 Map
Map


HTML
-
3维空间中光线强度的传输特性可以用光场来表征。1991年,ADELSON和BERGEN等人[1]根据人眼对外部光线的视觉感知情况,提出利用7维全光函数来表征空间光线强度分布。7维全光函数主要由空间中某点的3维坐标、光线传播方向、波长以及时间7个维度构成。但是如此高维的数据存在记录与处理的困难。因此,McMILLAN等人[2]对全光函数进行简化,提出用5维光场函数来表征任一时刻的自由空间光线。1996年,LEVOY[3]和GORTLER[4]又提出利用一组平行双平面来记录空间中光线的角度和位置信息,搭建了“双平面”表征模型,将5维光场函数进一步降维到4维光场函数。
基于4维光场理论以及现代光学成像技术的发展,多种光场成像系统被提出,例如光场相机阵列[5]、Lytro光场相机[6]以及Raytrix光场相机[7]等。其中,Lytro光场相机可以通过单次曝光获取3维场景中光线的位置与角度4维信息,打破了传统成像系统只能记录光线2维信息的瓶颈。同时,由于光线位置信息的引入,使得Lytro光场相机具有了“先拍照,后聚焦”的优势,促进了其在计算机视觉[8]各个层面上的广泛应用[9]。
为了使获取的光场图像满足高清需求,就需要大量的数据来表示光场图像。这使得光场图像的数据量远远高于传统的自然2-D图像,给光场图像的存储与传输带来了巨大的挑战。然而,光场图像的存储与传输又是光场成像技术应用发展的关键因素。因此,针对光场图像内容的压缩算法就显得尤为重要。
目前,针对光场图像的压缩编码算法大致可以分为两类:基于伪序列的压缩算法以及基于空间相关性的压缩算法。基于伪序列的编码算法[10-13]核心思想是将光场图像分解为多视点图像。然后将获取的多视点图像重组为一个视频序列,利用现有的视频编码标准[14]对其进行压缩编码。但是该类算法需要获取光场图像准确的几何信息,以便提取多视点图像。基于空间相关性压缩算法[15-19]的核心思想是利用光场图像中相邻子图像(micro-images, MIs)的强相关性来对光场图像进行压缩。虽然该类算法可以通过探索光场图像的自相关性来提升编码效率,但是很多压缩算法对于光场图像内容中的纹理复杂区域的预测精度并不高。此外,由于光场图像中包含3维场景的4维信息,可以从光场图像中提取出视点图像,且提取的视点图像之间同样存在较强的空间相关性。但是,很多算法并没有充分探索视点图像间的强相关性来提升光场图像编码效率。因此,本文中提出一种基于视点图像空间相关性的光场图像压缩算法。在充分利用提取视点图像之间的高空间相关性的同时,设计一种混合线性加权预测与帧内块拷贝(intra block copy, IBC)预测的预测算法,提升纹理复杂区域的预测精度,进而提高光场图像的编码效率。
-
光场图像由一组子图像阵列构成,包含了3维场景中光线的位置及角度信息。因此,可以从光场图像中绘制出视点图像。每一个视点图像表示3维场景光线在不同方向上的正交投影。绘制视点图像最简单的方式是在组成光场图像的每个子图像相同位置处提取一个像素点,然后拼接成一幅视点图像。然而,提取一个像素点绘制的视点图像面临两方面的问题:一是分辨率较低;二是绘制的视点图像块效应较为严重。这些问题均会削弱绘制视点图像之间的空间相关性。因此,本文中将采用在每个子图像相同位置处提取一个像素块的方式来绘制视点图像。绘制过程如图 1所示。假设从每个子图像相同位置提取一个P×P的像素块,子图像的个数为Nx×Ny,则绘制的视点图像的分辨率为P·Nx×P·Ny。通过改变提取像素块的位置,可以获取不同水平与垂直视角下的视点图像。当子图像中所有的像素块被提取后,可以获得一个视点图像阵列。
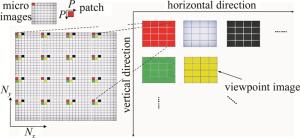
Figure 1. Process to construct viewpoint images
图 2中给出了Luara光场图像的原始光场图像数据以及绘制视点图像阵列数据的表示形式。从图 2中可以看出,绘制的视点图像之间存在较大的重叠区域,相邻的绘制视点之间视差较小。因此,绘制视点之间存在较强的相关性。这些相关性可以进一步用来提升光场图像的编码效率。为了能够探索绘制视点图像阵列的强相关性,本文中将绘制的视点图像阵列按照提取块在子图像中的位置进行拼接,组成视点阵列图。视点阵列图像并没有改变原始光场图像的信息,只是像素块的重新排列。因此,视点阵列图可以看作光场图像的等价表示形式。

Figure 2. The original light field image and the rendered view image array for Laura

-
为了能够充分利用视点阵列图强相关性来提升光场图像的编码效率,本文中提出一种混合线性加权与帧内块拷贝的编码块预测算法。该算法基于高清视频编码(high efficiency video coding,HEVC)屏幕编码扩展平台(screen content coding extension, SCC),将线性加权算法与帧内块拷贝算法利用率失真优化过程进行结合,进一步提高编码块的预测精度。
假设当前编码块像素值用列向量x0表示,与当前编码块相邻的厚度为T的像素块的像素值用列向量y0表示。本文中所提算法的主要目的就是利用已知的编码重建区域来获取当前编码块的最佳预测值。基于视点阵列图的强相关性,本文中首先在已知重建区域中相邻视点图中搜索得到当前编码块的K个最近邻像素块,然后利用线性加权算法得到当前编码块的最佳预测。针对线性加权算法在纹理复杂区域预测精度不高的问题,本文中提出利用帧内块拷贝的预测算法来提高纹理复杂区域的预测精度。
-
本文中所提的线性加权预测算法是利用当前编码块的K个最近邻像素块的线性加权值作为当前编码块的最佳预测值,主要包含两方面的问题:一是K个最近邻像素块的获取; 二是加权矢量系数的计算。
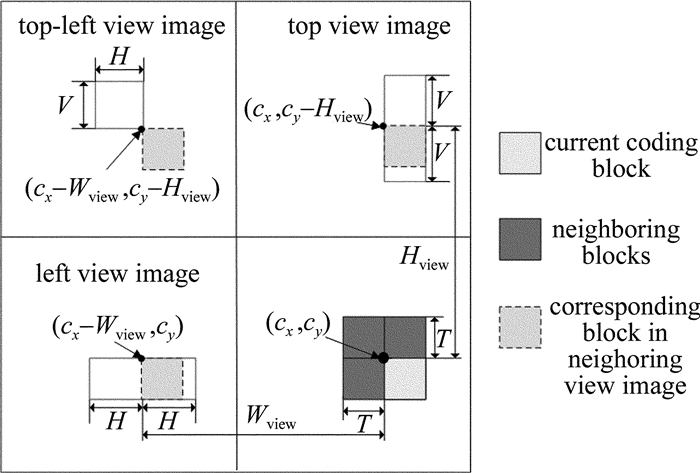
为了能够获取当前编码块的K个最近邻像素块,充分利用视点阵列图的强相关性,在重建区域与当前视点图相邻的视点图中进行匹配搜索。由于当前编码块是未知的,利用与当前编码块相邻的厚度为T的像素块,以欧氏距离作为匹配准则进行搜索。搜索过程中首先获得矢量y0的K个最近邻像素块,然后根据相应的位置关系获得当前编码块的K个最近邻像素块。由于搜索过程非常耗时,因此,本文中限定了搜索范围来降低搜索过程计算复杂度。图 3中给出了在相邻的左视点、上视点以及左上视点中指定的搜索范围。假设虚拟绘制视点的宽度及高度分别为Wview与Hview,当前编码块的坐标为(cx, cy)。相邻视点图像中,与当前编码块相对应的像素块坐标如图 3所示。根据相邻视点图像中对应的像素块坐标,在相邻左视点中的搜索范围为水平方向2H的范围,在相邻上视点中的索索范围为垂直方向上2V的范围,在左上视点中的搜索范围是V×H的范围。
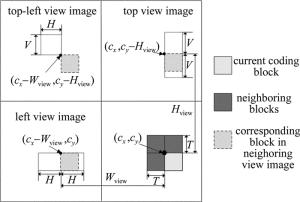
Figure 3. The specified searching range
在获取当前编码块的K个最近邻像素块后,将利用线性加权算法得到当前编码块的最佳预测。假设获取的当前编码块x0的K个最近邻像素块用矢量X={xk|k=1, 2, …, K}表示,像素块y0的K个最近邻像素块用矢量Y={yk|k=1, 2, …, K}表示。线性加权预测过程可以表示为:
式中,矢量$ {\mathit{\boldsymbol{\hat x}}_0}$为当前编码块x0的预测向量,矢量ωk为加权矢量系数。
为了获取加权矢量系数ωk,本文中充分考虑到矢量x0与矢量y0的相关性,利用y0及其K个最近邻像素块Y来近似估计ωk。估计过程可以表示为:
式中,$ {{{\mathit{\boldsymbol{\hat \omega }}}_k}}$为加权矢量系数ωk的近似值,将作为加权矢量用于当前编码块的线性加权预测。
-
对于纹理复杂区域,由于当前编码块x0与其相邻的像素块y0的相关性较低,利用线性加权预测算法很难获得较高的预测精度。因此,本文中提出利用帧内块拷贝预测算法来提高纹理复杂区域的预测精度。与线性加权预测算法不同,帧内块拷贝算法利用当前编码块的原始像素值在已知的编码重建区域中进行搜索,获得当前编码块的最佳预测。记录下当前编码块与最佳预测块之间的位移矢量。然后将记录的位移矢量传输到解码端,以辅助解码端根据位移矢量获取当前编码块的最佳预测像素块。本文中位移矢量的搜索范围设定为所有已知编码重建区域。搜索过程如图 4所示。
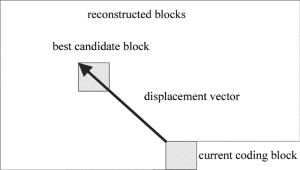
Figure 4. The searching process of intra block copy
-
由于HEVC-SCC平台中嵌入了帧间块拷贝预测模式,因此本文中选择将所提预测算法集成到HEVC-SCC平台上。为了避免修改比特流结构,本文中提出将所提的线性加权预测算法替换HEVC-SCC帧内编码提供的35种角度预测模式中的任意一种预测模式。换言之,所提线性加权预测算法获得的当前编码块的预测值将替换利用某一角度预测模式获得的编码块的预测值。
HEVC-SCC帧内编码提供了灵活的四叉树编码结构,支持编码树单元(coding tree unit, CTU)最大到64pixel×64pixel的扩展。CTU又可以进一步根据四叉树结构划分为更小的编码单元(coding unit, CU)。预测单元(prediction unit, PU)可以通过CU分割得到,是编码块预测的基本单元,支持4pixel×4pixel到64pixel×64pixel的块尺寸扩展。但是由于光场图像内容纹理复杂度要远高于自然2-D图像,编码器很少选择64pixel×64pixel作为PU块尺寸。因此,只选择4pixel×4pixel到32pixel×32pixel的PU尺寸扩展,以降低部分算法复杂度。
为了在帧内角度预测模式、线性加权预测模式以及帧内块拷贝模式中选择PU的最优预测模式及最佳块尺寸,采用率失真优化过程作为衡量标准。率失真优化表示为:
式中,J*表示率失真代价,Jm表示块尺寸为d、预测模式为p情况下的率失真代价。D∈{0, 1, 2, 3}表示PU从32pixel×32pixel到4pixel×4pixel的块尺寸,P表示所有的候选预测模式。Sl与Sc分别表示当前PU亮度和色度与在块尺寸d、预测模式为p情况下预测重建块的亮度与色度值之间的失真。ωc为色度部分的加权系数,λm为拉格朗日乘子,Rm表示编码当前PU所需要的比特数。
本文中所提的视点阵列图编码算法采用遍历PU所有的块尺寸以及所有的预测模式的方式来提高编码块的预测精度。其中,预测模式主要包括帧内角度预测模式、线性加权预测模式以及帧内块拷贝模式。所提算法可以在确保编码图像虚拟质量的同时,进一步提升视点阵列图的编码效率。
2.1. 线性加权预测算法
2.2. 帧内块拷贝预测算法

2.3. 所提预测算法在HEVC-SCC平台上的集成
-
实验中以HEVC-SCC参考软件SCM-3.0[20]为测试平台,聚焦光场图像bike, fountain, Laura以及seagull作为测试集。测试聚焦光场图像原始分辨率为7240pixel×5432pixel,子图像分辨率为75pixel×75pixel。由于子图像边缘存在光晕现象[18],因此在实验过程中将每个子图像在中心位置处裁剪64pixel×64pixel大小的像素块,拼接成新的光场图像作为实验测试序列。所有测试序列均转化为YUV为4:2:0的形式送入编码器进行压缩编码。实验中编码器配置文件设置为“all intra”[21],4个量化参量(quantization parameter,QP)设置为22, 27, 32及37。为了验证本文中算法的有效性,将其与4个编码算法进行对比:原始HEVC编码算法(HEVC)、集成了IBC的HEVC扩展参考软件HEVC-RExt 6.0[22](HEVC-RExt)、参考文献[19]中提出的视差补偿预测算法(disparity compensation coding method, DCCM)以及HEVC屏幕扩展编码标准[23](HEVC-SCC)。经典的BD峰值信噪比(BJONTEGAARD delta peak signal-to-noise ratio, BD-PSNR)以及BD-rate将作为评价标准来衡量算法的编码效率。
视点提取过程中,提取块大小设置为8pixel×8pixel。当前编码块最近邻像素块搜索过程中,厚度T设置为当前编码块的尺寸,且在相邻视点图像中分别搜索3个与当前编码块最相近的像素块来预测编码块。实验过程中,所提线性加权算法将替换帧内角度预测模式4来嵌入HEVC-SCC平台。相邻视点图像中搜索范围V与H均设置为16。
表 1中给出了本文中所提算法与其它3种压缩编码算法相比于HEVC的BD-PSNR以及BD-rate对比。从表 1中可以看出,本文中所提算法可以获得最优的编码效率。相比于HEVC,本文中所提算法可以获得平均2.55dB的BD-PSNR编码增益。相比于HEVC-RExt,所提算法可以获得0.93dB的平均BD-PSNR增益。与DCCM算法相比,所提算法也可以获得0.72dB的平均BD-PSNR增益。其原因是DCCM只是利用子图像的相关性,搜索得到当前编码块的最佳预测块。但是对于纹理复杂区域,该算法的预测精度较差。HEVC-SCC相比于HEVC帧内编码,集成了新的IBC以及palette (PLT)预测模式,在编码性能上要优于HEVC, HEVC-RExt以及DCCM 3种压缩算法。本文中所提算法可以获得0.56dB的平均BD-PSNR增益。其主要原因是本文中所提算法利用率失真优化将线性加权预测算法以及IBC预测算法结合,增加了编码块的预测精度。此外,本文中所提压缩编码算法对于纹理更为复杂的光场图像可以获得更好的编码效率。例如,对于光场图像Laura来说,所提编码算法相比于HEVC-SCC,可以获得0.74dB的BD-PSNR增益。
test images compressionmethods BD-PSNR/dB BD-rate/% bike HEVC-RExt 1.35 -18.51 DCCM 1.63 -23.21 HEVC-SCC 1.69 -24.57 the proposal 2.14 -32.41 fountain HEVC-RExt 1.52 -22.11 DCCM 1.77 -26.25 HEVC-SCC 1.84 -27.33 the proposal 2.34 -36.02 Laura HEVC-RExt 1.53 -20.40 DCCM 1.69 -22.80 HEVC-SCC 1.88 -25.36 the proposal 2.62 -35.99 seagull HEVC-RExt 2.07 -31.77 DCCM 2.24 -35.32 HEVC-SCC 2.56 -39.23 the proposal 3.08 -48.89 Table 1. BD-PSNR and BD-rate performance of the proposed method and the compared compression methods to HEVC
表 2中给出了4种编码算法相比于HEVC的编码时间比率。从表 2中可以看出,本文中所提编码算法需要最多的编码时间,平均为HEVC编码时间的23.38倍。主要原因是本文中所提算法在选择最优编码块尺寸以及最优预测模式时遍历了所有的块尺寸以及所有的预测模式。这一遍历过程是非常耗时的,不过,本文中所提编码算法可以获得一个较高的编码效率。
test images HEVC-RExt DCCM HEVC-SCC the proposal bike 2.81 3.31 10.35 13.86 fountain 3.21 4.10 11.35 18.48 Laura 3.97 4.15 29.76 31.25 seagull 3.04 4.57 26.01 29.92 average 3.26 4.03 19.37 23.38 Table 2. Coding time ratios to HEVC
图 5中给出了在比特率近似0.16bit/pixel情况下,解码光场图像的虚拟绘制视点质量对比。从图 5中可以看出,所提算法相比于HEVC可以获得一个较好的虚拟绘制视点质量。其主要原因有两方面:一是所提编码算法相比于HEVC可以获得一个更高的编码块预测精度;二是所提编码算法对于纹理复杂区域可以确保编码块的细节信息。

Figure 5. Visual rendering views from the decoded light field image at bit-rate 0.16bit/pixel

-
本文中充分探索光场图像绘制视点图像之间的强相关性,提出一种基于绘制视点相关性的光场图像压缩编码算法。所提压缩编码算法结合高清视频编码屏幕编码扩展平台,利用率失真优化将线性加权算法与帧内块拷贝算法进行有机结合,进一步提升了编码块的预测精度。实验结果表明,所提编码算法相比于HEVC可以获得2.55dB的平均BD-PSNR编码增益。此外,本文中所提压缩编码算法还可以获得一个较好的虚拟绘制视点质量。
 DownLoad:
DownLoad: