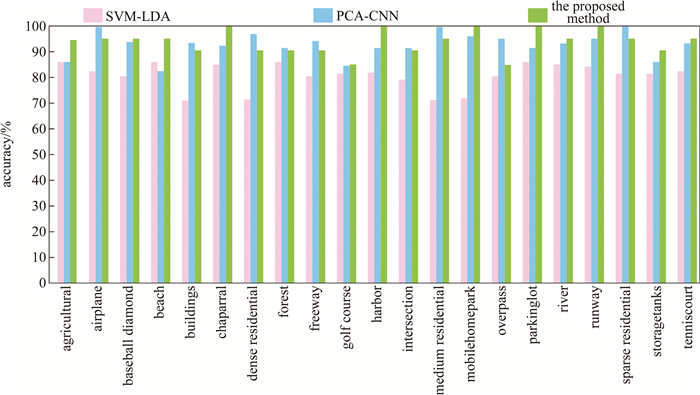
采用支持向量机(support vector machine, SVM)加文档主题生成模型(latent dirichlet allocation,LDA)的SVM-LDA[19]方法、包含空间信息的费舍尔核(Fisher kernel-spatial,FK-S)[20]方法、多尺度深度卷积神经网络(multi-scale deep convolutional neural network,MS-DCNN)[13]方法及主成分分析(principal components analysis,PCA)加CNN的PCA-CNN[14]方法与本文中的算法对比,在UC Merced Land-Use Data Set上的各个类别的分类精度如图 7所示。SVM-LDA[19]算法通过使用显着性检测,从图像数据集中的显着区域提取一组代表性图像块,用无监督的特征学习方法利用这些未标记的数据块,组成一个强大而高效的特征提取器。其中,最大池化的步长为1,稀疏值0.4;PCA-CNN[14]方法的阈值β=0.3,α=0.8,并且为每个图像随机选择100张大小为64×64×3的图像块。由图可知,算法SVM-LDA[19]的每一类分类结果均比其余两种算法低,而PCA-CNN[14]算法的整体分类结果较为平均,但其分类准确率低于本文中所提出的方法,证实了本算法的优势。

Figure 7. Scenes classification accuracy of three comparison methods on UC Merced Land-Use
为了分析不同尺度的遥感图像输入对分类结果的影响,取原图像(256pixel×256pixel)和压缩后(32pixel×32pixel)的图像尺寸作为输入图像,分类结果见表 2。由表 2可知, 前两组分类精度相对较低,因为输入单一尺度的图像时,仅能提取到部分的图像特征,从而特征利用率不高,导致分类结果较低。前两组实验对比来看,输入图像尺度为32pixel×32pixel时,图像信息被压缩,提取特征失真,导致分类结果偏低。第3组实验同时将两种尺度的图像输入,提取更加丰富的图像特征,分类效果较好。
input size accuracy/% UC Merced Land-Use NWPU-RE-SISC45 32pixel×32pixel 89.05 88.91 256pixel×256pixel 91.29 90.24 fusion network 93.81 92.62 Table 2. Impact of two different scale input images on classification accuracy
为了评价不同算法的分类效果,对两种数据集应用本文中方法与现有文献中其它方法的分类准确率见表 3,误分类率见表 4。由表可知,深度卷积神经网络在图像分类任务中有着不可替代的作用。传统方法中,提取的图像特征大多数属于中低层次的图像特征,而深度学习方法还能提取高层次的图像语义特征,高、中、低层次图像特征综合分析,比中低层图像特征更具有可分析性,因此采用深度学习的方法是当前的趋势,因此本文中采用双通道密集网络来提取图像特征,把图像信息各层次特征提取出来并高效复用,达到全面分析的效果,从而实现更优的分类结果。
Table 3. Classification accuracy of five methods for datasets experiments
2.1. 数据集介绍


2.2. 实验参量设置
2.3. 实验结果与分析

-
由于在图像识别ImageNet数据集上运用DenseNet有很好的分类效果,因此使用DenseNet网络设计双通道特征融合网络,利用网络中各层特征较强的表示能力,提取更多图片的特征,并且该网络特点是能保证高效的特征复用,因此提高了各层的特征利用率。为了增加保留图片的有用信息的同时去除冗余信息的能力,算法最初设计数据增强等预处理操作。从实验结果可知,该融合模型在两个数据集上表现出了良好的分类性能。后续研究中,可尝试引入多层特征融合的方法来提高目标的识别分类。
 DownLoad:
DownLoad: